DeepMind提出PathNet:通过迁移学习展望通用人工智能
通用人工智能(articial general intelligence/AGI)至今看起来仍然是遥不可及的一个技术圣杯,但这没有妨碍研究者向这个方向的努力。近日,一直研究成果不断的 DeepMind 又在 arXiv 上发布了一篇也许向这个方向迈进了一步的新论文,该论文提出了一种 PathNet,宣称能够实现某种巨型神经网络(giant neural network)。麦吉尔大学学生兼该校人工智能协会社长 Théo Szymkowiak 在 Medium 上发了一篇短文介绍了这篇论文。
自从科学家开始构建和训练神经网络以来就一直没能跨过「迁移学习(transfer learning)」的难关。迁移学习是指人工智能学习不同任务并将预学习到的知识应用于全新任务的能力。很显然,具备预先知识的人工智能将在面对新任务时比全新开发的神经网络能表现得更好、训练得更快。
也许 DeepMind 能用 PathNet 达到这一目标。PathNet 是一个由神经网络组成的网络(network of neural networks),通过随机梯度下降和遗传选择方法做训练。
PathNet 由模块构成的层组成,其中每个模块都可以是一个任意类型的神经网络——可以是卷积网络、循环网络、前馈网络等等。

图 1:一个随机初始化的路径(框图 1 中的紫色线)的集合在学习任务 A Pong 游戏的过程中进化。在训练结束时,最好的路径是固定的(框图 5 中的暗红色线),并且会有一个针对任务 B 的新的路径(框图 5 中的淡蓝色线)集合被生成出来。这个路径集合然后在 Alien 游戏上得到训练,然后在 Alien 游戏上逐渐进化,在训练结束时固定达到最佳路径,如框图 9 中的深蓝色线所示。
这 9 个框图是在不同迭代时的 PathNet。在这个案例中,PathNet 被训练用 Advantage Actor-critic(A3C)玩两个不同的游戏。尽管在一开始 Pong 和 Alien 看上去很不同,但我们确实观察到(看一下得分图)了一个使用 PathNet 的迁移学习。
它如何训练
首先,我们需要定义模块。设 L 为层数,N 为每一层的最大模块数(论文表明,N 通常是 3 或 4)。最后一层是密集的,并且不在不同任务之间共享。通过 A3C,最后一层表示价值函数(value function)和策略评估(policy evaluation)。
那些模块定义完之后,网络之中生成 P 基因型 (=路径)。由于 A3C 的异步属性,需要多个工作器(worker)评估每一个基因型。在 T 个 episode 之后,一个工作器从其他路径中选一对进行比较,如果这些路径中的一些有更好的适配,那就采用它,并用那个新路径继续训练。如果不,则工作器继续评估其路径的合适程度。
迁移学习
在学习了一个任务之后,网络会固定最优路径上的所有参数。所有其它参数将被重置,因为照论文上讲,如果不这样做,PathNet 将会在新任务中表现很差。
通过使用 A3C,用于新任务的 PathNet 上的反向传播不会修改先前任务中的最优路径。这可以看作是保存先前知识的护卫。
结果
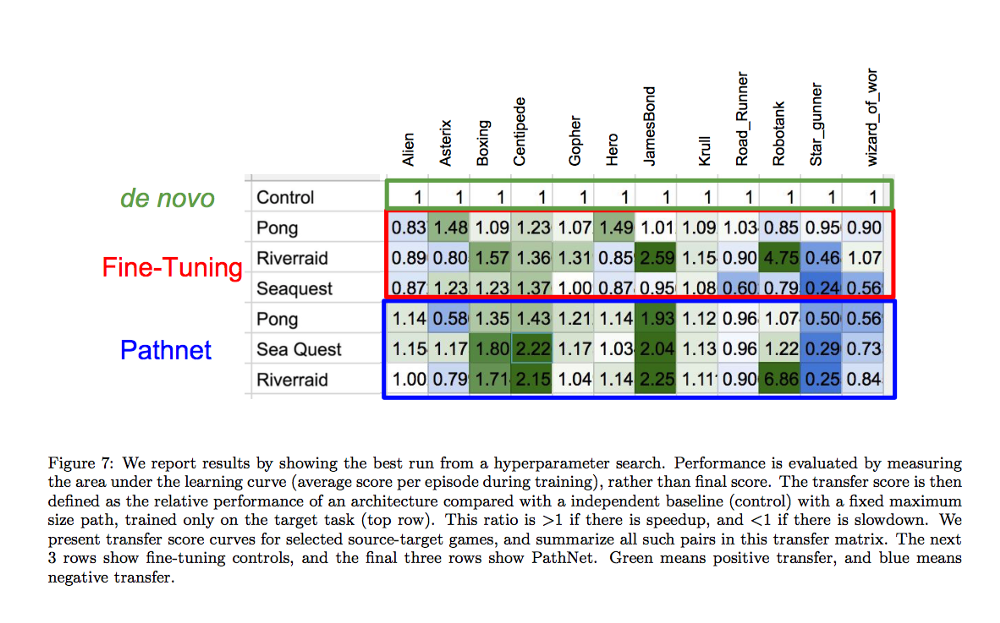
图 7:我们在超参数搜索上的最佳运行的结果。其中的表现是通过测量学习曲线下方的区域(在训练过程中每次 episode 的平均得分)而进行评估的,而不是通过最终得分。然后该迁移分数被定义为一个架构的相对表现,这是与一个带有一个固定最大尺寸路径的独立基线(控制量/control)进行比较得到的,这个基线是仅在目标任务上训练得到的(最上面一行)。当存在加速时,该比率大于 1,减速则该比率小于 1. 我们给出了在我们选择的源-目标(source-target)游戏上得到的迁移分数曲线,并在这个迁移矩阵(transfer matrix)中总结了所有的这种游戏对。接下来的 3 行显示出了 fine-tuning 控制的结果,后 3 行给出了 PathNet 的结果。绿色表示发生了正迁移(positive transfer),蓝色表示负迁移(negative transfer)。
PathNet 并不在每一对游戏上都能有效(蓝色单元格等于负迁移)。但是重要的是 PathNet 已经对一些游戏对实际有效了,我们已经踏出了迈向更好迁移学习的巨大一步。
延展思考
可以想象在将来,我们会有巨型的人工智能(giant AI),它们被训练完成数以千计的任务并且能够泛化,也就是:通用人工智能。
论文:PathNet:在超级神经网络中的进化通道梯度下降(PathNet: Evolution Channels Gradient Descent in Super Neural Networks)

摘要
如果多个用户训练同一个巨型神经网络(giant neural network),同时允许参数复用,并且不会遗忘太多东西,则这对通用人工智能而言将是高效的。PathNet 是在这个方向上迈出的第一步。它是一个将代理嵌入到神经网络中的神经网络算法,其中代理的任务是为新任务发现网络中可以复用的部分。代理是网络之中的路径(称为 views),其决定了通过反向传播算法的前向和后向通过而被使用和更新的参数的子集。在学习过程中,锦标赛选择遗传算法(tournament selection genetic algorithm)被用于选择用于复制和突变的神经网络的路径。路径适配(pathway fitness)即是通过成本函数来度量的自身的表现。我们实现了成功的迁移学习;固定了从任务 A 中学习的路径的参数,并据此再进化出了用于任务 B 的新路径,这样任务 B 要比从头开始或 fine-tuning 学习得更快。任务 B 中进化的路径会复用任务 A 中进化出的最优路径的一些部分。在二元的 MNIST、CIFAR 和 SVHN 监督学习分类任务和一系列的 Atari、Labyrinth 强化学习任务上,我们都实现了正迁移,这表明 PathNet 在训练神经网络上具有通用性应用能力。最后,PathNet 也可以显著提高一个平行异步强化学习算法(A3C)的超参数选择的稳健性。
正文到此结束
热门推荐










相关文章




Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

