唯品会的Service Mesh三年进化史
前言
今年在Goolge的推动,和K8S社区的惯性力量下,Service Mesh的风很大。蓦然回首,唯品会的服务化体系OSP(Open Service Platform) 在三年前就走上了ServiceMesh的路,一股淡淡的自豪,和对定下基调的前老板的佩服。
每种架构风格,由于各司不同的历史因果,现实状况,以及对采纳新架构的诉求和希望,都会有不同的实现路线。我们的SM在实战中一点点演化而来,与 Istio由谷歌IBM的超级架构师们画出来的架构也有不同之处。希望通过分享我们的演进过程,能给各司里同样在往SM演进中的架构师们一个参考。
SM演进史
一、标准服务化体系阶段
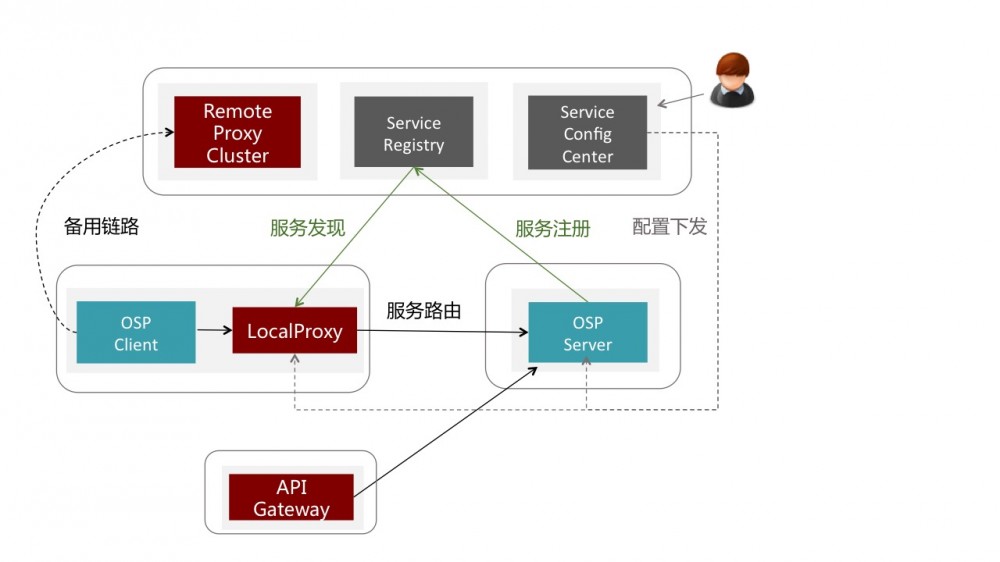
如果用两根手指将Local Proxy 和 Remote Proxy的框框按住,就是个标准的服务化框架。
传输与序列化层
当时还没有GRPC,自己拿Netty撸了一个TCP长连接,多路复用,异步IO的传输层,基于Thrift协议的序列化。
当然,这个组合从性能上现在看也不过时,自定义TCP不比HTTP2弱, Thrift 也比ProtocolBuffer略快,我们还支持基于Java类来定义Thrift接口,而不是原生Thrift,PB的有额外学习成本的中立语言,完美。
缺点嘛,就是跨语言时会略尴尬,虽然原生的Thrift也在某种程度上跨语言,但我们除了保留Thrift序列化协议外,其他从头到脚都重新实现了,也就不再能从它那借力。
服务注册中心
当时的大环境下,ZooKeeper也是比较流行的注册中心选择,不过最近在做去ZK化,改为自研的Http Api Server,数据用Redis或 Etcd存储。
API网关
当然要有入口网关,将外网的HTTP请求,经过认证,安全防刷, 再转换为OSP调用后端服务。
服务路由
服务的注册发现,负载均衡,路由定制,机房策略等路由策略,超时,重试,熔断等可用性策略,我们统称为路由逻辑。
我司的主力语言,前端是PHP 和 Java,后端是Java,在调用端有着硬性的跨语言需求。
SM第一步
上述的路由逻辑,如果在每种语言实现一次客户端,显然是不合算的。为了PHP,将这些逻辑抽取成独立的Proxy。
SM第二步
这个独立的Proxy,是部署成传统的集中式的Proxy集群,还是当时还不很著名的本地SideCar模式呢?
在公司的体量下,有着强烈的去中心化的愿望,所以我们选了SideCar模式。
SM第三步
PHP使用了Proxy,那Java呢,继续像dubbo一样在客户端里可以吗?
这个当时有比较大的争议,因为毕竟多经过了一层节点,虽然本地连接不经过网络,也很难说性能毫无影响。 为此我们还专门做了个基于Unix Domain Socket的版本,但后来觉得性能足够,一直没上线。
最后,老板力排众议,一是为了架构统一性,二是因为我们的Proxy功能还不成熟,而使用它的应用又特别多,如果不独立出来,很难推动快速升级。所以统一使用了Proxy模式。
SM第四步
SideCar模式虽好,但是存在单点的问题,如果SideCar在升级,或者挂掉了怎么办?
SideCar升级,可以联动同一台机上的应用先摘除流量。
SideCar挂掉,可以搞个脚本把它自动重新拉起。但重新拉起的间隔里还是会丢失的请求,如果重新拉起还是失败呢?
作为一个架构师,高可用的观念是深入到骨子里的,所以我们又在每个机房搭建了一个Remote Proxy集群,并在客户端里的SDK加入了如下的逻辑:
“如果本地Proxy不可用或宣称自己准备关闭,就将请求无损转发到Remote Proxy,再启动一个监视器观察本地Proxy什么时候重新可用。”
至此,一个封闭的服务化框架完备了,我们有了标准的服务化体系。能力上,也比当时久不更新的Dubbo,还有后来的Netflix,SpringCloud要强不少。
二,按不住的多语言的客户端接入
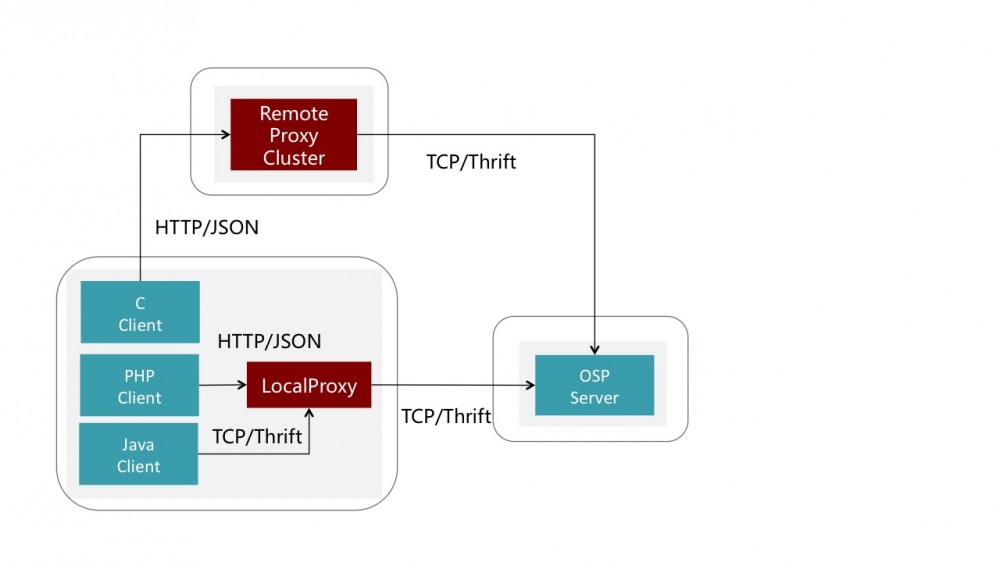
时间匆匆过, 一个公司里,总是按不住会有更多的语言出现,比如Node.js, C++, Go,像前面说的,再撸一次TCP/Thrift 感觉有点累了,这些也不是主流语言,花太多时间在上面不值得。 所以,我们在Proxy上额外支持了HTTP/JSON的传输层,再根据注册中心里的元数据,重新序列化成Thrift来调用后端服务就好了。
我们还发现,在PHP里用Thrift,还不如它内置的C写的HTTP/JSON库快。
不过,我们也不想在这些客户端再实现一次本地SideCar与Remote Proxy的切换逻辑了,反正这些非主流语言的客户端的调用量不会很大,就通通去调用Remote Proxy集群好了。哪天撑不住时,可能会改用前面说的不那么完美的方案。
至此,多语言的客户端完全咩有接入限制了。
三, 普通Web应用也想零成本变身服务化
时间又匆匆过,又有大量原来的Web应用,不想改造成OSP应用,又想作为一个服务,或者接入API网关,或者加入服务化大家庭,享受各种服务治理的能力。
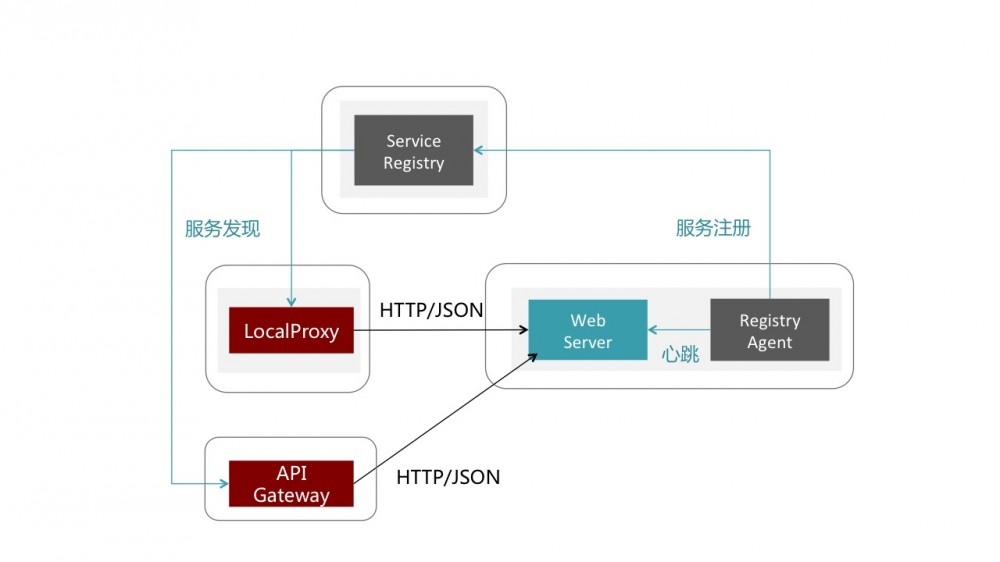
为此,我们开发了一个很轻量的注册器,也是以sidecar的形式运行,不断的对Web应用的做健康检查,与注册中心进行注册,心跳,和反注册。
当然,免费的午餐肯定没那么好吃,比如没有了基于IDL生成SDK的与客户端的契约化编程,没有了高效的传输层序列化层,没有了限流,自动隔离线程池,ClassLoader预热,闲时主动GC等等细微的Runtime加强。
至此,多语言的服务端也完全咩有问题了。
四、容器化了,容器化了
为了容器化,sidecar跑在哪里,又成了问题。 如果跑在每一个Pod里,一来呢,身为Java应用,堆内堆外内存吃得有点多;二来呢,升级Proxy时,又要重新发布每一个应用;
所以,我们选择了DaemonSet的形式,每台宿主机上只运行一个Proxy,Proxy启动时把自己的IP写在一个共享文件里,这个文件也Mount进各个容器里面,各个客户端会监听这个文件。
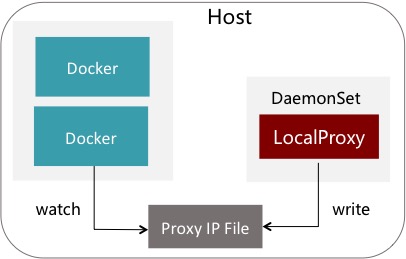
为了隔离性,Proxy加了个来源IP的限流,效果就是单个容器的调用高于2万QPS时,第二万零一个请求开始就把它临时重定向到Remote Proxy集群。 十秒钟后再重试本地Proxy,如果还是高,又继续打发过去。
另一个改动,我们之前基于IP来定义路由规则( 比如把一些消耗较大的接口,都发送到隔离的三台机器上)。容器里IP不固定了怎么办?
我们引入了一个部署池的概念,比如一个应用有两个部署池,一个3台机器,另一个20台机器,这个部署池的名字,会注册为服务实例的元信息。在服务路由里就用这个池的名字来定义规则。
Istio 的区别
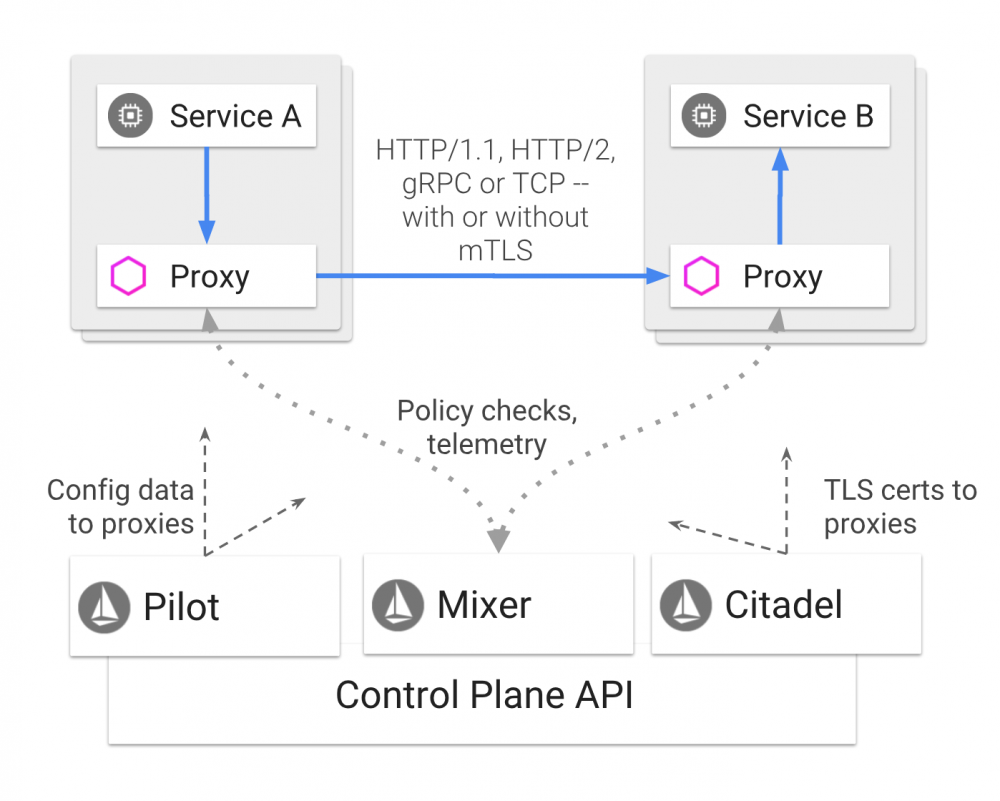
1. Server端无入口Agent
Server端前面也摆一个Agent,全部流量都流经它,有点重。
如果已经是OSP应用,当然没必要摆这个Agent了。如果是一个希望零成本变身的Web应用,那我们回顾一下服务端要做的事情:
一是服务注册和心跳。 我们在应用旁边摆了个轻量级的注册与心跳器来实现。
二是分布式调用链记录。分布式调用链监控原本就支持Web应用呀,不需要额外的Agent。
三是服务端授权,服务端限流之类必须在服务端进行的服务治理,相对没那么重要与常用,真的需要要时同样以Servlet WebFilter 或多语言SDK包方式提供。
所以,这个偏重的Agent暂时没有太大必要。
2. Client端不基于IPTable劫持
为了客户端零改造成本,Istio里基于IPTable,将Client发出的所有请求劫持到Proxy上。但IPTable的性能一般,尤其是一个环境里有很多应用时,性能更加跌得很厉害。所以我们就不节约客户端的一点点改造成本了。
基于SDK访问支持Local Proxy与Remote Proxy的完美切换,比IPTable的方案更加的高可用。
但如果某种语不想写这种复杂SDK,要么全部打到本地Proxy(等于IPTable),要么全部直接访问 Remote Proxy集群。
3. 没有画大饼用的Mixer
为了Proxy的可替换性,Istio里将与基础设施相关的部分都提取到中央的Mixer里,比如分布式调用链跟踪都分离出来这个太那啥了,一个是性能,一个是中央化基础设施的容量限制。 虽然理解Google架构师们为了画大饼的无奈,但自用体系,不需要考虑Proxy的可替换性时,还是把该下沉到Proxy的下沉下去。
4. SideCar以DaemonSet形式运行
因为是Java,堆内堆外要3G左右,所以每台宿主机只运行一个Proxy。 如果内存足够,闭上眼睛把它打进Pod里也可以的,不是原则性的问题。
5. 完全不依赖K8S和容器技术
这么一路走来,当然不会依赖于K8S。目前Istio们为了节约开发精力而完全依赖K8S,其实也大大局限了它们的适用范围。
6. 路由和路由是不一样的,熔断和熔断是不一样的
一个词能涵盖完全不同级别的实现。大家都说路由,但比如Dubbo,比如OSP,才算是真正的规则路由。其他负载均衡,熔断,重试等等,也可以做得很不同。
正文到此结束
- 本文标签: IDE HTML client IO Netflix PHP remote redis TCP Java类 ORM springcloud 限流 web IBM 负载均衡 数据 时间 dubbo Service 高可用 Agent java tab 家庭 需求 开发 线程池 分布式 QPS spring unix js UI Node.js 谷歌 免费 id Proxy 认证 https zookeeper Google json http 服务端 架构师 定制 ip 安全 Netty 实例 主机 希望 服务注册 协议 servlet 集群 API DOM src 长连接 注册中心 ssl node 线程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
搞个gitee的项目
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

