Java全文搜索引擎—Solr
全文检索
倒排索引
根据文档创建索引,再对索引进行查询获取文档。
相比与顺序查询:不需要那么多的查询(一个文档一个文档找索引,找到就匹配,需要全部查询,效率很低),而且可以在索引上定位,出现在哪个文档哪个地方,支持高亮
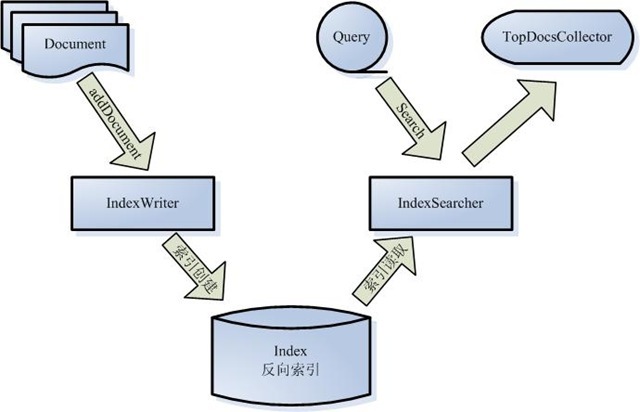
Lucene
Lucene是一个基于Java的全文检索库,可以看成一个持久层框架,与Lucene索引交互
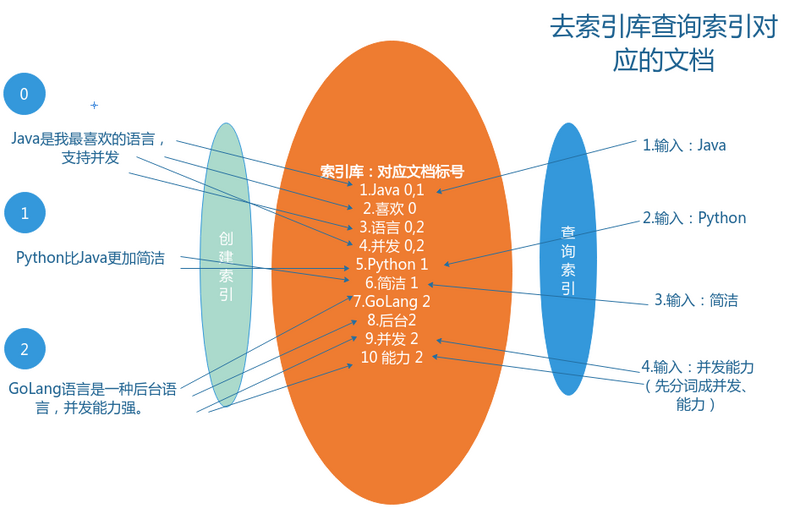
倒排索引存储信息
左边保存的是一系列字符串,称为 词典 。
每个字符串都指向包含此字符串的文档(Document)链表(每个节点还包含文档中出现该索引的频率),此文档链表称为 倒排表 (Posting List)。

如果我们需要查询包含两个索引的文档,只需要将两个文档共有的文档标号连接成链表
索引创建
- 对文档进行分词,使用Tokenizer ,得到
词元
分词器一般使用训练的模型, Word 、 IK 等
- 去除标点
- 去除停用词(我、是)
- 还需要把词元传递给语言处理器组件处理
英文:复数->单数,大写->小写
- 若索引库存在相同索引,需要合并成一个链表
索引查询
- 输入查询关键字词
keyword:Java
- 进行语法分析得到一棵语法分析树
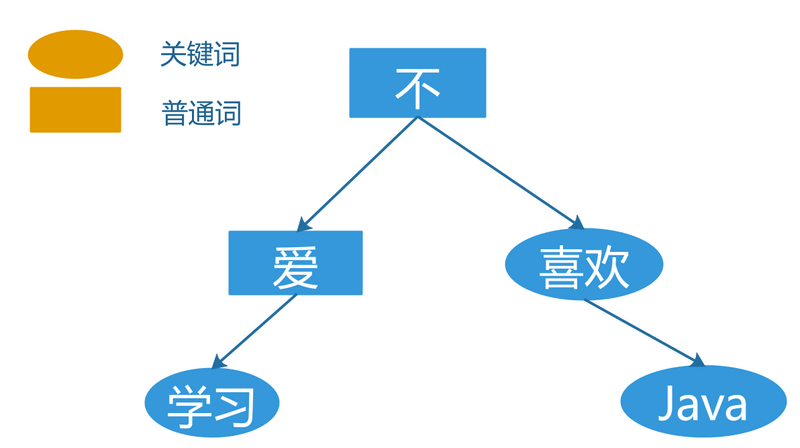
- 搜索索引库,得到符合的文档以及索引的信息
- 得到文档后,根据频率,相关性排序,分数越高的排在越前面
过程
1. 索引过程:
1) 有一系列被索引文件
2) 被索引文件经过语法分析和语言处理形成一系列词(Term) 。
3) 经过索引创建形成词典和反向索引表。
4) 通过索引存储将索引写入硬盘。
2. 搜索过程:
a) 用户输入查询语句。
b) 对查询语句经过语法分析和语言分析得到一系列词(Term) 。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term) 的文档链表,对文档链表进行交,差,并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。
Solr
Solr是Lucene的封装,提供分布式索引,负载均衡查询,配置式使用,基本只支持Java
solr create -c “name” http://localhost:8983/solr
配置
- managed-schema
在其中配置core的field字段、分词器等
name:数据库字段,type:类型,indexed:是否索引,stored:是否缓存,required:是否必须,multiValued:是否多值
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- 数据库字段 -->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="shoes_name" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="price" type="string" indexed="false" stored="true" multiValued="false"/>
<field name="details" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="url" type="string" indexed="false" stored="true" multiValued="false"/>
<field name="pic_url" type="string" indexed="false" stored="true" multiValued="false"/>
- solrconfig.xml
当你需要使用web客户端dataimport时,需要添加:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
- 在统计目录下创建一个data-config.xml,建立数据库字段和core field映射
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/priceCompare_goods" user="dzou" password="1234"/>
<document>
<entity name="adidas_goods" transformer="DateFormatTransformer" query="SELECT id,shoes_name,details,pic_url,price,url,store_name,comment,shoes_kind FROM adidas_goods">
<field column="id" name="id"/>
<field column="shoes_name" name="shoes_name"/>
<field column="price" name="price"/>
<field column="details" name="details"/>
<field column="url" name="url"/>
<field column="pic_url" name="pic_url"/>
<field column="shoes_kind" name="shoes_kind"/>
<field column="store_name" name="store_name"/>
<field column="score" name="score">
</entity>
</document>
</dataConfig>
SolrClient API调用
- 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
- 添加记录到core
@RequestMapping("/add")
public String add() throws IOException, SolrServerException {
SolrInputDocument doc = new SolrInputDocument();
doc.setField();
doc.setField();
doc.setField();
solrClient.add("",doc);
solrClient.commit("");
return "";
}
- 删除core记录
@RequestMapping("/delete")
public String delete(String id) throws IOException, SolrServerException {
solrClient.deleteById(id);
solrClient.commit("");
return "";
}
/**
* 删除所有的索引
* @return
*/
@RequestMapping("deleteAll")
public String deleteAll(){
try {
solrClient.deleteByQuery("","*:*");
solrClient.commit("");
return "success";
} catch (Exception e) {
e.printStackTrace();
}
return "error";
}
- 更新记录
Map<String, String> map = new HashMap<>();
map.put("set", o.getScore());
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", o.getId());
doc.addField("score", map);
solrClient.add("am_goods", doc);
solrClient.commit("am_goods");
- 查询记录
/**
* 根据id查询索引
* @return
* @throws Exception
*/
@RequestMapping("getById")
public String getById() throws Exception {
SolrDocument document = solrClient.getById("collection1", "536563");
System.out.println(document);
return document.toString();
}
/**
* 综合查询: 在综合查询中, 有按条件查询, 条件过滤, 排序, 分页, 高亮显示, 获取部分域信息
* @return
*/
@RequestMapping("search/{keyword}")
public String search(@PathVariable("keyword")String keyword){
try {
SolrQuery params = new SolrQuery();
//查询条件, 这里的 q 对应 下面图片标红的地方
params.set("q", "shoes_name:"+keyword);
//过滤条件
//params.set("fq", "product_price:[100 TO 100000]");
//排序
params.addSort("price", SolrQuery.ORDER.asc);
//分页
params.setStart(0);
params.setRows(20);
//默认域
params.set("df", "shoes_name");
//只查询指定域
//params.set("fl", "id,shoes_name,shoes_kind,shop_name");
//高亮
//打开开关
params.setHighlight(true);
//指定高亮域
params.addHighlightField("shoes_name");
//设置前缀
params.setHighlightSimplePre("<span style='color:red'>");
//设置后缀
params.setHighlightSimplePost("</span>");
QueryResponse queryResponse = solrClient.query(params);
/*SolrDocumentList results = queryResponse.getResults();
results.forEach(System.out::println);*/
List<HupuGoods> s = queryResponse.getBeans(HupuGoods.class);
return s.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
ES和Solr区别
- Solr是配置式,ES是基于RestFul的
- ES除了搜索还可以处理分析查询
- Solr更面向文本搜索,对于已有数据的查询Solr更快
- ES更轻量,发展很快,使用量已经超越Solr
正文到此结束
- 本文标签: SolrServer 负载均衡 ORM UI 索引 key client apache 删除 cat id CTO 分页 solrconfig.xml https bean 配置 HashMap XML collection1 java http 数据库 Collection API REST core db 处理器 map token Select spring schema 统计 tar IO RESTful 缓存 list entity remote ACE sql 模型 Document 目录 solr SolrQuery 图片 数据 JDBC value src web Word 搜索引擎 分布式 App mysql dataSource
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

