京东商详前台系统优化实践
写在前面
商品详情页又名单品页,是京东商城购物主流程之一。商品详情页作为用户了解商品信息的主要页面,有上百种业务场景,并且展示层面要求个性化场景较多,同时承载着京东购物主流程最大的访问量,再加上电商共同的特点,秒杀类场景居多,尤其以618和双11 更为突出。这样就对商详系统的性能提出了很高的要求,今年公司提出的降本提效的战略,以前一直扩机器的模式显然已经不可持续。在这个大背景下,我们开始对系统性能做针对性的提升优化,下面的介绍希望读者可以对商详有一个全面的了解。
商详系统技术架构介绍
0 1
商详整体架构图
-
商详系统做为承上启下的系统,承接着客户端商品页过来的所有流量,再调用中台各个业务系统获取信息。
-
业务角度商详业务主要分为以下场景:优惠券场景,用户信息场景,价格信息场景,促销场景,商品与扩展信息场景,库存与履约场景。
-
结构上来讲 整个商详业务分为 客户端,前台,中台,后台。这里主要介绍的系统为商详前台系统。

0 2
系统组件图
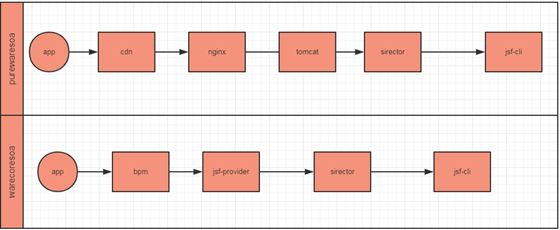
目前商详系统由于历史原因分为purewaresoa,warecoresoa 两个系统。 首先看一下目 前的两个系统的调用流程:
-
purewaresoa 是商详老系统,整体提供http服务,流程为流量从app客户端过来,然后过nginx ,如果是静态资源的话 会走cdn缓存,然后到tomcat, 系统内部为sirector(公司自研的并发流程编排框架)流程编排,然后到jsf 客户端调用jsf 服务获取业务信息。
-
warecoresoa 系统为商详新系统,提供jsf 服务给容器(提供楼层样式配置化支持的系统)调用最终组合成楼层信息给客户端用,所以流量会先过容器再到warecoresoa ,系统内部通过sirector 流程编排调用jsf 服务 获取业务信息。
0 3
系统分析
因为随着系统的发展warecore 所占的比重会越来越大,所以以下分析主要针对warecoresoa 系统。
系统内存分析
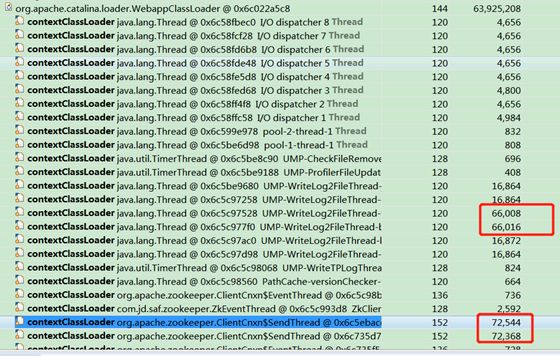
-
java内存分析一般采用Java jmap dump下系统内存文件 使用mat 进行分析,上图是一台机器内存报警时dump下来的内存文件。经过分析发现系统内存占用主要集中在两块,1. zk 本地缓存 2.ump 统计 。
系统线程分析
线程栈一般通过jstack 得到,或者使用京东工具jvm.jd.com 连接上对应机器导出java进程所有的线程,以下为warecore整理过后的所有线程(线程数量非最终线程数量)
{
"taskProcessorThreadPool": 10, //队列线程
"nioEventLoopGroup": 10, //netty 对应线程
"userTracerWorker": 100, //ump 线程
"Jst": 7,
"BrokenConnectionDestroyer": 2,
"SystemClock": 1,
"pool": 331,{
"pool-10":200, //sirector 线程
"pool-4":128, //jimdb 连接线程池
"pool-3":1,
"pool-2":1,
"pool-1":1
}
"JSF": 699,
{
"JSF-CLI-WORKER": 9,
"JSF-SEV-BOSS": 1,
"JSF-CLI-RC": 156, //客户端线程
"JSF-SEV-WORKER": 2, //jsf io线程池
"JSF-Future-Checker": 2,
"JSF-jsfRegistry-HB&Retry": 1,
"JSF-BZ-22000": 215, //业务线程池
"JSF-CLI-CANDIDATE": 156, //客户端线程
"JSF-CLI-HB": 155, //客户端线程
"JSF-FileRegistry-Back": 1,
"JSF-jsfRegistry-Check": 1
}
"UpdateProfile": 1,
"ContainerBackgroundProcessor[StandardEngine[Catalina]]": 1,
"CfsHeartbeat": 6, //jimdb 心跳线程
"main": 1,
"commons": 1,
"CLIENT_SIDE_RINGBUFFER": 1,
"Reference Handler": 1,
"Finalizer": 1,
"localhost": 6, //tomcat 线程
"ZkClient": 3,
"I/O dispatcher 2": 1,
"PathCache": 1,
"IoLoopGroup ": 4,
"I/O dispatcher 3": 1,
"I/O dispatcher 4": 1,
"I/O dispatcher 5": 1,
"I/O dispatcher 6": 1,
"I/O dispatcher 7": 1,
"I/O dispatcher 8": 1,
"GC Daemon": 1,
"RMI TCP Connection(2)": 1,
"Signal Dispatcher": 1,
"FailoverEvent": 8,
"RMI Scheduler(0)": 1,
"Thread": 1,
"System_Clock": 1,
"NioBlockingSelector.BlockPoller": 1,
"http": 3,
"UMP": 11,
"JMX server connection timeout 36": 1,
"ClearTimeout": 1,
"ClusterManager": 1,
"UpdateCluster": 1,
"ChannelEvent": 8,
"I/O dispatcher 1": 1,
"RMI TCP Accept": 3
}
通过以上分析能得出结论,jsf 线程池,sirector线程池,jimdb线程池,ump线程池等线程池所占比例最大,所以后续调整也主要针对这几个线程池大小进行调整。
系统cpu分析
随着计算机的发展,cpu 逐渐成了系统性能的主要瓶颈,所以也诞生了各种各样的针对cpu 的分析工具,这里主要用了 火焰图和arthas 来进行分析
-
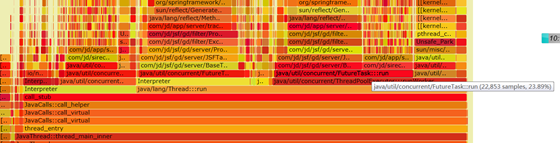
火焰图
-
arthas -- 按cpu 统计
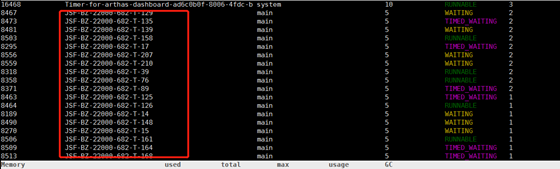
图一火焰图能看到系统内部各个环节的cpu 占比,图二是按cpu 耗损占比排名线程。
性能优化
商详系统优化历程:
以下3个阶段划分属于时间点划分
0 1
阶段1
-
并行化
-
动静分离
-
cdn加速
-
lua静态化
-
垃圾收集器
Tomcat nio
0 2
阶段2
-
jdk8 tomcat8
-
线程池调优
-
堆内存调优
-
本地缓存命中率
-
热点方法缓存覆盖率
分布式缓存命中率
0 3
阶段3
-
异步化(io异步,日志异步,懒加载)
-
业务重构(重构,上移下沉,降级)
阶段1 展示了商详老系统的优化历程,首先当然就是并行化的改造,商详系统后端对应着一百多个业务,挨个串行调用的话,几乎无法完成给用户的响应。这样就需要进行并行化改造,并行改造使用了公司的并发编排框架 sirector , 再后来随着流量的增加,为了减少不必要的网络流量,进行了动静态分离改造,就是现在用的动态接口和静态接口。静态接口除了本地缓存,jimdb外为了减少网络传输将部分缓存提前到了cdn处,之后又加了lua 缓存,此次jdk方面的调整主要集中在垃圾回收器的选择以及一些jvm的调优上,tomcat 则是主要调整了io异步化
阶段2首先调整的是jdk. 由于历史原因 jdk一直用的jdk6,jdk8在性能方面做了很多优化,第一步先是进行了jdk8,tomcat8的升级,调完之后qps有了较明显的提升,之后通过对系统线程分析发现线程存在一些问题,对线程池进行了调整,之后压测过程中发现ygc较多为了减少ygc 次数,对堆内存进行了调整,也为之后本地缓存命中率的调整打下了基础,之后又针对热点方法和分布式缓存命中率做了相应的优化调整。
阶段3是一个长期的过程,涉及到代码层面的改造,所以需要慎之又慎。目前我们只做了一些,包括一些正在做的有推荐,排行榜异步化改造,价格促销合并,主图中台缓存共享等,还有一些下线业务梳理清理,缓存梳理下线等。
工具
工欲善其事,必先利其器
性能调优主要是工具的使用
公司内部
首先当然是公司内部工具的使用,如下:
-
forcebot
-
mdc
ump
-
visual
开源工具集
Linux 系统工具
以上是linux 调优大神整理的工具集
当然还会用到一些jdk 自带的命令,如 jps jstat,jmap,jstack. 等等。
0 4
示例
线程池相关
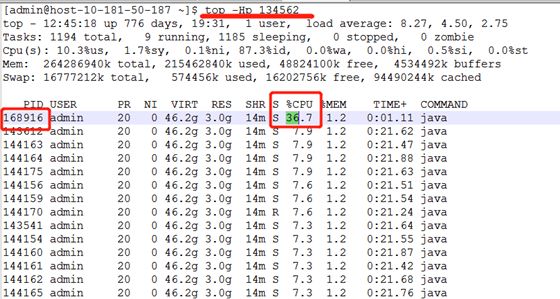
sirector线程池调整的时候发现一个现象cpu 在刚开始压测的时候第一行会有一个cpu 一直涨,查看jstack 发现sirector 线程数一直在涨,查看了配置发现线程池核心线程数不等于最大线程数,当线程不够用的时候,系统会开始创建线程,创建线程是个极为消耗性能的操作,所以这里会显示cpu 持续升高,调整线程池为固定线程数之后再没出现这种情况。
火焰图相关


火焰图是分析cpu 性能的绝佳神器,可以深入到系统的每一行代码进行cpu 性能分析,这里只是简单的列举了两个例子,第一个是序列化的例子 从图中和明显能看到gson 反序列化比较耗cpu. 第二个是抛异常的场景,明显能看到异常由于异常表的存在占用cpu 比较严重。
写在最后
性能的话题从一开始就是复杂的,性能调优没有止境,随着数据快速增长、业务不断创新、性能问题也会伴随着新的问题而来,希望后续多学习系统底层知识,丰富自己的知识体系,多积累调优经验,持续为系统做出贡献。
正文到此结束
- 本文标签: http IO JVM linux https 京东 代码 性能问题 ask NIO Lua tomcat 双11 Netty final 统计 cache ForceBot heartbeat cat SOA Select 线程池 性能优化 并发 db 进程 IDE HTML core 神器 分布式 覆盖率 Nginx 线程 数据 App src ACE id retry update UI CTO client jstack 希望 QPS java CDN 配置 TCP Connection 排名 垃圾回收 缓存 rmi js map 时间 开源
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
666
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
-
-
-
-
-
-
-
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

