如何基于K8s管理1600个微服务?某数字化银行秘诀公开
Cloud Foundry Foundation宣布KubeCF为新孵化项目
Cloud Foundry
Foundation是开放源代码项目的聚集地,简化了开发人员的体验,近日其宣布,KubeCF已成为该基金会的孵化项目,并已发布版本1.0.1。KubeCF是Cloud Foundry应用程序运行时(CFAR)的开源发行版,旨在Kubernetes上运行。该发行版与Project
Quarks的cf-operator一起使用,以部署和管理从cf-deployment构建的发行版,并且可以使用Project
Eirini的工作配置为使用Kubernetes作为底层容器调度程序。
SUSE工程与创新总裁Thomas Di Giacomo表示:“我们很高兴将KubeCF项目与Cloud Foundry
Foundation进行孵化,并很高兴获得Runtime PMC和Cloud Foundry Kubernetes
SIG的支持和反馈。现在,在社区治理之下,Cloud
Foundry贡献者所在社区可以更轻松地推进KubeCF项目,从而确保这项重要技术以对所有人都最有用的方式发展。”
SUSE已将KubeCF捐赠给基金会,该基金会已将其产品化并商业化。在SAP、IBM、SUSE在2017年欧洲Cloud
Foundry峰会上进行讨论之后,启动了第一个上游“ Containerizing Cloud
Foundry”计划。这导致创建了Eirini,用于在Kubernetes上调度用户应用程序,并创建了Quarks以在Kubernetes上部署和管理BOSH版本。
Cloud Foundry基金会首席技术官Chip
Childers说:“在该计划起草之后,我们注意到缺少一个关键组件;为Kubernetes分发CFAR,有了KubeCF,我们能够通过建立一个CFAR所有组件的集合,再整合到一个发行版中的存储库来填补空白。我们很高兴KubeCF作为一个孵化项目加入并在未来继续保持发展。”
现在希望在Kubernetes上使用Cloud
Foundry的开源用户现在可以从KubeCF获得它。它提供了完整的CFAR经验,通过了验收测试,并将很快支持至少两个经过认证的商业版本。Cloud
Foundry是一种开放源代码技术,由包括SUSE和VMware等在内的世界上最大的技术公司提供支持,并且被制造,电信和金融服务领域的领导者所采用。Cloud
Foundry能连续交付应用程序所需的速度。 Cloud Foundry的基于容器的体系结构可在您选择的云上以任何语言运行应用程序-Amazon Web
Services(AWS),Google Cloud Platform(GCP),IBM Cloud,Microsoft
Azure,OpenStack,VMware vSphere等。凭借强大的服务生态系统和与现有技术的简单集成,Cloud
Foundry是面向全球组织的关键任务应用程序的现代标准。
如何基于K8s管理1600个微服务?英国当红数字化银行秘诀大公开
日前,英国数字化银行Monzo两位资深工程师Matt Heath和Suhail
Patel在伦敦一场研讨会上,揭露了如何管理1,600个后端微服务的经验。这间设立超过5年的英国银行,一般金融用户超过了4百万人,去年9月更进军美国市场,目前也正在开发企业用的数字化银行服务。
Monzo所有金融服务都是透过手机App提供,也因此,他们一开始就决定建立分散式架构,而不是建置一套庞大的银行核心系统。最初先采用Mesos来建立容器丛集,在2016年时则全面换成了现在当红K8s,来打造了一个执行各种金融微服务的平台。Monzo是少数很早就开始压宝K8s的企业业者,也将基础架构搬上AWS平台,来减少运维人力。
Monzo使用了容易水平扩充的NoSQL数据库Cassandra,后端系统主要开发语言则是简洁的Go,他们的理由是,这个语言保证向下相容,所以,遇到语言改版时,例如有次新版增加了垃圾收集功能,原有程序码不用修改,直接用新版Go重新编译后即可执行,就能使用新功能来提高记忆体管理效率。
这是一家喜欢自己开发工具的公司,若有需要串接第三方系统或支付平台时,Monzo都尽可能自製开发整合机制,来提高效能,避免采用第三方整合工具,而带进了许多额外不需要的程序码,例如他们就开发了一个互动工具,来串联AWS环境和K8s环境,让开发者透过一个pull
reques指令,就可以快速进行部署或恢復旧版部署。
在微服务设计上,Monzo将每一个微服务,都跑在一个Docker容器中。容器化微服务的程序码,还分为两层,一层是所有微服务都必须内建的共用核心函式库层(Shared
Core Library
Layer),包括了RPC、Cassandra、锁定机制、Log记录机制、监控Matrics、Queuing等六大类函式库,另一层则是业务层,也就是这支微服务要放进入的程序码。
Monzo拆分微服务颗粒度的原则是,进可能地拆解到越细小的程度,他们解释,拆解得越细,可以将变动风险降到最低,例如更新单一功能,能减少对其他微服务的影响。但是,微服务颗粒度越小,代价是会产生大量的微服务。Monzo统计,第一年不过数百个微服务,但到了2019年11月初达到了1,500个微服务,甚至去年12月更暴增到1,600个已上。这些微服务间互相的不重复呼叫超过了9,300个。
因为所有服务都在线上,Monzo希望尽可能落实零信任安全制度,因此,采取白名单方式来管控每一个微服务可呼叫的其他微服务名单。起初,微服务数量不多时,这份白名单采人工维护,但是,数量达到数千,甚至近万个时,维护工作非常复杂,因此,Monzo决定改开发自动化维护工具。
习惯自己开发工具的Monzo先挑了安全管控最严格的一支微服务service.ledger来测试,利用K8s的网路政策资源,在配置档中建立一个呼叫白名单。这是一支负责跨帐户移动金钱的微服务。
接着,Monzo开发了一个微服务通讯剖析rpcmap,可以自动分析每一支Go语言程序,找出对service.ledger微服务的所有呼叫来源,来建立白名单。有了名单之后,Monzo下一步是利用K8s的NetworkPolicy资源来执行过滤,在service.ledger所属的ledger服务配置档中建立网路政策,只有加上可允许标籤的网路流量来源才可以放行,并在ledger程序码目录中,放入一份授权来源的白名单档案。一旦有其他开发团队想要取得呼叫权限时,就得更新这个白名单档案,并且重新部建ledger服务(因为程序码内的档案有异动)后才能生效,ledger开发团队在部建阶段就可以审查这个新增的外部呼叫。
不过,测试后发现了几个问题,多了不少人工审查呼叫的负担,也会提高微服务回復旧版本的风险,再加上开发团队习惯手动编辑配置档,每一个人都能修改呼叫白名单,而难以管控。后来,Monzo决定导入开源的K8s网路安控专案Calico,在每一个微服务上建立一个微型防火墙功能,来管理存取。另外,Monzo也大力提高微服务管理的资讯透明度,如自製微服务剖析工具,方便开发团队查询每次程序码checkout后,微服务所用API的清单和状态资讯,并且大量采用视觉化监测工具来追踪流量和用量。
除了工具面的管理机制,Monzo也制作了一份后端工程师101指南,要求开发团队第一次撰写后端程序就要开始遵循,内容从新服务建立,RPC处理程序导入、数据库查询、如和透过Firehose发布和使用讯息、如何撰写单元测试,到如何部署,都有详细的说明和规定,并提供了一个Slack频道来讨论这套后端应用规範的上手问题。Monzo要求,每一个开发成员都要遵守这个规範来开发后端的微服务。
Monzo解释,微服务的颗粒度越细,尽管有助提高弹性,但是,需要搭配一致的程序码架构和工具,透过标準化让工程师聚焦在业务问题,持续改善工具和功能,才能快速进行一系列的微幅迭代修改,来打破大型金融应用的复杂性,又能降低风险。
使用Helm安装HAProxy Kubernetes入口控制器
Helm是Kubernetes的软件包管理器,类似于apt和yum,但是出生于容器领域。它与Kubernetes一起长大,并在第一个KubeCon上很早就引入了。它的工作是将应用程序的Kubernetes资源捆绑成一个程序包(在这里称为图表),以方便存储,分发,版本化和升级这些资源。其中包括Pod,服务,配置映射,角色,服务帐户以及Kubernetes生态系统中可用的任何其他类型。
Helm图表使您可以在安装过程中校准它们的行为,例如仅通过设置参数即可从Deployment切换到Daemonset,这使其非常适合于通过许多活动部件提供复杂的服务。
最近,我们添加了一个Helm图表,可用于安装HAProxy Kubernetes Ingress
Controller,简化了安装过程,并使开始将外部流量路由到集群中变得更加容易。我们的入口控制器是围绕HAProxy建立的,HAProxy是最快,使用最广泛的负载平衡器。有了这个基础,就意味着您可以立即享受到许多强大的功能,同时得益于HAProxy的传奇性能。
设置Helm变得比以往更容易。您不再需要安装Tiller,后者是负责执行API命令并在群集中存储状态的组件。 Helm版本3删除了Tiller,并已重新构造为使用内置的Kubernetes构造。这使Helm更加易于使用。由于与Kubernetes基于角色的访问控制紧密集成,它也使它更加安全。
在本文中,您将了解如何使用Helm安装HAProxy Kubernetes Ingress Controller,以及如何自定义其设置。 阅读详情,请后台回复Helm。
用haproxy和keepalived在Hetzner Cloud中为Kubernetes提供高可用性的外部负载均衡器
我正在开发一个允许用户添加自定义域的Rails应用程序,同时该应用程序具有一些通过Web套接字实现的实时功能。我正在Kubernetes中使用Nginx入口控制器,因为它是默认入口控制器,并且得到了很好的支持和记录。不幸的是,每当必须重新加载其配置时,Nginx都会切断Web套接字连接。当我的应用程序的用户添加自定义域时,会创建一个新的入口资源,触发配置重新加载,这会导致Web套接字连接中断。还有其他入口控制器(例如haproxy和Traefik)似乎比Nginx具有更动态的重新配置,但是我更喜欢使用Nginx。
因此,我认为可以防止Nginx的重新配置影响Web套接字连接的一种方法是为正常的Web流量和Web套接字连接分别配置入口控制器。这样,当正常HTTP流量的Nginx控制器必须重新加载其配置时,Web套接字连接不会中断。要在同一Kubernetes群集中具有Nginx控制器的多个部署,必须使用NodePort服务或LoadBalancer服务安装该控制器。不幸的是,我的提供商Hetzner
Cloud虽然总体上以具有竞争力的价格提供了优质的服务,但还没有提供负载均衡器服务,因此我无法像在大型云提供商中那样从Kubernetes内部配置负载均衡器。
因此,我决定在Kubernetes外部设置一个高可用性负载均衡器,该代理会将所有流量代理到两个入口控制器。为此,我安装了两个入口控制器,并使用NodePort类型的服务,并使用haproxy设置了两个节点作为代理,并使用浮动IP保持活动状态,并配置为始终有一个负载均衡器处于活动状态。这样,如果一个负载平衡器节点关闭,则另一个负载平衡器将在1-2秒内变为活动状态,而应用程序的停机时间最少或没有停机。在这篇文章中,我将展示如何为也使用Kubernetes的Hetzner Cloud的其他客户进行设置。请注意,如果您只需要一个入口控制器,则不需要。您可以只使用一个配置为直接使用主机端口的入口控制器。 阅读更多,请后台回复haproxy。
战略转向AP部署和派送流程,Docker公开未来产品蓝图
Docker在自家部落格说明了未来营运新战略蓝图,将会花更多的资源强化开发体验,使开发人员可以更方便地让程序码,部署到多云应用程序Runtime中。Docker将进一步发展基础Docker工具、Docker Desktop以及Docker Hub来加速这个过程,除了改善Docker Desktop的开发体验,并与生态系合作,且使Docker Hub能够整合、配置和管理,建构应用程序和微服务所需要的应用程序元件。Docker Hub将不只是一个註册表服务,而将会成为工具生态系中心,Docker Hub会提供各种工作管线选项,範畴从抽象功能到让开发者自己从头打造的元件都有。
微服务平台Istio大力拥抱WebAssembly,1.5新版推出全新套件扩充模式
开源微服务平台Istio是Google混合云平台Anthos的核心套件之一,最近释出了1.5新版,最大特色是推出了新的扩充套件模式,可以让开发者使用WebAssembly档案,快速透过Istio内的Envoy
proxy来发布或执行程序码,整合到远端环境中,也可整合政策管理系统、路由控管机制,甚至修改派送的讯息内容。官方指出,这个新模式可以让开发者更弹性地将一个复合式的元件,先各自分开执行初始元件再组合。另外,命令列工具istioctl增加了十多项改善,因此进入Beta测试版,而安装管理机制则仍旧在alpha测试版中,预计将发展成一个功能更完整的运维工具API。另外,在安全强化上,资安政策工具Auto
mTlS也进入测试版本,可以支援否定语法,来强制某些控制机制的政策不会被覆盖而出错。在透明度上,Telemetry第二则新增加原始TCP连线的监控支持。
K8s重新改造的新版vSphere 7正式发布,5月正式上市
VMware在3年前开始投入K8s技术开发,甚至找来,两位K8s创办人加入VMware,全新的K8s产品线Tanzu和改用K8s重新设计的新版vSphere
7终于亮相,VMware在vSphere底层放入了一套K8s,提供了一个底层K8s超级节点,可以同时执行VM和K8s容器化应用,也能直接在虚拟层上提供K8s丛集。VMware执行长Pat
Gelsinger直言,这是vMotion问世以来,最重要的虚拟化技术变革。Tanzu产品线则要用来管理和串接,各种不同环境的K8s,公有云、私有云、第三方版本等,来提供一个统一的K8s部署和管理介面。开源的Tanzu元件先释出正式版,而vSphere
7新版则预定在今年5月1日正式上市。
担心疫情失业潮,知名K8s DevOps工具书一个月免费要让工程师自学
担心新冠状病毒疫情重创科技业,恐出线工程师失业潮,知名软件工具书Ansible DevOps作者Jeff
Geerling最近决定,将自己两本热门工具书,免费提供下载1个月,让工程师可以自修来强化自己的能力。他在LeanPub电子书初版平台上,提供《Ansible
for DevOps》和《Ansible for Kubernetes》这两本书,订购者可自订要购买的价格,到最低的0元。
开发、训练到部署一套搞定,K8s机器学习工具包Kubeflow终于有正式版
超过2年开发,开源的K8s机器学习版终于释出了第一个正式版本。Kubeflow原本称为TensorFlow
Extended,是Google内部用来部署TensorFlow模型到Kubernetes的方法。在2017年底在美国Kubecon中对外开源,之后专案便蓬勃发展,现在有来自30个组织上百位的贡献者,参与Kubeflow专案的开发。Kubeflow
1.0提供了一组稳定版本的应用程序,提高开发者在Kubernetes上进行开发、建置、训练和部署模型的效率。包括Kubeflow的使用者介面Central
Dashboard以及Jupyter笔记本控制器,还有用于分散式训练的Tensorflow和PyTorch运算子,同时也提供管理多重使用者的配置文件管理器,和部署升级工具kfctl。
AWS自制容器专用OS,配置异动和搬迁都能靠API
AWS推出专门为容器主机最佳化的Linux操作系统Bottlerocket,包含容器主机所需要的元件,并且整合了现有容器调度工具,支援Docker映像档以及OCI(Open Container Initiative)格式的映像档。特别之处在于其更新以及API设计上,用户可以利用呼叫API来调整配置,而不需要手动更改,并且这些更改还可以在更新时自动搬迁。Bottlerocket不使用套件更新系统,而是使用基于映像档的更新模型,这个模型在必要时可以快速且完整的回煺,Bottlerocket中几乎所有的地方元件,都是以Rust开发而成,而Rust能够消除某些类型的记忆体安全性问题,并且使开发者以较安全的模式开发程序。
关于Canonical和Ubuntu 20.04你可能不知道的两件事
有媒体最近对Ubuntu Linux创造者Canonical的 开发人员 Alan Pope
进行了一次有趣的采访。要说这是一次具有启发性的对话,那就轻描淡写了。Alan Pope
勇敢地提出了各种各样的难题,但是在本文中,我想强调几个让我真正感到惊讶的事情。它们是对整个Linux生态系统至关重要的重要细节,但是我和Pope都同意,它们是大多数人不知道的。所有这些都围绕着Canonical的“硬件支持团队”,该团队由大约20名员工组成。Alan
Pope 告诉我:“有些事情甚至在人们甚至都不知道的幕后发生。”
“即将推出的笔记本电脑配备了新的音频硬件,固件,内核,Pulse和ALSA中发生的工作都需要进行协调,以使该硬件在该笔记本电脑上正常工作。我们有工程师团队为此工作。”
Alan Pope 补充说,Canonical确保即使这些计算机打算随Windows一起出售或运送,Ubuntu仍可在这些计算机上运行。“如果确定需要针对该硬件进行了微调的[Linux]内核,那么安装程序将检测到该错误并说‘我们制造的特定内核支持此计算机’,因此请勾选该框,它将继续运行并获取并加载它。”Alan Pope 说,这是一项面向未来的功能。Canonical表示,目标是用户可以购买他们知道支持的机器,并确信在后台,Ubuntu确保正确的内核已加载,“以支持该系统内部的时髦硬件”。
自定义内核被编码用于各种PC。以微软的Surface设备为例。该GitHub存储库为Surface Go,Surface Studio,Surface Pro及其之间的每个Surface设备托管自定义Linux内核。它包括正确的固件,触摸屏的正确参数等。但是,手动安装这些工具远远超出了普通用户的技能范围。具体来说,尚不知道Canonical正在开发或将来将开发多少个定制内核,并且该公司无法透露他们接受测试的每个品牌和型号,但是这两个事实加在一起,使我对Linux硬件兼容性的未来感到乐观。它已经很棒,但是可以做得更好。随着Ubuntu 20.04成为LTS版本(长期支持),也许有一天我们会看到创新的设备,例如微软即将面世的Surface Pro X或运行Neo的Surface Neo,以及其他Linux发行版。
在新的Ubuntu服务器上要做的四件事
全新配置的服务器是许多想法和项目的理想选择。您可以在新的Ubuntu服务器上执行以下各项操作,以确保顺利进行项目设置。使用新配置的服务器,您将获得一个默认用户帐户。该帐户通常可以访问root或sudo-er。您在此处添加的用户要求您使用SSH密钥而不是密码。您需要使用工具或CLI创建自己的密钥。如果已经有密钥对,则可以继续执行五个步骤:一是要在终端中生成密钥对,请执行以下操作。通常提供电子邮件地址作为密钥的注释。二是输入目录以保存密钥对。如果保留为空,它将保存在默认路径/home/{user}/.ssh/id_rsa中。三是接下来是询问您的密码短语。密码短语为密钥对提供其他身份验证。您可以选择忽略并按Enter键。四是在您指定的目录或默认目录中,它将生成2个文件。公钥和私钥。公钥的扩展名为.pub,而私钥没有扩展。五是在新的ubuntu服务器上,创建一个新用户。
Tor浏览器9.0.6发行的Tails 4.4匿名OS
Tails社区近日宣布了Tails 4.4的发布和全面可用性,它是基于Debian GNU / Linux的记忆删除隐身实时系统的每月更新。Tails 4.4发布于Tails 4.3之后一个月,Tails 4.3添加了对Trezor加密货币的支持,以更新一些核心组件和默认应用程序,并解决一些重要的安全漏洞和自上一版本以来用户报告的其他问题。Tails 4.4中包含最新的Tor浏览器9.0.6匿名Web浏览器,该浏览器基于Mozilla Firefox 68.6.0 ESR,Mozilla Thunderbird 68.5.0电子邮件和新闻客户端以及具有更好支持的Linux 5.4.19 LTS内核对于较新的硬件。此版本还尝试改善对使用Realtek RTL8822BE和RTL8822CE芯片组的系统中Wi-Fi接口的支持。从Tails 4.1开始经历Wi-Fi问题的用户应让Tails开发团队知道此修补程序是否在此处解决了该错误。在各种核心组件中修复了一些安全漏洞,包括cURL,Evince,Pillow,PPP和WebKitGTK。当然,新的Tor浏览器,Mozilla Thunderbird和Linux内核版本还包含Debian GNU / Linux 10“ Buster”存储库中的最新安全补丁。您可以下载Tails 4.4,但前提是您打算重新安装当前的Tails安装或在新计算机上部署匿名操作系统。现有Tails用户将从4.2、4.2.2和4.3版本自动升级。您也可以通过在终端仿真器中运行以下命令来手动升级。 后台回复口令“Tails”下载Tails 4.4。
PowerShell 7.0 正式发布
PowerShell 7.0 GA 正式发布了。除了常见的新 cmdlet/API 和错误修复之外,PowerShell 7.0 还引入了许多新功能。从 PowerShell Core 6.x 到 7.0 的转变也标志着从 .NET Core 2.x 到 3.1 的转变。.NET Core 3.1 带来了许多 .NET Framework API(特别是在 Windows 上),从而使与现有 Windows PowerShell 模块的向后兼容性大大提高。这包括 Windows 上需要 GUI 功能的许多模块,例如 Out-GridView 和 Show-Command,以及 Windows 附带的许多角色管理模块。更多信息可查看 PowerShell 7.0 的模块兼容性表。官方表示,PowerShell 7 标志着与 Windows PowerShell 的向后兼容性最大化的旅程已完成,“PowerShell 7 及其以后的版本将是真正的 PowerShell ”。
正则文本替换器 RegexReplacer v1.1 发布
正则文本替换器RegexReplacer已发布1.1版本,功能性变动:兼容jdk11,ps:仍旧兼容jdk1.6,增加Hole方法,吞掉所有参数(能简化某些技巧性替换)增加Length方法,可获取字符串的长度。源码调整:转换为maven工程,方便导入项目及打包等;调整包位置为“ com.github.trytocatch ”,使得更规范。RegexReplacer能做什么?它可以实现复杂的文本替换,虽然写代码或脚本也可以完成,但它简化了这一过程,例如下面的一行拆多行的替换,写一个正则表达式和一个替换表达式便可完成拆分。
FlarumChina 2020 更新
FlarumChina 更新:对 docker 一级支持;支持 upyun 对象存储,修改 S3 使其能够使用兼容 S3 协议的方案,比如 七牛云 金山云,或者使用 minio 自建存储;对 xunsearch 做了修改能够自定义服务器,使其能在 docker 中使用;对 pusher 做了修改使其能够使用自建的第三方服务 [poxa](文档稍后完善);新浪微博和腾讯互联的第三方登录;对 reCAPTCHA 做了修改使其能够在中国境内使用,包括服务器在中国境内 (目前在考虑添加 geetest,使整个过程更流畅。
WSL2 即将普遍可用,Linux 内核提供方式改变
微软博客宣布,WSL2 将在 Windows 10 2004 版本中正式进入普遍可用(GA,Generally Available)状态。WSL 2 是去年微软在 Build 2019 上宣布推出的,相比第一代,新的 WSL 重新设计了架构,使用真正的 Linux 内核,可以在 Windows 上运行 ELF64 Linux 二进制文件。Linux 二进制文件使用系统调用来执行许多功能,例如访问文件、请求内存与创建进程等。WSL 1 创建了一个转换层,对这些系统调用进行翻译,以允许它们在 Windows NT 内核上工作。但是,实现所有这些系统调用很有挑战性,导致某些应用程序无法在 WSL 1 中运行。现在 WSL 2 包含自己的 Linux 内核,它具有完整的系统调用兼容性,这引入了一组可以在 WSL 中运行的全新应用程序,比如 Linux 版本的 Docker。博客中同时说明了,目前对 WSL2 所依赖的 Linux 内核的提供方式进行了一些改进,已经从 Windows OS 镜像中删除了 Linux 内核,将会通过 Windows Update 方式分发给用户计算机。也就是 Linux 内核将像其它第三方驱动一样提供,这带来了更大的敏捷性和灵活性。 后台回复口令:“WSL2”阅读该博客。
Node.js 13.11.0 发布
Node.js 13.11.0 版本现已发布。其具体更新内容如下:
async_hooks:将 sync enterWith 添加至 ALS #31945;
cli:在 NODE_OPTIONS 中允许 --jitless V8 flag #32100
fs:返回由 mkdir recursive 创建的第一个文件夹#31530
n-api:define release 6 #32058
os:为内核版本创建 getter #31732
wasi:添加 returnOnExit 选项 #32101
DeepMind发布新冠状病毒致病病毒的6种蛋白质结构预测
为协助抗疫,DeepMind日前采用自家最新的AlphaFold系统,找出6种与SARS-CoV-2病毒有关的蛋白质结构预测,也就是引发新冠状病毒(COVID-19)的病毒。团队指出,了解病毒的蛋白质结构,可进一步了解病毒的运作模式,但通常需要数个月的实验,才能找出蛋白质结构,甚至更久。因此,许多团队都决定借助电脑算力,来加速这个过程。DeepMind今年1月于《Nature》发表了深度学习系统AlphaFold,可用来准确预测蛋白质结构,并以SOTA等级的准确率产生3D蛋白质模型。DeepMind指出,自系统发表以来,团队不断改善,近日更应用最新版的系统,开发出6种新冠病毒的蛋白质结构预测。虽然还未经同侪审评或实验验证,鉴于急迫性和严重性,DeepMind决定公开结构预测,供其他研究者下载。
简化AI模型工作流程,Google发表Beta版Cloud AI Platform Pipelines
Google推出Beta版Cloud AI Platform Pipelines,要来简化AI模型的工作流程。Google指出,在notebook中建立机器学习模型原型非常容易,但要扩大整个工作流程,就会变得复杂,因为从数据准备和分析开始,再到建模、模型评估、测试和部署等,每个环节都相互影响,难以完整追踪。这款新工具可针对工作流程进行监控、审核、版本控管,并提供安全的执行环境,让使用者来部署稳健、可重复使用的机器学习工作流程,提供了一键式安装、自动追踪元数据和执行动作,版本追踪、提供视觉化工具等企业级功能,此外,它也整合了Google云端服务如BigQuery、Dataflow、AI平台训练与部署等,另有许多预建的工作流程元件,让使用者用来打造自己的元件。
Amazon用群众外包回馈找出下单原因,要来改善产品推荐演算法
Amazon日前发表一项研究成果,利用群众外包方式,收集民众对产品的评断。团队表示,这些发现可帮助预测顾客对商品的评价,也能修正目前的产品推荐演算法,进一步提高顾客体验。在研究中,团队对群众外包的参与者,提供了一组组产品文宣,每组都是属性相近的产品,比如同款式、同颜色的耳机,但是以不同角度的照片和说明来呈现,这些说明来自卖家以及顾客评价;而每组展示产品中,包含了一个成功贩售的产品,以及一个消费者点击但没购买的产品。接着,参与者需从每一组中,选出自认为品质较好的产品,并选出影响最大的因素。研究发现,价格虽然还是最大影响因素,但消费者会购买商品主要原因,还来自其他买家的评论。团队指出,现有的商品推荐模型,都是直接针对已购买的产品来建模,却没人探讨购买前的消费者行为。团队认为,这次的发现可改善现有商品推荐的不足,进而提高顾客体验。
微软更新ML.NET模型建立器,Azure云端运算资源加持更快速
微软近日更新了跨平台机器学习框架ML.NET Model Builder,现可通过Azure云端运算资源,来加速图像分类模型的训练,此外,这次更新还加入推荐情境功能,使用者可在本地端训练ML.NET推荐模型。进一步来说,开发者可将训练工作发布到Azure机器学习服务,在Azure训练完后,模型建置器会同时将ML.NET和ONNX两种格式的模型下载回电脑,开发者可利用评估功能测试模型,并产生模型应用程式码,可用ML.NET模型来预测。
漫漫7年,地图Android公用程式函数库1.0终于发布
自从2013年地图Android专案展开以来,Google最近终于发布开源地图Android公用程式函数库(Maps Android Utility Library)1.0,供开发者用来补充Android地图SDK的不足。Google指出,这次1.0版本修復了前一版的57个问题,也解决了稳定性问题和KML层的一些错误。进一步来说,新功能可显示多个地图图层,并能交互作用,开发者也能更新丛集中的项目,来处理KMZ数据类型。Google提醒开发者,这个版本与之前版本差异颇大,因此在使用前,应先阅读功能更新日志。
比全球200大超级电脑还快!HPE采AMD芯片打造2 Exaflops超级电脑
HPE宣布将采AMD芯片,来打造全球最快速的Exascale等级超级电脑。这台超级电脑名为El Capitan,买主是美国能源部国家核子安全局(NNSA),要提供旗下3个实验室使用,预计2023年初交货。El Capitan将使用Genoa最新一代AMD EPYC处理器,采Zen 4处理器核心、下世代AMD Radeon Instinct GPU,以及第3代AMD Infinity架构。其中,Genoa和Radeon Instinct GPU的记忆体与I/O子系统,都是为深度学习和高效能运算作业而设计。HPE指出,El Capitan的最高浮点运算达2 exaflops,也就是2,000 petaflops,远高于目前全球200大超级电脑的总和。
Google更新云端语音转文字服务,能听懂更多语言
Google日前更新云端语音转文字(Speech-to-Text)API,除了新增7种语言,也强化了4种功能,包括语音适应、电话通话模型、发言人自动分段标记和自动标点等。首先,新支援的语言有缅甸语、爱沙尼亚语、乌兹别克语、旁遮普语、阿尔巴尼亚语、马其顿语和蒙古语等。就功能来说,语音适应可让企业调整服务产生的文字,比如辨识客户服务来电中难以翻译的产品名称。至于发言人自动分段标记,则可区分一段语音中的不同发言人,可让用户轻鬆为影片增加字幕。另外,自动标点符号功能会模仿用户写下所说话语的方式,来加强文字的可读性,这次Google可支援德语、法语和日语等18种方言。
微软紧急修补SMB蠕虫漏洞
微软已完成了CVE-2020-0796漏洞修补,该漏洞存在于Microsoft Server Message Block 3.1.1(SMBv3)协定中,允许黑客自远端执行任意程式,且被英国资安业者Sophos视为本月微软最重要的安全漏洞。微软原本计划要在Patch Tuesday同步修补CVE-2020-0796,只是当天却未见CVE-2020-0796,但事前收到微软通知的资安业者不小心外洩了CVE-2020-0796的资讯,且微软也公布了与该漏洞有关的安全通报。不过,微软在两天后紧急修补了CVE-2020-0796。此一存在于SMBv3协定的漏洞,可同时用来开採SMB服务器端与SMB客户端程式,波及Windows 10 1903/1909,以及Windows Server 1903/1909等平台。根据Sophos的说明,该漏洞涉及其中一个核心驱动程式的整数上溢与下溢,黑客可藉由恶意封包来触发下溢,以自由读取核心,或是触发上溢来覆盖核心中的写入指标。
Sophos指出,黑客可能通过网络,来危害任何启用档案分享功能的Windows电脑,不管是个人电脑或是档案服务器;或是利用社交工程或中间人攻击以将Windows用户引导至恶意的SMB服务器;也可藉此展开权限扩张攻击,取得系统的更高权限。一般而言,Windows防火墙会封锁从SMB埠进入的公共网络流量,但如果防火墙被关闭了,SMB埠被开启了,或是该电脑位于Windows Domain中,那么可能就会曝露在安全风险中,因此,任何未修补且开放SMB埠的电脑,都有可能受到攻击,而且是类似WannaCry般的蠕虫式攻击。这类的攻击通常锁定开启的445/tcp连接埠,但使用者不能只通过关闭445/tcp来因应,因为不只是SMB,其它Windows Domain的重要元件,也需要使用445/tcp。总之,Sophos呼吁Windows用户应该要立即修补CVE-2020-0796。
云端区块储存服务新选择,提供坚实的多重高可用性架构设计
等待了近1年时间后,Pure Storage的云端区块储存服务——Cloud Block Store(CBS),终于在去年底(2019)正式上线。过去一年多以来,Pure Storage在整合公有云平台方面动作连连,于2018年底宣布了称作「Pure Storage Cloud Data Services」的一系列云端储存服务,而CBS便是其中之一。CBS是当前兴起中的新类型储存产品——「云端储存阵列」的一员。这种产品的本质,其实就是传统储存阵列厂商将其储存阵列系统移植到公有云上,成为「云端化」储存阵列而成,通过公有云平台来提供储存空间服务。而CBS便是Pure Storage将旗下的FlashArray全快闪储存阵列,移植到AWS公有云平台上的产品,可在AWS上提供基于iSCSI的区块储存空间服务,目前有10TB、20TB与50TB等3种容量授权可选,并凭藉着与FlashArray储存阵列相同的Purity//FA储存作业系统,具备了Thin Provisioning、压缩与重复数据删除等进阶功能。目前CBS虽然只支援AWS平台,但依照Pure Storage的规划,日后也将在Azure与Google Cloud上推出相同的服务。
CBS是Pure Storage FlashArray全快闪储存阵列,移植到AWS而成的云端化储存阵列,可在AWS上提供基于Pure Storage储存系统的区块储存服务,并含有完整的数据服务功能。公有云服务的盛行已是大势所趋,传统储存阵列厂商面对这个新兴威胁,一个出路便是「打不过他,就加入他」,把自身的储存阵列平台移植到公有云平台上。公有云服务商虽然自身提供了原生的储存服务,但老牌的储存阵列平台,有着用户熟悉、系统成熟、数据服务功能丰富完整的优点,而移植到公有云以后,不仅保有储存阵列原本的优点,还能兼有云端服务的维运负担轻、按需订购弹性等优点。以CBS来说,相较于AWS自身原生的两种区块储存服务——执行个体储存空间(Instance Stores),以及EBS(Elastic Block Store),目的同样都是提供区块储存服务,但能提供后两者没有的丰富数据服务功能。AWS执行个体储存空间,是一种执行个体直连的本地端储存空间,有硬碟、SAS SSD与NVMe SSD等型式,具备低延迟的特点,但组态固定,缺乏弹性,也没有因应磁碟装置故障的冗余能力。
至于EBS储存区,则有着类型选择丰富(有io1、gp2、st1与sc1等4种)、组态弹性(500GB~16TB),以及通过分散复制机制所提供的高可用性,还具备基本的数据服务功能(快照与加密)。而CBS实际上是建立在前两者的基础上——以EBS的io1储存区作为NVRAM写入缓冲角色,以执行个体本机的NVMe SSD作为读取快取与写入储存区,再结合S3物件储存作为备援的持久储存区,并能通过Pure Storage的ActiveCluster复製功能,跨不同AWS可用区域(AZ)建立异地的高可用性CBS群组,兼具了效能与可靠性。更重要的是,CBS还能凭藉Pure Storage自身专属的Purity//FA储存平台,提供目前AWS原生储存服务还没有的即时压缩、重复数据删除等数据缩减功能,藉此改善储存空间耗用经济性。因此CBS这类云端储存阵列产品的问世,也让用户在公有云上的应用,除了使用各公有云自身原生的储存服务外,也多了Pure Storage这些第叁方厂商的解决方案,各自基于专属储存平台,提供了公有云储存服务新选择。
如前所述,CBS这类云端储存阵列产品,是将传统储存阵列平台移植到公有云环境而成,从而为公有云上的运算单元,提供基于传统储存阵列平台的储存空间服务。而要实现这样的目的,关键便在于如何让传统储存阵列平台「移植」部署到云端环境,从而化身为公有云上的储存服务。将储存阵列移植到公有云上的方式,主要分为两种。一种方式为实体部署,也就是在公有云服务商数据中心部署实体储存设备。例如NetApp的Cloud Volumes Service(CVS)、HPE的Cloud Volumes,都属于这种类型。
另一种方式为软件定义部署,也就是利用公有云的执行个体与储存空间,来运行储存阵列系统软件。如NetApp的Cloud Volumes ONTAP(CVO)、Dell EMC的UnityVSA Cloud Edition,以及我们这裡介绍的Pure Storage CBS,都属于这种类型。不过,即使同样属于软件定义部署,但个别产品的实作方式也大相迳庭,而CBS可说是最特别的一种。NetApp CVO算是软件定义部署式云端储存阵列的标准範本,使用1台云端运算单元来运行NetApp的ONTAP系统,担任储存控制器角色,并挂载公有云的区块储存区来作为储存空间。为了提高可用性,还可将2台CVO组成高可用性群组。
而CBS则动用了AWS的EC2执行个体、执行个体本机储存区、EBS区块储存区,以及S3物件储存区,来扮演储存控制器、写入缓冲、读取快取等角色,每套CBS单元至少需耗用9台或16台执行个体(2台用于控制器,7或14台用于虚拟磁碟)、7个EBS服务的区块磁碟区,与一定容量的S3储存区。虽然CBS耗用的资源相对较大,成本相对也较高,但藉此在AWS上再现了FlashArray全快闪储存阵列的架构,理应更能保证效能与可用性,以因应Tier1的关键应用储存需求。
CBS这类云端储存阵列,除了能为公有云的储存服务,提供基于第3方储存厂商平台的新选择外,另一个重点是能结合用户的本地端储存设备,构成高度整合的混合云架构。以CBS来说,便能与用户本地端的FlashArray储存阵列,构成紧密的混合云应用架构。CBS与FlashArray的核心,同样都是基于Purity//FA作业系统,因此可以相互连结,构成异地备援,在储存服务这一层级,直接通过磁碟区的远端复製,在本地端FlashArray与云端的CBS之间,交换或迁移数据。
另外,CBS也能结合Pure Storage的CloudSnap云端快照储存服务,提供经济的混合云应用。用户平时可将本地端FlashArray的数据。通过CloudSnap上传到S3储存空间保存,待需要异地备援时,再订购与启用CBS,然后于CBS上挂载CloudSnap在S3保存的本地端FlashArray快照,便能迅速完成CBS与本地端间的站点数据同步。在AWS环境中运行的CBS云端储存阵列,是以AWS的资源架构而成,分别使用EC2的c5n与i3执行个体,以及EBS的io1区块储存区,来分别扮演储存控制器、Flash储存模组、读取快取,以及NVRAM模组等角色。Pure Storage提出了两种CBS组成规格——CBS //V10A-R1与CBS //V20A-R1,分别採用不同等级的EC2执行个体与EBS io1储存区。
其中较低阶的CBS //V10A-R1,Pure Storage建议使用2台c5n.9xlarge执行个体来作为储存控制器,搭配作为虚拟磁碟机的7或14台i3.2xlarge执行个体,再加上作为NVRAM的7个60GB EBS io1磁碟区。其中,作为控制器的c5n.9xlarge执行个体,可提供50Gbps的总网络频宽,每个连接埠的频宽为5Gbps,整个系统则可提供13.8TB~15.2TB的可用容量。至于较高阶的CBS //V20A-R1,控制器是使用2台规格更高的c5n.18xlarge执行个体来担任,搭配作为虚拟磁碟机的7或14台i3.4xlarge执行个体,或是7台i3.8xlarge执行个体,加上作为NVRAM的7个120GB EBS io1磁碟区。其中,作为控制器的c5n.18xlarge执行个体,可提供100Gbps的总网络频宽,每个连接埠的频宽为5Gbps,整个系统能提供55.2TB~60.8TB的可用容量。
Pure Storage建议用于扮演CBS储存控制器角色的两种执行个体——c5n.9xlarge与c5n.18xlarge,都属于c5n系列运算优化型执行个体,是EC2服务中针对HPC、数据湖等应用,特别强调运算能力与网络传输频宽的执行个体,基于3 GHz的Intel Xeon Platinum 处理器,分别可提供36个与72个vCPU、96GB与192GB记忆体,以及50Gbps与100Gbps传输频宽,可保证CBS的I/O效能,并因应数据删减相关功能带来的运算负荷。而CBS用于担任虚拟磁碟机角色的3种执行个体——i3.2xlarge、i3.4xlarge与i3.8xlarge,则属于i3系列储存优化执行个体,特别强调本机储存能力,均配置了直连的NVMe SSD,但处理器规格与网络频宽相对较低(10Gbps以下) 。
另外Pure Storage还建议,用户在订购供CBS使用的执行个体时(包含控制器与虚拟磁碟),选用可转换型式的预留执行个体(Convertible Reserve Instance),而非标准预留执行个体(Standard Reserve Instance),以便运用可转换预留执行个体便于变更属性的特性,在日后升级为更高阶的执行个体。
如同多数的公有云服务产品,CBS的订购方式,也分为公有云服务商与储存厂商等两个来源。「Pure as-a-Service」服务是一种混合云的授权,在「Pure Storage ES2」採购项目下,提供了在1年(以上)合约期限内,100TB容量起跳的混合云使用空间授权(云端CBS+本地端FlashArray),用户从这裡取得CBS的授权后,再到AWS市集中的「Cloud Block Store - Product Deployment」订阅项目下完成部署。更单纯的方式,是直接从AWS的市集订阅CBS服务,先在「Cloud Block Store」订阅项目下,购买使用空间授权,然后再到「Cloud Block Store - Product Deployment」项目下完成部署。AWS提供了4种等级的CBS授权——Small、Medium、Large与按使用量计价的Pay-as-you-go。其中Small等级授权的预留容量上限是10TB,Medium等级是20TB,Large等级为50TB,订阅期限有1个月或12个月两种可选。
比较特别的是Pay-as-you-go授权,适合想要体验CBS的用户,这种模式不需要一次购买定量的空间,头1个月10TB内不收取费用,从第2个月起,再按每单位每GB来计价,订阅期限以1个月为基准。除了前述4种等级的容量授权费用外,CBS还有基本设定费(Basic Setup)、超过预留容量上限的超量(Overage) 使用费,以及增值服务费(Professional services)等额外费用。其中,增值服务是一系列帮助用户部署CBS的谘询与协助服务,包含初期的需求评估、部署前准备、部署作业执行、部署后作业等服务,同时,又分为基本增值服务(Basic Professional services),以及进阶增值服务(Advanced Professional services),而前述的基本设定(Basic Setup)费用所对应的部份,就等于这裡所提及的基本增值服务。
为用户提供企业级K8S解决方案,Rancher完成D轮4000万美元融资
2020年3月17日,业界应用最为广泛的Kubernetes管理平台创建者Rancher Labs(以下简称Rancher)宣布完成新一轮4000万美元D轮融资,本轮融资由Telstra Ventures领投,既有投资者Mayfield、Nexus Venture Partners、国富绿景创投(GRC SinoGreen)和F&G Ventures跟投。Telstra Venture的投资者之一澳大利亚电信(Telstra Corporation)是澳大利亚最大的电信企业,同时也是Rancher的客户。
此前,Rancher曾在2019年7月获得C轮2500万美元融资,2016年获得B轮2000万美元融资,2015年获得A轮1000万美元融资。新一轮融资使Rancher融资总金额累计至9500万美元(逾6亿6千万人民币)。Rancher透露,本轮融资用于进一步推动产品的持续创新,加大对Go-To-Market的投入,以及拓宽Kubernetes在全新市场与行业中的无限可能。
Rancher成立于2014年,由CloudStack之父梁胜创建,是业界领先的企业级容器管理软件提供商,帮助用户轻松地统一管理在数据中心、云、分支机构和边缘运行的Kubernetes集群。得益于企业对Kubernetes的强劲需求,以及Rancher创新且独特的功能和价值主张,2019年,Rancher全球营业收入同比增长169%,客户数量同比增长100%。
“这一轮融资再次说明,投资机构对Kubernetes市场及Rancher的技术实力充满了信心。”Rancher联合创始人及CEO梁胜表示:“正如Linux在21世纪初成为了数据中心、云和设备的标准计算平台一样,我们充分相信,Kubernetes将于2020年迅速成长为多云及异构IT环境中无处不在的企业计算平台。”
Rancher,推动计算无处不在
第三方数据统计公司451 Research在研究指出,到2022年,76%的企业将采用Kubernetes作为标准的基础设施计算平台。这一数据充分表明,Kubernetes将成为与企业IT战略和云原生应用程序关联度最高的平台。Rancher的旗舰产品Rancher是业界应用最为广泛的Kubernetes管理平台,全球累计下载次数逾一亿次,拥有知名企业客户逾40,000家。除此之外,Rancher还围绕Kubernetes生态进行了一系列的延展与探索,其中Rancher推出的轻量级Kubernetes发行版k3s是目前业界公认的边缘Kubernetes最佳解决方案。
Rancher+k3s组成了Rancher “Kubernetes即服务(Kubernetes-as-a-Service)”解决方案堆栈,将Kubernetes的能力从数据中心、云端延展至边缘端,充分赋予企业在任何基础设施上部署Kubernetes的自由。梁胜表示,未来,Rancher将在产品、行业解决方案和团队建设三个方向发力,为企业在生产环境中落地Kubernetes提供更为夯实的基础。
在产品方面, Rancher将持续发力让Kubernetes进一步成为通用计算标准,在Kubernetes关键领域进行持续创新,包括异构集群联邦(heterogenous cluster federation)、车队管理(fleet management)和边缘计算环境中的Kubernetes落地等等。
更重要的是,Rancher还将凭借其自身在Kubernetes领域的领导者地位,与其他领先的科技公司合作,在5G、数字工厂、车联网、视频监控和医学研究等领域共同开发基于Kubernetes的行业解决方案,拓展Kubernetes在新行业与新领域的无限可能。
在全球扩张及团队建设方面,Rancher将扩大现有的销售、市场、财务、运营、客户成功和客户支持团队。此外,Rancher全球团队分布当前已覆盖14个国家,未来还将进一步在地理版图上扩大国家与城市的覆盖率,为全球企业客户提供更为专业的技术服务。
尤为值得一提的是,2019年全年,Rancher在大中华地区的业务年复合增长率超越300%,中国有望成为Kubernetes全球增长最快的企业级市场。正是基于对中国Kubernetes市场的看好,Rancher已于2020年2月完成了中国本土化和国产化,从2020年3月1日开始,Rancher在中国大陆、香港澳门地区、台湾地区的业务,均由全中资公司Rancher中国云澈信息技术(深圳)有限公司承载,并面向中国企业客户提供了中国企业版Rancher产品和中国版k3s边缘计算平台。
Telstra Ventures,独特的“客户变投资人”
澳大利亚电信(Telstra Corporation)以Rancher为基础,打造了企业核心的客户联络中心、客户网络以及客户服务中心。正是澳大利亚电信的成功案例,以及其间Rancher展现出的强大的技术实力吸引了Telstra Ventures,使其对Rancher产生了浓厚的兴趣。
Telstra Ventures是一家全球知名的战略风投机构,专注于市场领先及拥有出色产品的高增长技术企业的投资,由全球20大电信运营商之一的澳大利亚电信(Telstra Corporation)和全球最大的私募股权资金之一HarbourVest两名战略投资者共同构成。
Telstra Ventures参与投资的知名技术企业包括开源代码库GitLab、企业云档案管理Box、电子签名认证DocuSign和终端安全防护平台CrowdStrike等。
“除谷歌外,Rancher是全球首家意识到Kubernetes将对IT市场产生深远影响的公司之一。在我们进行早期投资相关讨论的时候,梁胜曾表示‘Kubernetes具有成为云计算的TCP/IP协议角色的潜力’,这是一个极具吸引力且令人印象深刻的描述。”负责Telstra Venture企业投资的投资合伙人Steve Schmidt感叹道。
对于像Telstra一样正在部署5G的领先电信公司而言,Rancher无疑是令人无法忽视的存在。“我们相信,Rancher将在把Kubernetes引入5G的方向上起到独特的桥梁作用。”
另一方面,梁胜在云计算领域的丰富履历及技术魅力也是促使Telstra Venture投资Rancher的另一关键要素。作为全球知名的风投机构,Telstra Ventures一直致力于寻找世界一流的企业家。他们认为,世界一流的企业家可以打造出色的产品,同时也能成功地将其推广向市场。
“我们的使命是‘与非凡的人合作’,在接触梁胜后,我们坚信他是一个世界一流的企业家。”Steve Schmidt补充道:“更为显而易见的是,Rancher正在梁胜及其创始团队的带领下走向卓越。”
最后,Rancher中国CEO秦小康总结道:“容器技术在全球新一轮技术创新及应用领域的广阔前景正在逐步展开,我们尤其看好实现国产化和本地化的Rancher中国强劲的发展前景。在全新的发展阶段和下一代技术浪潮中,Rancher中国也将与广大中国用户和合作伙伴一起,践行‘Computing Everywhere’的新一代计算平台理念,以持续创新的技术能力,为中国客户数字化信息化建设保驾护航。”
GitLab发布实验性新功能Partial Clone
Git近期版本开始支持部分复制(Partial Clone)功能,而程式码托管服务GitHub与GitLab也开始跟进,GitHub在年初时提到他们正在评估部分复制功能,成熟时会逐步发布,而GitLab现在则宣布开始提供部分复制功能实验性测试。部分复制是Git的一项新功能,用来取代Git LFS(Large File Storage),部分复制使Git不再下载储存库中的每个档案,使其在大型储存库运作得更好。部分复制经GitLab、GitHub、微软和Google多年合作发展,在近期开花结果,现在于GitLab中开始实验性测试,管理员可以视情况启用该功能。
Git发展至今已经快15年,过去有许多项目不使用Git,因为像是电玩游戏这类具有许多大型二进位档案的项目,当Git复制储存库时,Git会下载储存库中每个档案的每个版本,在大多数的使用情况中,下载歷史纪录或许是有用的功能,但大型二进位档案的复制和撷取速度却非常慢。而要在Git处理大型档案,需要额外的工具,像是2010年发布的git-annex和2015年的Git LFS,以类似的方式增加Git处理大型档案的能力,其主要中心思想是,不在Git中储存大型档案,而是储存大型档案的指标,当需要使用到大型档案时,再使用指标按需下载档案。
不过,这种方法的缺点不只是易受人为错误影响,而且指针的编码方式依频宽以及档案类型决定,并同时影响储存库的所有人,由于对频宽或是储存的假设,会随着时间改变,同时也会依位置而有所不同,但是储存库的编码策略却不够灵活到可随时改变。现在推出的部分复制功能可解决这些问题,因为传输的资料较少,加快了撷取和复制的速度,也减少本机电脑的硬盘使用量,GitLab以自家gitlab-com项目举例,复制速度快50%,传输资料量减少70%。
当用户在普通的git clone指令之后加入过滤器规範,就能以该规範排除特定内容,像是使用—filter=blob:none,就可在复制时排除大型二进位档案,GitLab提到,在像是gitlab-com这类包含许多图像的项目上使用,更能体现出部分复制的优点。
GitLab的部分复制现在支持多个远端服务器,而且将会让大型档案可以储存在像是AWS S3等物件储存中,但与Git LFS不同的是,储存库或是实例管理员,可以决定物件储存的位置,以及按需求改变配置。部分复制比Git LFS使用起来更简单,因为Git LFS需要安装其他工具,而部分复制不需要,不过使用者仍需要学习使用新选项和配置。
由于在最新的Git 2.25中,过滤功能并未最佳化,因此当使用过滤规範要从Git服务器中,撷取并排除特定物件,Git需要检查储存库中的每个档案,并排除所有与过滤器规範相符的物件,不过,Git开发社群已经改进Blob大小过滤效能,预计会在Git 2.26中更新,GitLab计画会在12.10版本中跟进。
近期Git在复制相关功能的更新,除了增加部分复制功能外,也新增了稀疏签出(Sparse
Checkout)功能,GitLab解释,部分复制是针对大型储存库的特定效能最佳化,而稀疏签出则是一个相关的最佳化功能,特别针对具有极大量档案和版本的储存库。
GitHub同意购买代码分发初创公司Npm
微软的GitHub子公司周一表示,已同意收购Npm,这是一家经营在线服务的公司,该服务用于分发以流行的JavaScript编程语言编写的开源软件包,并提供公司可用于其专有代码的软件。这项新交易表明,尽管微软一直在分发诸如Windows之类的价格昂贵的产品,但微软却在帮助个人和企业开发人员采用开源软件的战略上加倍努力。微软在2018年以75亿美元的价格收购了GitHub,这是一个用于许多开源项目的在线存储库,根据初创公司Stack Overflow的最新调查,这一策略特别是在JavaScript中为开发人员提供了最有效的帮助。
去年5月,GitHub引入了Package Registry服务,它代表了Npm的竞争程度。允许人们从他们的代码中发布新软件包。“对于使用npm Pro,Team和Enterprise托管私人注册表的付费客户,我们将继续为您提供支持。GitHub首席执行官Nat Friedman在博客中写道:“我们还大力投资GitHub Packages,将其作为与GitHub完全集成的强大的多语言包注册中心。” “今年晚些时候,我们将使npm的付费客户能够将其私人npm软件包移至GitHub软件包,从而使npm可以专注于成为JavaScript的大型公共注册表。”
“当我在旧金山的GitHub HQ看到GitHub Packages beta公告和演示时,我记得转向Shanku Niyogi时,笨拙地脱口而出,'你为什么不打算收购我们?'” Npm软件包的发明者Isaac Schlueter Npm的经理兼创始人在周一的博客中写道。
Npm成立于2014年,总部位于加利福尼亚州奥克兰,拥有46名员工。开源的Npm软件包管理器的日期为2009年。初创公司的投资者包括Bessemer Venture Partners和True Ventures。截至周一,Npm主页将Microsoft以及Adobe,Nike和Salesforce列为“感恩地服务”的公司之一。
Oteemo启动企业Kubernetes和云原生培训计划
企业DevSecOps和Cloud Native Transformation咨询公司Oteemo近日启动了其企业kubernetes和Cloud Native学习计划。该计划旨在提高整个IT组织在Kubernetes和Cloud Native计算原理上的技能。企业Kubernetes和Cloud Native培训计划,面向希望通过容器和kubernetes将其团队从传统应用程序开发转变为现代Cloud Native开发的IT组织,面向希望通过容器和kubernetes将其团队从传统应用程序开发转变为现代Cloud Native开发的IT组织。
随着IT企业将Kubernetes和Cloud Native视为其数字化转型旅程的核心部分,CIO,CTO和IT组织领导者的主要关注点是为其全体员工提供正确的培训,并将他们从进行遗留应用程序开发转变为实施现代技术。使用云原生范例进行应用程序开发。
“我们很高兴启动我们的企业kubernetes和云原生学习计划。通过该计划,我们将能够全面考察IT组织并创建学习策略,以提升其IT团队在kubernetes和cloud native上的技能通过此计划,我们认为我们可以帮助我们的客户快速而持续地培训他们最重要的资产-他们的员工-在他们将组织转变为云计算的过程中获得最大的培训投资回报Oteemo首席执行官Raja Gudepu说。该计划将满足IT组织中的以下关键角色;软件开发人员,DevOps工程师,站点可靠性工程师,项目经理和执行人员。针对每种角色都有单独的培训课程。该计划的独特性基于其个性化和自定义功能,这将使Oteemo可以根据组织当前的IT生态系统,技能水平和用例进行培训。
了解更多:
https://news.yahoo.com/oteemo-launches-enterprise-kubernetes-cloud-170000400.html
有关使用Kubernetes获得全栈可见性监控的最佳实践
微服务(现在已成为我们构建基础架构的实际选择)为容器铺平了道路。借助Docker以及用于容器编排的Kubernetes等工具,组织现在可以更快,更大规模地发布应用程序。但是,所有这些功能和自动化带来了挑战,尤其是如何保持对这些临时基础结构的可见。Kubernetes很复杂。为了成功使用它,它需要同时监视几个组件。为了简化监控策略,请将监控操作分为几个区域,每个部分都涉及Kubernetes环境的单个层。然后从上到下分解对工作负载的监视:集群、pod、应用程序以及最终用户体验。
该集群是Kubernetes的最高级别组成部分。大多数Kubernetes安装只有一个集群。这就是为什幺当您监视群集时,可以在所有区域看到完整的视图。并且可以轻松地确定组成集群的Pod,节点和应用程序的运行状况。使用联合部署多个群集时,必须分别监视每个群集。您将在集群级别监视的区域是:
失败的Pod:失败和中止的Pod是Kubernetes进程的正常部分。当Pod应该以更高的效率工作或处于非活动状态时,调查Pod故障异常背后的原因至关重要。
节点负载:跟踪每个节点上的负载对于监视效率是不可或缺的。一些节点可能比其他节点使用更多。重新平衡负载分配是保持工作负载流畅和有效的关键。这可以通过DaemsonSets完成。
群集使用情况:通过监视群集基础结构,您可以调整使用中的节点数量并分配资源以有效地为工作负载供电。您可以查看资源的利用方式,从而可以扩大或缩小规模,并避免了额外基础架构的成本。
集群监控提供了Kubernetes环境的宏观视图,但是从单个Pod收集数据也是必不可少的。它揭示了各个Pod的运行状况以及它们托管的工作负载。在集群之外,您可以在粒度级别上更清晰地了解Pod的性能。这里将监视:
吊舱实例总数:吊舱实例必须足够,以确保高可用性。这样就不会浪费托管带宽,并且您不会运行超出所需数量的Pod实例。
Pod部署:监视Pod部署可让您查看是否存在任何可能降低Pod可用性的错误配置。请务必注意资源如何分配到节点。
实际的Pod实例:监视每个Pod正在运行的实例数与预期运行的实例数,将揭示如何重新分配资源以实现Pod实例的所需状态。如果您看到不同的指标,则副本集可能配置错误,因此定期进行分析很重要。
监视群集中托管的应用程序对于成功至关重要。应用程序监控发现的问题可能是Kubernetes环境或应用程序代码中的问题。通过监视应用程序,您可以识别故障并立即解决它们。 了解更多,请后台回复指令:全栈可见性监控。
微服务管理器Istio 1.5中的网络代理Envoy,开始支持WebAssembly增加动态可扩充性
Google、Lyft及IBM合作开发的微服务管理器Istio,最近推出了1.5版本,而Google说明这个版本其中最大的特色,便是Istio的网络代理Envoy开始支持WebAssembly,而这让Envoy和Istio能够获得WebAssembly扩充套件的加持,借以将Istio可扩展性从控制层(Control Plane)移到侧车代理(Sidecar Proxy)。目前这项功能还在Alpha测试阶段。
Lyfty在2016年开源了Envoy服务代理项目,现在逐渐成为云端原生应用程式部署的固定工具,包括在边缘以及侧车应用都受到欢迎。Envoy原本就有其扩充机制,可以使用预编译的C++模组或是Lua脚本增加扩充功能,但Google提到,这两者都有其缺点,由于Istio的设计目标之一,就是要简化政策、遥测和日誌系统的扩充性,虽然使用控制层元件和程序外配置器可以达到这目的,但是却会增加多余的网络跳跃点以及延迟。
WebAssembly是一种二元指令格式,Istio现在透过Envoy把WebAssembly带进服务器端中。WebAssembly现在已经是W3C推荐的网页应用标准,使用者可从30多种语言编译成WebAssembly程式码,并在沙盒环境中执行。透过WebAssembly在Envoy代理中扩充功能,则不需要重新编译程式码,部署也更加简单,Istio能够将扩充套件发布给代理,在不需要重新启动的情况下,载入扩充套件。
Envoy项目创造者Matt Klein提到,在Envoy中支持WebAssembly,将会解开更多服务网状网络和API闸道的使用案例。而为了要强化WebAssembly扩充套件的使用体验,他们与Solo.io合作,Solo.io创建了WebAssembly Hub服务,可用来建置、共享、探索和部署WebAssembly扩充套件,让使用者够简单地将WebAssembly扩充套件部署到Envoy上。
WebAssembly Hub高度自动化了开发和部署WebAssembly扩充套件的步骤,使用WebAssembly Hub工具,使用者可以轻松地将任何支持的语言程式码,编译成为WebAssembly扩充套件,接着把这些扩充套件上传至Hub註册服务中,用户只要使用单个指令,就可以将扩充套件部署至Istio中。
Google提到,WebAssembly扩充套件与容器一样易于管理,能简单地安装以及执行。
WebAssembly Hub在背后处理了许多细节问题,像是ABI版本验证和权限控制等问题,而且也会自动扩展部署,减少跨Istio服务代理配置的麻烦,避免配置错误或是版本不符的意外错误。
目前Envoy支持WebAssembly的功能,仍在Alpha测试中,接下来开发团队会最终确定ABI,并将其转变为标准,以在标准组织中取得更广泛的回馈。另外,Google提到,他们会继续向Envoy上游项目提供支持,并且为相关工具以及WebAssembly Hub寻找适合的社群。
捷克新冠状病毒筛检中心遭黑客攻击
位于捷克第二大城布尔诺(Brno)的布尔诺大学医院,在上周传出遭到网络攻击,布尔诺大学医院不仅是当地的大学医院,也是捷克18个新冠状病毒(COVID-19)筛检中心之一,就在欧洲开始因新冠状病毒疫情的扩散,而造成医疗资源吃紧之际,此一攻击行动无疑令当地的防疫能力雪上加霜。
目前该大学医院尚未对外公布详细的资讯,只说该院的电脑系统在上周五(3/13)遭到攻击而陆续当机,最后只得将电脑系统关闭。外传医院员工还被交代不要开启电脑,而信息安全专家则推测,可能是遭到勒索软件攻击。
不过,由于布尔诺大学医院目前,正在筛检数十个可能罹患新冠状病毒的案例,原本一天就能取得结果,但因院方遭受攻击之故,相关筛检作业可能要拉长到数天。
信息安全业者Emsisoft针对美国勒索软件调查显示,去年前三季美国有621个组织遭到勒索软件攻击,当中就有491个隶属于健康医疗领域,老旧的系统再加上IT资源不足,都让医疗院所成为黑客的目标。而在此一全球对医疗资源需求甚殷的时刻,信息安全专家也只能再度奉劝医院提高警觉,及时修补所有系统的安全漏洞。
Slack修补了可用来接管大量帐号的安全漏洞
安全研究人员Evan Custodio在本周公布了一个存在于Slack上的安全漏洞,该漏洞将允许黑客接管大量的Slack帐号,不过,Custodio早在去年11月便透过HackerOne平台提报了该漏洞,Slack则在得知漏洞的24小时内完成修补,也颁发6,500美元的抓漏奖金予Custodio。
根据Custodio的说明,Slack平台上含有一个「HTTP 请求走私」(HTTP Request Smuggling)漏洞,将允许黑客针对邻近的客户请求,执行基于CL.TE的挟持行动,迫使受害者进入开放式重定向,把受害者及其Slack网域cookies转移到黑客的协作客户端,而当中即含有客户的秘密期间cookie,将使得黑客得以接管任何Slack用户的使用期间。
Custodio认为,这是一个严重的安全漏洞,将可曝露大多数的Slack用户资料,黑客可建立多个机器人以展开持续性的攻击,先是接管Slack用户的使用期间,进而窃取用户资料。
苹果、Google、微软及Amazon出面反对美国制定歧视LGBTQ族群的法案
包括Amazon、Google、微软、苹果、PayPal及IBM等逾40家企业,在本周连署了一份公开信,宣称它们拥护多样性与包容性,鼓励员工呈现真实的自我,因此反对美国订定各种歧视同性恋、双性恋、跨性别或不明性别等族群的法令。
此一公开信是由Freedom for All Americans(FFAA)所发起的,这是一个专门反对歧视LGBTQ族群的运动,该运动追踪并公布了美国各州所拟定的、与LGBTQ族群相关的法案,并邀请支持该运动理念的组织或企业参与。在FFAA所列出的歧视LGBTQ族群的数十个法案中,有的是LGBTQ希望推动的非歧视法案,也有些是针对LGBTQ族群所制定的不平等法案。
此一公开信表达了对LGBTQ族群的支持,指出不管是公平,或是平等的待遇与机会,都是企业最重要的价值观之一,他们关注那些不平等对待LGBTQ族群的法案,因为相关法案不仅会损害团队成员及其家人,剥夺他们的机会,也会让他们在社群中感到不受欢迎,甚至是处于危险当中。这些企业指出,某些州准备制定的LGBTQ歧视法案可能直接影响公司的业务,唿吁美国政府应该放弃或反对制定歧视性的法规,应该公平对待所有的美国人。
容器网络是如何影响Kubernetes中数据库性能的?
关于Kubernetes中的数据库,大家最关心的第一个问题是性能。由于这种担心的存在,许多使用Kubernetes进行生产应用程序工作的客户正在Kubernetes之外的裸机或VM上运行数据库。因此,我们致力于深入研究Kubernetes抽象层,确定值得测试的关键领域,并设计有用的基准。
我们从网络入手,因为由于需要在大多数Kubernetes环境中利用网络存储来提高弹性,因此网络对性能的影响很大。此外,我们知道联网一直是容器化领域不断挑战和改进的领域。最后,对于考虑将其数据库工作负载迁移到Kubernetes的人们来说,我们通常将性能视为网络采用的主要障碍,而将网络性能视为特定的主要障碍。拥有一个数据库到Kubernetes的桥梁是很有价值的,这使在这里运行生产工作负载更加可行。最后,我们想了解在Kubernetes中运行数据库所需的一切。
这篇博客文章直接基于这些努力的结果。
基准方法
为了进行此基准测试,我们试图建立一种方法来专门隔离尽可能多的变量,以专门研究网络如何影响性能。为此,我们确保使用的数据集适合内存,在执行运行之前预热所有缓存,在Kubernetes中利用本地存储,并执行足够的基准测试运行以消除可变性。我们还希望数据能够进行真正的比较,因此我们确保通过基础架构拓扑进行比较。
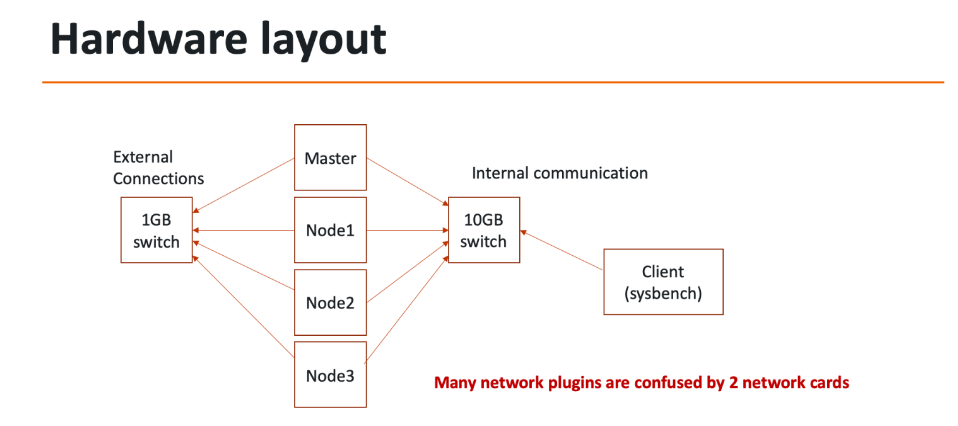
我们的测试数据中心内机柜中的五台物理服务器中的每台都连接到机架式10GbE和机架式1GbE交换机,该交换机包括位于单独IP子网中的两个单独的物理网络。五台服务器中的一台充当sysbench客户端,用于模拟工作负载,其余四台由Kubernetes和Database角色组成。在裸机测试期间,这三台服务器作为Kubernetes节点按原样运行,在Kubernetes测试期间,这三台服务器被部署为托管数据库Pod的节点,而第四台服务器被预留为仅充当Kubernetes Master。
为了部署Kubernetes环境,我们使用了kubeadm并尝试尽可能保持基本默认设置,以确保我们在测试中不会产生混杂因素。我们使用了Kubernetes 1.16。在Percona XtraDB群集5.7.27-31.39的基础上,使用Percona XtraDB群集的Percona Kubernetes Operator 1.2.0版本部署了Percona XtraDB群集。为了部署裸机环境,使用来自我们公共仓库的Percona XtraDB Cluster 5.7.27-31.39的Percona装运包手动执行安装。在这两种情况下,我们都禁用ProxySQL并将Percona XtraDB Cluster群集成员直接暴露给网络,并配置了sysbench客户端,以便所有流量仅定向到Percona XtraDB Cluster群集的单个成员。对于裸机测试和基于Kubernetes的测试,主机操作系统都是Ubuntu 16.04 LTS,该内核运行的内核版本为4.15.0-66(与Ubuntu 16.04 LTS一起提供)。
服务器中包含的硬件如下:

对于环境设置,我们按照提供的说明将每个CNI插件安装在Kubernetes的全新部署中,以确保它通过10GbE网络发送流量。我们使用sysbench和oltp读写工作负载运行数据库基准测试。此外,我们使用iPerf3捕获了网络吞吐量数据。为了确保数据库本身不是瓶颈,我们利用了经过优化的MySQL配置,该配置作为ConfigMap提供给Kubernetes Operator。最后,对于本地存储,我们利用Kubernetes中的HostPath方法来确保我们可以为数据库提供卷而不会越过网络边界,从而只有事务和复制工作负载会接触到网络。
我们调整的my.cnf如下:
[mysqld]
table_open_cache = 200000
table_open_cache_instances=64
back_log=3500
max_connections=4000
innodb_file_per_table
innodb_log_file_size=10G
innodb_log_files_in_group=2
innodb_open_files=4000
innodb_buffer_pool_size=100G
innodb_buffer_pool_instances=8
innodb_log_buffer_size=64M
innodb_flush_log_at_trx_commit = 1
innodb_doublewrite=1
innodb_flush_method = O_DIRECT
innodb_file_per_table = 1
innodb_autoinc_lock_mode=2
innodb_io_capacity=2000
innodb_io_capacity_max=4000
wsrep_slave_threads=16
wsrep_provider_options="gcs.fc_limit=16;evs.send_window=4;evs.user_send_window=2"
我们对Kubernetes中资源的调整设置如下:
resources:
requests:
memory: 150G
cpu: "55"
limits:
memory: 150G
cpu: "55"
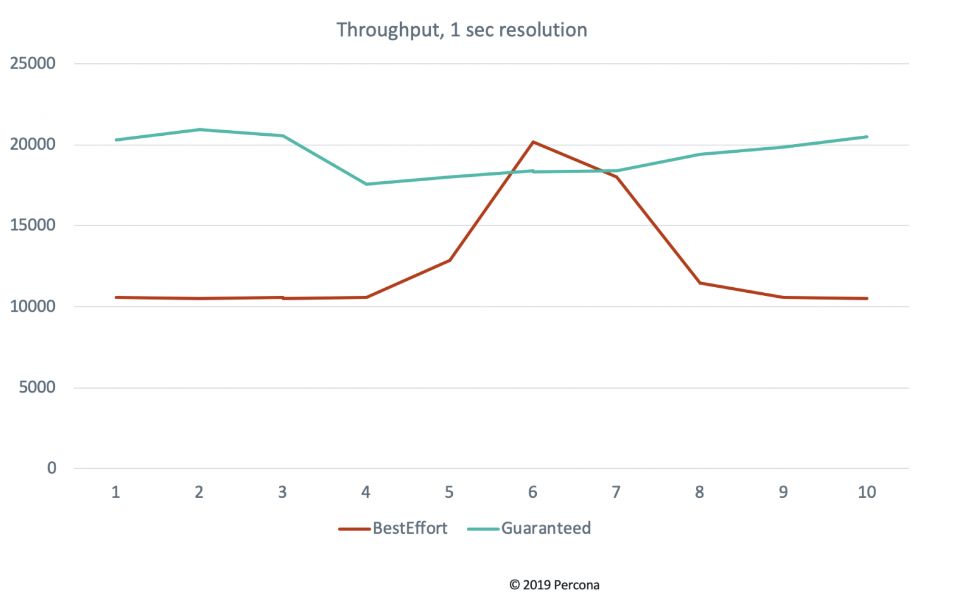
我们这样做是因为Kubernetes中的Pod资源服务质量(QoS)。Kubernetes根据Pod的请求和限制设置为Pod提供不同级别的QoS。在典型情况下,您仅指定请求块而不指定限制,Kubernetes使用“尽力而为QoS”,但是当为所有容器中的所有资源设置请求和限制并且它们相等时,Kubernetes将改为使用“保证的QoS”。这可能会对性能差异产生重大影响。
此外,您需要了解以下用于运行测试的sysbench命令行:
./sysbench --test=tests/db/oltp.lua --oltp_tables_count=10 -- oltp_table_size=10000000 --num-threads=64 --mysql-host=172.16.0.4 -- mysql-port=30444 --mysql-user=root --mysql-password=root_password --mysql-db=sbtest10t --oltp-read-only=off --max-time=1800 --max- requests=0 --report-interval=1 --rand-type=pareto --rand-init=on run
我们测试了哪些CNI插件
我们选择了CNI插件来进行测试,基于我们与客户和合作伙伴以及一些由于性能原因而特别有趣的参与者的经验。该列表没有特别的顺序,我们的目标不是总结使用哪个插件的具体建议。所有CNI插件的项目目标都不同,这导致它们进行不同的设计和工程折衷,这可能会对性能产生影响,但是根据您的环境,这些折衷可能是合理的。
Project Calico
由于其简单性,您可以将可路由IP分配给Pods并将其与您现有的机架式网络设备集成在一起,因此,Project Calico是许多进行内部部署的企业的热门选择。因此,我们测试了启用(默认)和禁用IP-in-IP的Calico。
Flannel
Flannel是带有Kubernetes的网络结构,支持可插入后端。默认后端基于UDP,但它也支持vxlan和host-gw后端。我们无法使host-gw正常工作,但是我们能够使用UDP和vxlan进行测试。
Cilium
Cilium是使用BPF和XDP的API感知网络和安全性。主要侧重于网络安全政策用例。它的安装非常简单,但是在可用的基准测试时间内,我们无法使其跨10GbE网络进行路由,这显然影响了性能结果。否则测试成功了,但请记住,我们仍在报告这些结果。
Weave (weave-net)
Weave是一个紧密集成且易于部署的多主机容器联网系统。尽管显示Pods已在我们的10GbE网络块中分配了IP,但流量仍在1GbE网络中路由。我们花费了大量时间来解决此问题,但在可用时间内无法解决。我们仍在报告这些结果。
Intel SR-IOV and Multus
Multus是一个CNI插件,可将多个网络接口附加到Pod。这是必需的,因为SR-IOV CNI插件不能是您唯一的Pod网络,它是默认Pod网络之外的附加接口。我们将Kube-Router用于默认的Pod网络,并为此测试分配了另一个10GbE网络上的SR-IOV接口。SR-IOV具有复杂的设置过程,但允许将大部分网络卸载到硬件,并有效地将硬件(VF)中的虚拟NIC分配给作为网络设备的主机上的每个Pod。从理论上讲,它应该具有接近线速的性能,因此值得尝试的复杂性。
Kube-Router
Kube-Router是Kubernetes网络的简单交钥匙解决方案。它也是kubeadm部署的默认插件,因此部署非常简单。最小的功能集所产生的开销很少,您将在结果中看到这一点。
结论
作为基准,我们首先在裸机上进行了测试,并表明我们的基准仅受网络性能的限制。在这些测试中,我们在1GbE上达到了2700 tps,在10GbE上达到了7302 tps。
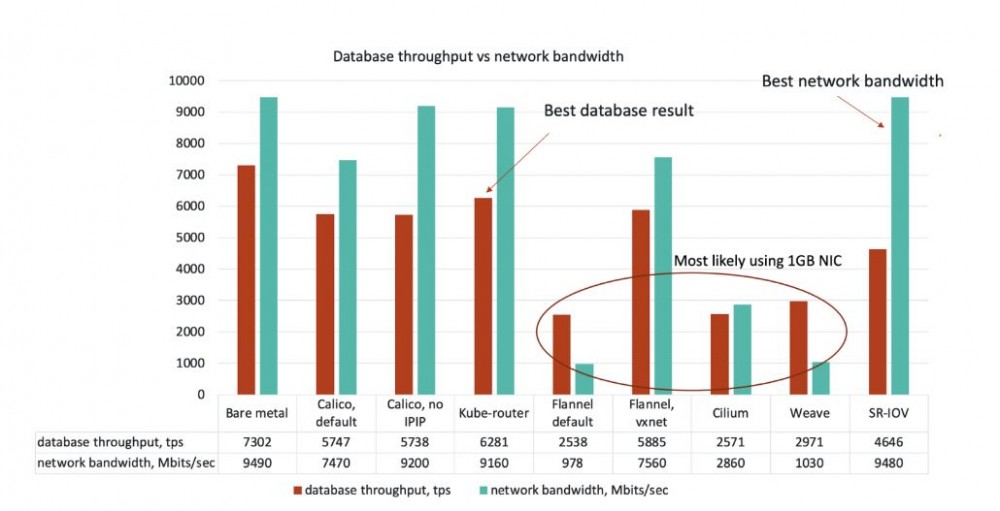
一个非常有趣的结果是,由iPerf3衡量的网络吞吐量与由sysbench衡量的数据库吞吐量之间的相关性强。SR-IOV打破了这种相关性,我们期望它是性能最好的。它具有接近裸机的网络吞吐量,但是大约是预期数据库吞吐量的一半。我们怀疑此结果与事务大小有关,这是由于SR-IOV固有的硬件虚拟化层内部发生延迟导致的,因此我们计划在将来的基准测试中验证这种怀疑。
我们发现的另一个关键问题是,即使在使用Kube-Router的最佳情况下,与在Kubernetes中运行裸机相比,我们也看到数据库性能下降了约13%。这说明在Kubernetes中仍需要对容器网络的性能进行改进。
Spectro Cloud获得750万美元融资,提升托管Kubernetes体验
Kubernetes是一个非常流行的容器管理平台,但是如果要使用它,则几乎必须在让别人为您管理它还是自己构建它之间进行选择。Spectro
Cloud脱颖而出,获得了750万美元的投资,并正致力于为您提供介于中间的第三种选择。
资金由Sierra Ventures领导,Boldstart Ventures参与。Boldstart创始人Ed Sim说,他喜欢Spectro
Cloud的团队和技术。Spectro
Cloud解决了每个大型企业都在努力解决的巨大难题:如何在托管平台上推出自己的Kubernetes服务,而又不依赖任何大型供应商。
Spectro联合创始人兼首席执行官Tenry Fu表示,企业不应该在控制和易用性之间妥协。“我们希望成为第一家为企业带来易于使用的托管Kubernetes体验的公司,同时也使他们能够灵活地大规模定义自己的Kubernetes基础架构堆栈,”
Fu解释说。
Fu说,在这种情况下,堆栈由Kubernetes版本的基础操作系统,存储,网络和其他层(如安全性,日志记录,监视,负载平衡或与Kubernetes相关的任何基础结构)组成。他解释说:“在企业内的组织内,您可以满足各个组的需求,就基础结构堆栈中的内容而言,可以降至相当细致的水平,因此您不必担心生命周期管理。”这是因为Spectro
Cloud会为您处理这些问题,同时仍为您提供控制权。
这为企业开发人员提供了更大的部署灵活性,并且使他们能够更轻松地在云基础架构提供商之间迁移,这是当今公司的头等大事,因为公司不想将自己锁定在一个供应商中。“存在一个基础设施控制连续体,迫使企业必须权衡这些需求。在一个极端情况下,托管产品围绕易用性提供了一种必杀技,但这是以控制您所处的云之类的东西或采用新的生态系统选项(例如Kubernetes的更新版本)为代价的。虽然还处于发展初期,但该公司一直在与16个Beta客户合作。
GNOME 3.36可提供基于Fedora 32 Beta Linux的操作系统
Fedora是Linux发行版之一。它不浮华,相反要稳定可靠。这就是为什么许多Linux用户在尝试其他发行版后,又回到Fedora的原因。GNOME的爱好者尤其喜欢Fedora,因为该操作系统是体验桌面环境的最佳方法之一。近日,Fedora 32 Beta可以进行测试了。它随GNOME 3.36一起提供最新、最好的桌面环境版本。如果您不是GNOME的粉丝,您可以选择KDE
Plasma,Cinnamon,MATE等。甚至还有Fedora 32的特殊ARM变体,可与Raspberry Pi设备一起使用。
“ Fedora 32 Workstation
Beta中的新增功能默认情况下启用EarlyOOM。EarlyOOM使用户可以在低内存情况下通过频繁交换使用来更快地恢复并重新获得对系统的控制。Fedora32
Workstation Beta默认还启用fs.trim计时器,可以改善固态硬盘的性能和磨损平衡。” Fedora项目的Matthew Miller说。
Miller进一步说:“ Fedora 32
Beta包含许多流行的软件包的更新版本,例如Ruby,Python和Perl。它还包含流行的GNU编译器集合(GCC)的版本10。我们还对底层基础结构软件进行了常规更新,例如GNU
C库。”但是,在安装Fedora 32
Beta之前,请记住这是一个预发行的操作系统。它很可能包含错误,可能会导致潜在的数据丢失。建议在安装之前,先通读并了解已知错误信息。
微软发布VS Code Docker扩充套件1.0
微软推出Visual Studio Code的第一个Docker扩充套件主要版本,这个新版本更好地支持Python网页框架,并且为Python和.NET
Core开发人员,提供与Node.js相同的Compose支持,开发者使用Docker扩充套件建构、执行和除错容器化应用程序,将会更简单。
回应开发人员的建议,微软提升Docker扩充套件对Python网页框架Django与Flask的支持程度,由于当工作区添加Docker档案时,开发者可以选择要使用Django或是Flask,而现在系统会自动架构出Dockerfile、除错任务以及启动配置。微软提到,Docker扩充套件仍会继续支持一般选项,供开发者取得更通用的Dockerfile。
Docker扩充套件现在支持使用Compose.yml档案或是Dockerfile。微软表示,当用户只需要启动带有少量参数的单一容器,可以仅使用Dockerfile,但是要一次启动一个以上的服务,或是要启动一个服务,但是要修改多个Docker执行参数,就可以使用Docker
Compose。除此之外,Docker扩充套件针对Node.js、Python和.NET
Core开发语言,支持使用Dockerfile对单一服务进行整合性除错。
在这个新版本中,用户可以自定义各种命令,像是执行映像档时,指定扩充套件将产生的容器放置在特定的网络上等。最多使用者要求的更新,是希望在执行像是启动、停止或是删除映像档等命令时,可以一次选择多个容器或是映像档,因此微软这次新增了功能,让用户可以一次选择多个容器或映像档,并从右键选单选择要对选定项目执行的命令。
另外,当用户执行包含WSL 2(Windows Subsystem for Linux 2)的Windows版本,可以在Docker
Desktop中启动WSL 2实验引擎,该引擎会以WSL
2执行,而非使用HyperV执行Linux容器,微软表示,他们从Docker扩充套件0.9版本开始,就支持并且鼓励使用WSL 2。
IBM今年力推6大云原生软件产品组合Cloud Paks
IBM完成红帽并购案后,去年秋季发布并以非正式方式向媒体介绍了全新云原生软件产品组合Cloud
Paks,以容器化技术将软件整合为多组解决方案。近日,IBM在线上举办的记者会,正式介绍了这个以套餐形式设计的云端软件产品组合。IBM今年重要策略宗旨是,以认知型企业(Cognitive Enterprise)混合多云平台为核心,提供IBM Cloud Paks、Red
Hat、IBM Cloud的解决方案。在IBM完成红帽并购案后,IBM将既有的软件平台与红帽产品线进行整合,推出6个Cloud
Paks,涵盖了企业客户端到端的整个数字化转型过程,所需要的产品线与服务。他更提到,在数字化转型过程中,企业面临混合多重云是必然的趋势。
IBM Cloud Paks包括的6大产品线,分为应用程序开发解决方案Cloud Pak for
Applications、自动化资料分析解决方案Cloud Pak for Data、整合套件组Cloud Pak for
Integration、流程自动组Cloud Pak for Automation、混合云管理解决方案Cloud Pak for Multicloud
Management,这前5项都在去年秋季已在国外发布,新增的第6个信息安全解决方案Cloud Pak for
Security,是IBM去年第四季的最新发布。
Gartner:企业短期抗疫推BCP得留意细节
新冠状病毒全球大流行的现状直接冲击了企业的营运表现,不少企业早已订定了一套营运持续计划(BCP),或因应疫情,紧急订定,不过,Gartner
在最近一场研讨会中提醒,企业订定BCP得留意许多细节,例如不同因应情境的时间单位不一样。Gartner建议,BCP应加入时间的概念,即时反应以小时为单位、復原措施则可以天数衡量、另外还要有以周或月为单位的长期应对策略,并在事件发生后的不同时间内,执行对应的措施;企业应该认知到,整体反应时间不断缩短。比如过去核心系统中断,还能容忍以天为单位的修復时间,但现在就算赶在几个小时内修復,也可能不被业务单位所接受。
另外,订定BCP的同时,也要一并考量到触发应变措施的条件,以及负责执行者,来减少应变过程中的不确定性,以及因不确定性而导致的决策缓慢,才不会错过最佳执行计划的时机。同时,设定明确的触发条件也更易于与员工沟通。Gartner举例,比如设定1位员工病毒检测阳性,就触发对应的计划。
营运持续计划(BCP)是企业风险管理的一环,但令人沮丧的事实是,许多企业并无意识到风险管理的重要性。Gartner观察,部分企业的风险管理业务没有指定负责人、负责人经验也不足,也并非因自身业务需求去评估风险,反而是受到外部法规所驱动,甚至没有订定系统性的营运持续计划;再者,绝大多数利益相关者缺乏相关意识,就算有计划,也未展开压力测试和相关演习。
对于企业被动、缺乏组织性的风险管理现况,Gartner建议,企业应根据自身所属行业、地理位置等面向进行风险评估,订定出适合自己的营运持续计划,比如根据B2B或B2C的业务类型、容易发生地震或颱风的地理位置属性不同,对业务的影响也不同,需要确实评估与分析;接着,应先拟定大方向的復原策略、再进一步订定细节,若预设的情境真实发生,就须确实执行计划,若没发生,也应定期安排演习,并持续透过测试来改进流程。
面对新冠状病毒疫情,许多企业要在短期内维运远距工作的IT环境,比如确保员工能连线到公司并维持工作效率、确保远距办公的资讯安全,或实践IT维运的A、B分组机制等。不过Gartner也表示:CIO除了基本的IT支持,应向更多长期的IT维运面向来进行探索。
比如说,企业面对疫情,可能会走向数字化化业务与数字化生态系,或是改为采用RPA等自动化技术,甚至因疫情长期对供应链的冲击,可能因供应链转移、流动到其他地区,引发企业并购等重新配置的状况。面对企业在疫情中可能发展出的新商业模式、工作流程、或客户的新需求,IT系统是否有足够的弹性来因应?这是CIO可以趁这一波疫情思考的问题。Gartner表示。
Gartner的一篇报告中也举例,部分企业制造业已经根据疫情需求来调整产品类型。比如日本电子产品制造商夏普(Sharp),将其中一家工厂改为制作口罩;而中国富士康,也将其部分因疫情而需求低迷的传统产品,改为生产需求更高的产品,如防护装备等。这都是快速因应新商业模式而做出改变的案例。
因此,Gartner也建议,企业可以藉着疫情来加速数字化转型,比如导入敏捷开发流程,来改变企业内部文化与工作方式,之前一直没机会做的,现在是一个好机会,将一些新的工作方式、新的思维方式进行实践,来提升整个团队、企业的能力,帮助企业在危机中胜出。
在IT预算上,多数CIO为了因应疫情对企业造成的冲击,已经规划缩减IT预算来降低企业整体营运成本。不过,Gartner指出,企业IT成本通常占整体企业的2~10%,就算消减IT预算,对企业的效果有限,因此,CIO也可以思考如何进行成本优化、甚至价值优化,来更有效的提升业务流程的效率与价值。
首先,在IT成本降低方面,CIO可能采取的作法,包括停办一些培训、供应商活动,或降低顾问的支出,也可能对员工进行交叉培训,让每位员工获得更多技能,来减少员工数的增长;其他作法,还包括推迟大型IT项目的建置,或是减少员工奖金的发放,来直接降低IT预算。不过,CIO也能进一步思考,如何透过IT来提升业务流程的效率与生产力,帮企业降低整体业务的预算支出。比如投资远距工作、协作工具、安全工具,或是评估业务上云的可能,来实际增加业务效率,并降低业务本身执行的成本。甚至,CIO还能藉此理清业务对IT的需求。最后一步,则是直接透过IT来赋予业务新价值,达到价值的优化。
对此,Gartner也提醒,CIO要制定预算缩减计划时,也要根据可能发生的场景来订定多种方案,比如以预算缩减比例为指标,在需要缩减不同比例的预算时,采取对应的措施,随着情况不同而调整。
CIO面对新冠状病毒疫情冲击,可能需要缩减IT预算,但除了预算的直接缩减,用IT来提升业务效率与生产力,进而减少业务的预算支出,也是一种解方。
微软Windows 10安装数终于达到10亿
微软在2015年正式推出Windows
10操作系统,它除了成为所有微软装置的操作系统之外,也透过定期的更新来取代名称的世代更迭,当时微软发下豪语,要在2017年中让Windows
10的全球安装数量达到10亿,不过,微软一直到本周才抵达此一目标,迟到了近3年。现在的Windows
10不只被安装在个人电脑上,它也是Xbox游戏机、Surface装置、及HoloLens所使用的平台,根据微软的统计,有超过1,000家的制造商,生产了超过8万款不同配置的Windows
10笔电与二合一装置。此外,在财富杂誌《Fortune》的全球五百大企业中,全部都使用了Windows 10装置。在Windows
10问世之后,微软放弃了每三年进行大改版并更名的Windows开发策略,而是一年进行数次的功能与安全更新。而微软在今年发表的、基于Chromium的Edge浏览器,未来将能独立更新,也能支持更多版本的Windows。在达到10亿的安装门槛之后,微软承诺未来将继续投资各种版本的Windows 10,不管是供PC使用的,或者是Windows IoT、Windows 10
Teams edition for Surface Hub、Windows Server、Windows Mixed Reality on
HoloLens、Windows 10 in S mode或Windows 10X,以满足不同客户的需求。
七家科技大厂发表共同抵抗新冠状病毒的联合声明
Google、脸书、微软、Linkedin、reddit、Twitter与YouTube等网络平台,在本周发表了联合声明,承诺它们将与全球的政府医疗机构合作,递送与新冠状病毒(COVID-19)相关的正确资讯,并扫盪不实资讯,共同捍卫全球社群的健康与安全。声明的内容简单扼要,表示将在有关新冠状病毒(COVID-19)的应对上彼此合作,包括协助数百万的人们彼此联繫,也会共同对抗COVID-19病毒的诈骗与不实资讯,在各自的平台上突显官方的内容,也会与全球政府的医疗机构合作发布重大的资讯更新,亦邀请其它的企业参与,以共同捍卫人们的健康与安全。其实早在发表此一声明之前,各大科技业者都已针对新冠状病毒疫情采取了行动,例如脸书与Twitter都已禁止了可能造成伤害的不实内容,Google也宣布要移除搜寻结果与YouTube的不实内容,Google更于本周宣布要设立一个有关疫情的资讯网站,而微软则推出了新冠状病毒疫情追踪地图网站。业者的共同声明替各内容平台带来了一个因应疫情的准则,避免不实资讯的传递,或造成民众的恐慌。
Khronos推开放跨平台Vulkan光线追踪加速功能
多媒体标準制定组织Khronos发布了Vulkan光线追踪(Ray
Tracing)临时扩展,而这是第一个开放、跨供应商与跨平台的光线追踪加速框架。开发者社群可在最终规格确定之前,提供回馈帮助官方进行调整。
Vulkan是一个开放免版税的的高效能绘图API,可跨平台取用GPU资源,现在已经于许多热门的游戏引擎、游戏以及应用程序中支持。Vulkan在2015年的游戏开发者大会中发表,要提供与Direct3D和OpenGL类似的功能,与两者不同的是,Vulkan是一个底层API,可以良好地使用多个CPU核心,更擅于处理平行任务。Vulkan支持非常广泛的平台,包括各式个人电脑、行动装置以及嵌入式操作系统。
Khronos现在发布的Vulkan光线追踪临时扩展,可以满足桌面电脑,对即时与离线光线追踪的需求。光线追踪是一种图像渲染技术,可以真实地模拟光线与场景几何图形、材质与光源互动的情况,以产生逼真的场景渲染图。这项技术被广泛的应用在电影以及艺术作品中,随着硬体运算能力的提升,这项技术也逐渐在即时应用程序和游戏中实作。
Vulkan光线追踪扩充将光线追踪框架无缝地整合进Vulkan
API,开发者现在可于多媒体应用中,灵活地合併使用光栅化(Rasterization)与光线追踪来渲染画面。Vulkan光线追踪扩充经特别设计,使其运算无关硬体,因此可用在现有GPU和光线追踪专用核心上,进行光线追踪加速运算。Khronos的Vulkan光线追踪任务小组负责人Daniel
Koch提到,开发人员对于跨平台光线追踪加速API有很高的需求,而现在推出的Vulkan光线追踪扩充则能满足这些需求。
Vulkan光线追踪的整体基础架构,与市面上现存的专有光线追踪API相似,但Vulkan光线追踪框架有更多新的功能与实作弹性,开发者可简单地进行移植。新框架由一系列Vulkan、标準移植中介表示语言SPIR-V(Standard
Portable Intermediate Representation)与GLSL扩充组成,并非所有扩充都是必要元件,部分扩充为可选项目。
而Khronos也在Vulkan光线追踪扩充中,增加对微软开源HLSL编译器的支持,让开发者可做最少的修正,就能使用微软定义的语法,在HLSL中编写Vulkan光线追踪SPIR-V着色器相关程序码。官方提到,当所有相关的元件都更新到上游,包含光线追踪扩充的Vulkan
SDK就会释出。
BitDefender强化端点进阶威胁侦测
端点防护发展至今,许多防毒厂商都在端点防护平台(EPP)之外,提供了端点侦测与回应(EDR)的模组。但也有厂商并非将EDR视为独立产品,而是纳为端点防毒产品套餐的进阶功能,像是BitDefender
就提供含有这种模组的GravityZone Ultra,让企业能够同时取得防毒和EDR的保护能力。
针对端点电脑的威胁侦测与回应,这组套件提供的功能,包括了事件记录、威胁分析,以及比对IoC特徵。以事件调查而言,该系统采用黑名单及网路隔离,除了图像化的分析功能与黑名单封锁机制,若是资安人员想要运用沙箱检测来分析档案是否被植入恶意软体,这裡提供云端沙箱做为模拟触发的环境。GravityZone
Ultra近期的改版,也持续强化威胁的侦测,可防御网路攻击、异常行为,以及无档案攻击等面向。举例来说,面对基于网路流量的攻击行为,GravityZone
Ultra能藉由多种面向来加以侦测,进而在攻击发生之前封锁。
而在异常行为的侦测上,GravityZone Ultra不只能搭配BitDefender定义的入侵指标,也整合了MITRE
ATT&CK攻击框架的知识库,能自动标记需要特别留意的现象。至于无档案攻击的防御,这套系统则是针对透过任何命令转译器的攻击行为,例如近期时有所闻的PowerShell无档案攻击,增加额外侦测的功能,以便在执行之前封锁。
值得一提的是,对于Windows端点电脑是否存在含有风险的设置,塬厂在GravityZone Ultra套餐中,纳入Endpoint Risk
Analytics(ERA)模组,以供资安人员快速判读端点电脑是否安全。这项模组针对3种面向,进行解析,分别是网页浏览器安全、网路设置,以及操作系统安全基準等。
以网路设置的部分而言,该模组会检查是否存在没有设置密码的使用者帐号,或者电脑是否连接网域等,以求端点电脑能符合资安政策的要求配置。而在ERA裡,也针对Office巨集的设定,以及上网应用程序存放凭证等,判断电脑是否存在风险。
Amazon Elastic Inference新增支持PyTorch机器学习模型
AWS现在让用户可以在机器学习服务Amazon SageMaker以及运算服务Amazon EC2中,以Amazon Elastic
Inference服务运用PyTorch模型进行预测,而由于Elastic
Inference可让用户附加适当的GPU运算资源,不只能够用GPU加速预测工作,付出的成本也低于使用独立GPU执行个体。PyTorch是脸书在2018年底释出的深度学习框架,由于其采用动态运算图(Dynamic Computational
Graph),因此可让开发者简单地运用指令式程序设计方法,以Python开发深度学习模型,AWS提到,使用PyTorch这类框架开发深度学习应用程序,预测阶段可占全部运算资源的90%。
要为执行预测工作,选择适当的执行个体规格并不简单,因为深度学习模型需要不同数量的GPU、CPU和记忆体资源。使用独立GPU执行个体通常过于浪费,虽然速度很快,但因为独立GPU执行个体通常为模型训练工作设计,而大多数预测工作通常都只会是单一输入,即便是尖峰负载也不会用上所有GPU容量,因此可能会造成资源浪费。
Amazon Elastic Inference可让用户在SageMaker和EC2执行个体,附上适当的GPU资源来加速预测工作。因此用户可以选择应用程序需要的CPU和记忆体规格的执行个体,并且额外附加适当的GPU容量,以更有效的方式使用资源,并且降低预测成本。Amazon Elastic Inference服务之前只支持TensorFlow和Apache MXNet框架,而现在还额外多支持PyTorch。
要把PyTorch用在Elastic
Inference中,必须要把模型先转换成TorchScript格式。TorchScript是可将PyTorch程序码转换成序列化与最佳化模型的方法,AWS表示,因为PyTorch使用动态运算图大幅简化模型开发的过程,但是这种方法同时也增加模型部署的困难,在生产环境中,模型以静态图(Static
Graph)表示较佳,不只使模型可以在非Python环境中使用,而且还可以最佳化其效能和记忆体使用量。
TorchScript便可编译PyTorch模型,使其以非Python的方式表示,能在各种环境中执行,TorchScript也会对模型进行即时(Just-In-Time)图最佳化,使编译过的模型比起塬本的PyTorch模型效能还要好。
AWS比较附加Elastic
Inference、独立GPU与纯CPU叁类型执行个体的延迟与成本。CPU执行个体效能较差,预测延迟最长。独立GPU执行个体的预测效能则最好,速度约是CPU执行个体的7倍。而有使用Elastic
Inference的CPU执行个体,因为获得GPU的加速,虽然预测速度仍然比独立GPU执行个体慢,但是比纯CPU执行个体快了近3倍。
而在成本上,纯CPU执行个体的每次预测成本最高,AWS解释,虽然CPU执行个体每小时的成本最低,但因为每次预测的时间较长,反使得单次成本较高,而每次预测价格最低的则是Elastic Inference,还可灵活地分离主机实体和推理加速硬体,组合出最适合应用程序的运算资源。
正文到此结束
- 本文标签: 笔记本电脑 安装 JavaScript 数据 ioc API Haproxy 注释 Vmware vSphere 工程师 HTML apache 注册中心 实例 翻译 覆盖率 快的 windows 开源 VMware 企业 统计 进程 富士康 医院 python map 开发者大会 黑客 Service 管理 IO 时间 mysql 专注 App update bus DOM 协议 微服务 软件 cmd 苹果 质量 Powershell 负载均衡 core 美国 删除 集群 NOSQL Security 开源软件 Go语言 领导 NIO 需求 正则表达式 模型 CTO ssh 架构设计 parse 编译 单元测试 插件 IBM 总结 maven Uber 投资者 src 数据库 http 网站 Enterprise message 开发者 Twitter 开源项目 深度学习 代码 linux 高可用 CEO java 权限控制 解析 服务器 缓存 组织 tab 2019 锁 自动化 Amazon js lib 银行 W3C cat ACE sql 免费 UI 黑客攻击 NSA 本土化 GitHub id 空间 Ubuntu Lua Cassandra 站点 Proxy 敏捷 认证 部署 开发 db 同步 https build 财富 主机 产品 Office 安全 2015 基金 beta测试 漏洞 cache Node.js 应用架构 创始人 目录 Dockerfile google cloud Nginx cookies 谷歌 源码 rand 操作系统 node 微博 git Connection 科技 ask 资金 Word 政策 下载 金融 处理器 微软 ORM OpenStack Master UDP 云 病毒 Kubernetes root Pods Docker 测试 tk 缩小 cvs provider ip 回报 tar 推广 装备 生命 密钥 文章 配置 投资人 IDE 业务层 Google 希望 TCP 虚拟化 本质 Android web Dashboard 红帽 定制 加密 参数 端口 shell 投资 合伙人 运营 压力 博客 apr
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
666
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
-
-
-
-
-
-
-
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

