一篇文章带你深入了解Java集合
二、数组和集合的区别
- 数组在存储多个数据方面的特点:
- 数组一旦初始化好之后,其长度就已经确定了
- 数组声明的类型,就决定了进行元素初始化时的类型,也就只能操作指定类型的数据了。例如:
String[] arr;int[] arr1;Object[] arr2;
- 数组能存放基本数据类型和对象,而集合类中只能放对象。
- 数组在存储多个数据方面的弊端:
- 一旦初始化以后,其长度就不可修改,不便于扩展,集合类容量动态改变。
- 数组存储的数据是有序的、可以重复的,对于无序、不可重复的需求,不能满足---->存储数据的特点单一
- 数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
- 数组无法判断其中实际存有多少元素,length只告诉了array的容量就是数组的长度。 而集合size()方法可以知道容器中存放了多少个数据 ,而不是集合的长度
三、Java集合框架的概述:集合的使用场景
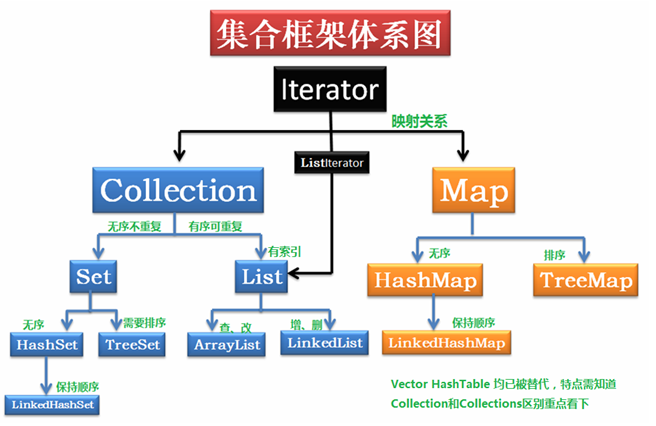
四、集合框架
Java集合可分为 Collection 和 Map 两种体系
- Collection 接口 :单列数据,定义了 存取一组对象 的方法的集合
- List:元素有序、可重复的集合
- Set:元素无序、不可重复的集合
- Map 接口:双列数据,保存具有映射关系“key-value对”的集合
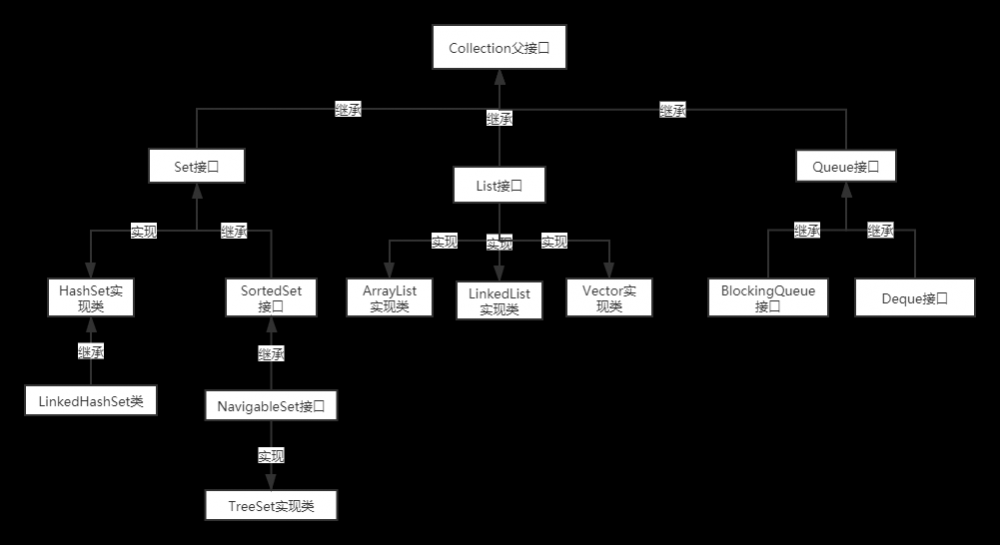
Collection接口继承树
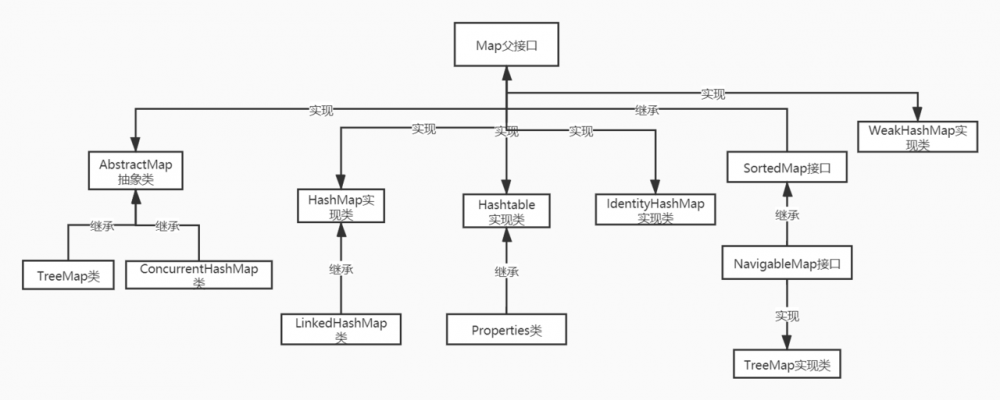
Map接口继承树
五、Collection接口方法
5.1、Collection接口
- Collection 接口是 List、Set 和 Queue 接口的父接口,该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)实现。
- 在 Java5 之前,Java 集合会丢失容器中所有对象的数据类型,把所有对象都当成 Object 类型处理; 从 JDK5.0 增加了 泛型 以后,Java 集合可以记住容器中对象的数据类型。
- Collection中存储的如果是自定义类的对象时,类中需要重写equals()方法
5.2、Collection接口方法
-
添加
add(Object obj):添加一个元素addAll(Collection coll):添加coll集合中的所有元素 -
获取有效元素的个数
int size() -
清空集合
void clear() -
是否是空集合
boolean isEmpty() -
是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象;obj对象需要重写equals()方法boolean containsAll(Collection c):也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。obj对象需要重写equals()方法 -
删除
boolean remove(Object obj): 通过元素的equals方法判断 是否是要删除的那个元素。只会删除找到的第一个元素;obj对象需要重写equals()方法boolean removeAll(Collection coll):取当前集合的差集 -
取两个集合的交集
boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c -
集合是否相等
boolean equals(Object obj):obj对象需要重写equals()方法 -
转成对象数组
Object[] toArray() -
获取集合对象的哈希值
hashCode() -
遍历
iterator():返回迭代器对象,用于集合遍历
5.3、Iterator迭代器接口(遍历集合元素)
-
Iterator对象称为迭代器(设计模式的一种), 主要用于遍历 Collection 集合中的元素
-
Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
-
Iterator 仅用于遍历集合,Iterator 本身并不提供承装对象的能力。如果需要创建Iterator 对象,则必须有一个被迭代的集合
-
集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。给个案例如下:
public class Test { public static void main(String[] args) { Collection coll = new ArrayList(); coll.add(123); coll.add(345); coll.add(456); //错误方式: //集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。 while (coll.iterator().hasNext()){ System.out.println(coll.iterator().next());//死循环 } } } 复制代码
5.4、Iterator迭代器接口的方法(jdk1.8之后的增加了default方法)


在调用it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常。代码如下:
public class Test {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(123);
coll.add(345);
coll.add(456);
//错误方式:
Iterator iterator = coll.iterator();
while((iterator.next()) != null){
System.out.println(iterator.next());//这里会抛出NoSuchElementException异常
}
}
}
复制代码
结果如下(会出现以下异常问题):
345 Exception in thread "main" java.util.NoSuchElementException at java.base/java.util.ArrayList$Itr.next(ArrayList.java:969) at com.bjsxt.demo12.Test.main(Test.java:20)
5.5、Iterator迭代器的执行原理

5.6、Iterator接口中的remove()方法
public class Demo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Iterator<Integer> ite = list.iterator();
while (ite.hasNext()) {
if (1 == ite.next()) {
//迭代器中的remove方法
ite.remove();
}
}
System.out.println(list);//[2,3,4,5]
}
}
复制代码
-
注意:
-
Iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。
-
如果还未调用next()或在上一次调用 next 方法之后已经调用了 remove 方法,再调用remove都会报IllegalStateException。案例如下:
public class Test { public static void main(String[] args) { Collection coll = new ArrayList(); coll.add("张三"); coll.add("李四"); coll.add("王五"); //错误方式: Iterator iterator = coll.iterator(); while(iterator.hasNext()){ //iterator.remove();这里会报IllegalStateException异常 Object o = iterator.next(); if ("张三".equals(o)){ iterator.remove(); //iterator.remove();这里会报IllegalStateException异常 } } } } 复制代码
5.7、使用foreach循环遍历集合元素
- Java 5.0 提供了 foreach 循环迭代访问 Collection和数组。
- 遍历操作不需获取Collection或数组的长度,无需使用索引访问元素。
- 遍历集合的底层调用Iterator完成操作。
- foreach还可以用来遍历数组。

-
使用foreach循环需要注意的点:
public class ForTest { @Test public void test1() { String[] arr = new String[]{"MM", "MM", "MM"}; //方式一:普通for循环赋值 // for (int i = 0; i < arr.length ; i++) { // arr[i] = "GG"; // } //打印,结果如何 // for (int i = 0; i < arr.length ; i++) { // System.out.println(arr[i]); // // /** // * 打印结果如下:成功赋值,改变的数组的值 // * GG // * GG // * GG // */ // } //方式二:增强for循环 for (String s : arr) { s = "GG"; } //打印,结果如何? for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); /** * 打印结果如下:没有成功赋值,原因:foreach循环底层采用Iterator迭代方式, * 将遍历出来的值赋值给变量s,只是改变变量s的值,其数组的值是没有变的 * MM * MM * MM */ } } } 复制代码
5.8、Collection集合与数组之间的转换
-
数组转集合
Arrays.asList(T ...);代码如下:public class CollectionTest { @Test public void test4() { List<String> list = Arrays.asList(new String[]{"aa", "bb", "cc"}); System.out.println(list); /** * 打印结果如下: * [aa, bb, cc] */ } } 复制代码 -
集合转数组
coll.toArray();代码如下:public class CollectionTest { @Test public void test4() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Jerry", 20)); coll.add(new String("Tom")); coll.add(false); Object[] arr = coll.toArray(); for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); /** * 打印结果如下 * 123 * 456 * Person{name='Jerry', age=20} * Tom * false */ } } 复制代码 -
数组转集合需要注意的点,代码如下:
public class CollectionTest { @Test public void test4() { List<int[]> list1 = Arrays.asList(new int[]{1, 2, 3, 4}); //出现了该问题,把上面只当成了一个数据[[I@3f0ee7cb],因为上面的元素为int类型的1、2、3、4而不是对象没有装箱,然而它就把整体当作一个对象进行存储 System.out.println(list1); //长度只为1,而不是4 System.out.println(list1.size()); //解决方法如下: List<Integer> list2 = Arrays.asList(new Integer[]{1, 2, 3, 4, 5}); //上面的元素均为Integer包装类对象进行存储 System.out.println(list2); } } 复制代码
六、Collection子接口之一:List接口
6.1、List接口
- 鉴于Java中数组用来存储数据的局限性,我们通常使用List替代数组
- List集合类中 元素有序、且可重复 ,集合中的每个元素都有其对应的顺序索引。
- List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
- JDK API中List接口的实现类常用的有:ArrayList、LinkedList和Vector。
6.2、List接口方法
List除了从Collection集合继承的方法外,List 集合里 添加了一些根据索引来操作集合元素的方法。
void add(int index, Object ele) boolean addAll(int index, Collection coll) Object get(int index) int indexOf(Object obj) int lastIndexOf(Object obj) Object remove(int index) Object set(int index, Object ele) List subList(int fromIndex, int toIndex)
6.3、List实现类之一:ArrayList
-
ArrayList 是 List 接口的主要实现类
-
ArrayList存储有序的、可重复的数据
-
ArrayList底层使用Object[] elementData存储,也可以说是一个”动态“数组,长度是可以变的
-
ArrayList线程不安全的,查询、获取数据效率高
-
ArrayList 的JDK1.8 之前与之后的实现区别?
JDK7情况下:
-
ArrayList list = new ArrayList();//底层初始化时创建了长度是10的Object[]数组elementData -
list.add(123);//添加元素相当于elementData[0] = new Integer(123); -
list.add(124);// 如果此次的添加导致底层elementData数组容量不够,则扩容。 默认情况下,扩容为原来的容量的1.5倍 ,同时需要将原有数组中的数据复制到新的数组中。 - 结论:建议开发中使用带参的构造器:
ArrayList list = new ArrayList(int capacity)
JDK8中ArrayList的变化:
-
ArrayList list = new ArrayList();//底层Object[] elementData初始化为{}.并没有创建长度为10的数组 -
list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到elementData[0] -
后续的添加和扩容操作与jdk 7 无异
-
结论:jdk7中的ArrayList的对象的创建类似于单例的饿汉式
jdk8中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
-
-
Arrays.asList(…) 方法返回的 List 集合,既不是 ArrayList 实例,也不是Vector 实例。 Arrays.asList(…) 返回值是一个固定长度的 List 集合
6.4、List实现类之二:LinkedList
- LinkedList存储有序的、可重复的数据,线程是不安全的
- LinkedList是 List 接口的实现类
- LinkedList对于频繁的插入、删除操作,使用此类效率比ArrayList高
- LinkedList底层使用双向链表存储
6.5、新增方法
void addFirst(Object obj) void addLast(Object obj) Object getFirst() Object getLast() Object removeFirst() Object removeLast()
6.6、LinkedList的概述
-
LinkedList: 双向链表,内部没有声明数组,而是 定义了Node类型的first和last ,用于记录首末元素。同时,定义内部类Node,作为LinkedList中保存数据的基本结构。Node除了保存数据,还定义了两个变量: prev变量记录前一个元素的位置 next变量记录下一个元素的位置,源码如下:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } 复制代码
6.7、List实现类之三:Vector
- Vector存储有序的、可重复的数据
- Vector是List接口古老的实现类,在jdk1.0就有了
- Vector线程安全的,效率低;
- Vector底层使用Object[] elementData存储数据
- 在各种list中,最好把ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList;Vector总是比ArrayList慢,所以尽量避免使用
- Vector在jdk7和jdk8中通过Vector()构造器创建对象时,底层都创建了长度为10的数组。 在扩容方面,默认扩容为原来的数组长度的2倍。
6.8、新增方法
void addElement(Object obj) void insertElementAt(Object obj,int index) void setElementAt(Object obj,int index) void removeElement(Object obj) void removeAllElements()
6.9、ArrayList、Vector、LinkedList三者中的区别
-
ArrayList和LinkedList的异同:
相同点:二者都线程不安全,相对线程安全的Vector,执行效率高。都是List接口的实现类,都可以存储有序、可重复的数据
不同点:ArrayList是实现了基于动态数组的数据结构,每次扩容为原来容量的1.5倍;LinkedList基于链表的数据结构,不需要扩容;ArrayList对于查询、获取数据效率高,因为LinkedList需要移动指针;LinkedList对于频繁的插入、删除操作,效率比ArrayList高,因为ArrayList要移动数据
-
ArrayList和Vector的异同:
相同点:存储有序的、可重复的数据;都是List接口的实现类;都实现了基于动态数组的数据结构
不同点:ArrayList是实现了基于动态数组的数据结构,每次扩容为原来容量的1.5倍;Vector是实现了基于动态数组的数据结构,每次扩容为原来容量的2倍;ArrayList是线程不安全的,Vector是线程安全的;
ArrayList查询效率比Vector要高
7.0、关于以上总结知识,面试题(区分list中的remove(int index)和remove(Object obj))
public class ListExer {
@Test
public void testListRemove() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
updateList(list);
System.out.println(list);
}
public void updateList(List list) {
//该remove方法调用的是remove(int index)方法;该如何调用remove(Object obj)方法呢?
list.remove(2);
//解决方法:使用包装类,将它转换成包装类Integer类型
list.remove(new Integer(2));
}
}
复制代码
七、Collection子接口之二:Set接口
7.1、Set接口
- Set接口是Collection的子接口, set接口没有提供额外的方法 ,使用的都是Collection中声明过的方法。
- Set接口存储 无序 的、 不可重复 的数据
- 对于存放在Set容器中的对象, 对应的类 一定要重写equals() 和hashCode(Object obj) 方法 ,以实现对象相等规则 。即: “ 相等的对象必须具有相等的散列码 ”
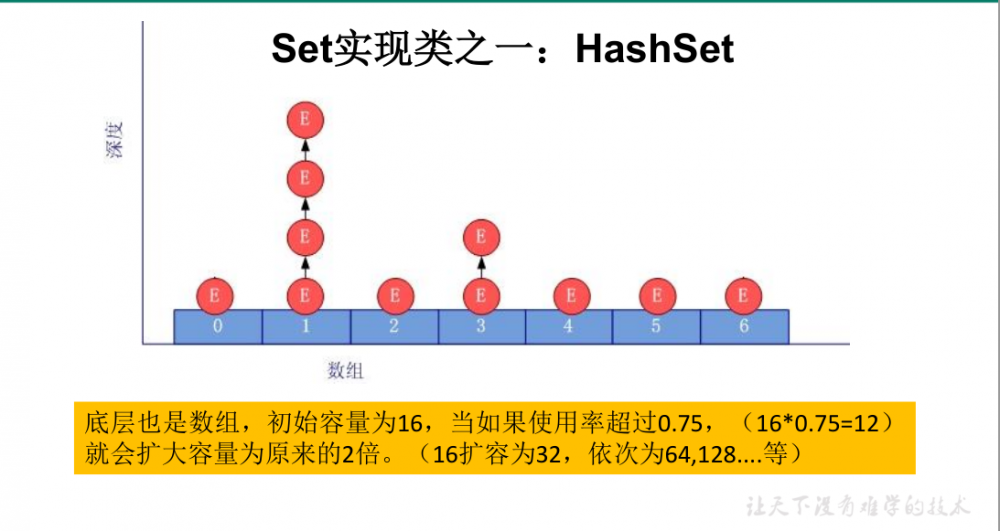
7.2、Set实现类之一:HashSet
- HashSet底层:数组+链表的结构。
- HashSet 无序性 :不能保证元素的排列顺序,存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的 哈希值决定的 。
- HashSet 不可重复性 :保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个。
- HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。
- HashSet 不是线程安全的
- HashSet 集合元素可以是 null
- HashSet 是 Set 接口的典型实现类
7.3、HashSet中添加元素的过程
-
当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的hashCode 值,然后根据 hashCode 值,通过某种散列函数决定该对象在 HashSet 底层数组中的存储位置。
-
如果 两个元素的hashCode()值相等 ,会再继续调用equals方法,如果equals方法结果为true,添加失败;如果为false,那么会保存该元素,但是该数组的位置已经有元素了,那么会** 通过链表的方式继续链接 **。
通过链表的方式继续链接分为两种情况:
- jdk1.7:新增的元素放到数组中,指向原来的元素
- jdk1.8:原来的元素放在数组中,指向新增的元素
-
如果两个元素的 equals() 方法返回 true,但 它们的 hashCode() 返回值不相等 ,hashSet 将会把它们存储在底层数组的不同的位置,但依然可以添加成功。
-
HashSet底层存储数据结构图
-
存储数据案例** 代码如下: **
public class SetTest { @Test public void test1() { Set set = new HashSet(); set.add(456); set.add(123); set.add(123); set.add("AA"); set.add("CC"); set.add(new User("Tom", 12)); set.add(new User("Tom", 12)); set.add(129); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); /** * 结果如下:由于User类中没有重写equals()方法和hashCode()方法,所以他们存储的时候调用了 * Object的hashCode()方法,所产生的hash值是不相同的。导致这认为这两个数据User{name='Tom', age=12}、 * User{name='Tom', age=12}不相同。 * 而123只打印了一个,为什么呢?因为HashSet底层存储数据时都需调用equals()进行比较 * AA * CC * 129 * 456 * User{name='Tom', age=12} * User{name='Tom', age=12} * 123 */ } } } 复制代码
7.4、重写hashCode()方法的基本准则
-
在程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值
-
当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode()方法的返回值也应相等
-
对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
-
注意:在自定义类中可以调用工具自动重写equals和hashCode,问题:为什么用Eclipse/IDEA复写hashCode方法, 有31这个数字?
public static int hashCode(Object a[]) { if (a == null) return 0; int result = 1; for (Object element : a) result = 31 * result + (element == null ? 0 : element.hashCode()); return result; } 复制代码- 选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 并且31只占用5bits,相乘造成数据溢出的概率较小。
- 31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率)
- 31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
7.5、重写 equals() 方法的基本原则
以自己定义的类为例,何时需要重写equals()方法?
-
必须遵守** 相等的对象必须具有相等的散列码 **
-
结论:复写equals方法的时候一般都需要同时复写hashCode方法。通常参与计算hashCode 的对象的属性也应该参与到equals()中进行计算
7.6、Set实现类之二:LinkedHashSet
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 根据元素的 hashCode 值来决定元素在底层数组的存储位置,但它** 同时使用双向链表维护元素的次序 **, 这使得元素看起来是以插入顺序保存的
- 对于频繁的遍历操作,LinkedHashSet效率高于HashSet,但是插入性能HashSet略高于LinkedHashSet
- LinkedHashSet 不允许集合元素重复。
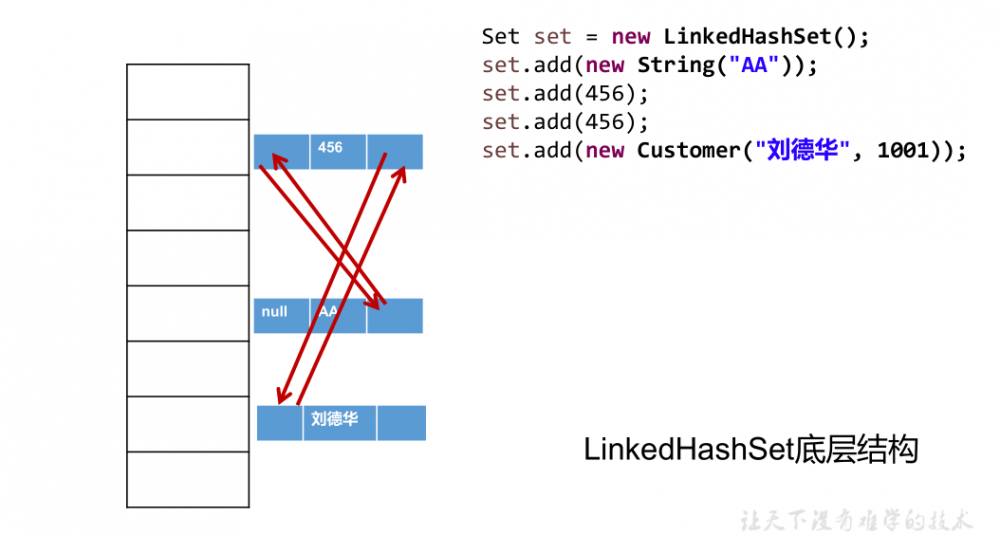
-
存储数据** 代码如下: **
public class SetTest { @Test public void test2() { Set set = new LinkedHashSet(); set.add(456); set.add(123); set.add(123); set.add("AA"); set.add("CC"); set.add(new User("Tom", 12)); set.add(new User("Tom", 12)); set.add(129); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); /** * 打印结果如下:看起来是以插入的顺序保存的,是因为它底层同时使用双向链表维护元素的次序 * 456 * 123 * AA * CC * User{name='Tom', age=12} * User{name='Tom', age=12} * 129 */ } } } 复制代码
7.7、Set实现类之三:TreeSet
- 向TreeSet中添加的数据,要求是相同类的对象。
- TreeSet 是 SortedSet 接口的实现类,TreeSet 可以确保集合元素处于排序状态。
- TreeSet底层使用 红黑树结构存储数据
- TreeSet 两种排序方法: 自然排序和 定制排序。默认情况下,TreeSet 采用自然排序。
- TreeSet有序,查询速度比List快
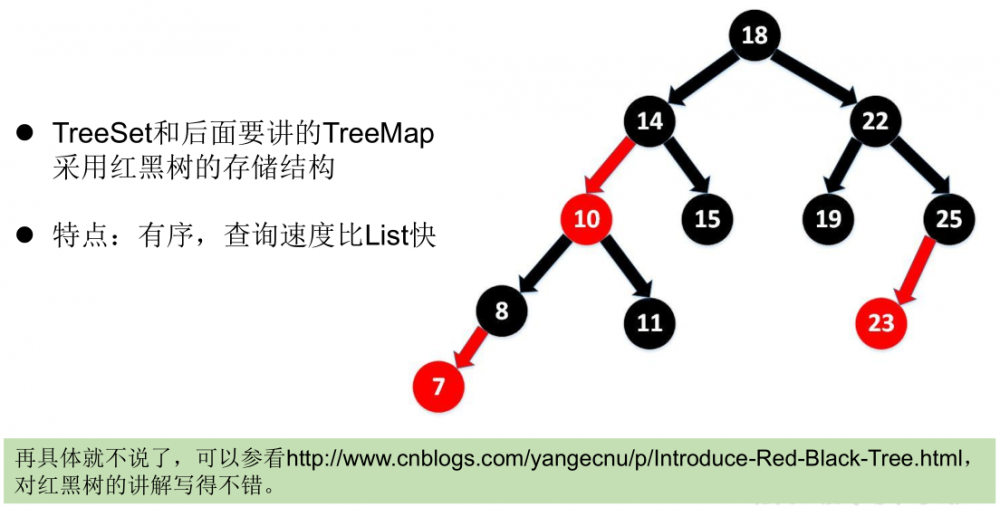
7.8、新增方法
Comparator comparator() Object first() Object last() Object lower(Object e) Object higher(Object e) SortedSet subSet(fromElement, toElement) SortedSet headSet(toElement) SortedSet tailSet(fromElement)
TreeSet中元素排序注意的点:
自然排序:
- 如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable接口
- 实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过compareTo(Object obj) 方法的返回值来比较大小。
- 只有相同类的两个实例才会比较大小 ,所以向 TreeSet 中添加的应该是同一个类的对象。
代码如下:
public class User implements Comparable {
private String name;
private int age;
@Override
public int compareTo(Object o) {
if (o instanceof User) {
User user = (User) o;
int compare = -this.name.compareTo(user.name);
if (compare != 0) {
return compare;
} else {
return Integer.compare(this.getAge(), user.getAge());
}
} else {
throw new RuntimeException("输入的类型不匹配");
}
}
}
public class TreeSet {
@Test
public void test1() {
java.util.TreeSet set = new java.util.TreeSet<>();
set.add(new User("Tom", 12));
set.add(new User("Jerry", 32));
set.add(new User("Jim", 2));
set.add(new User("Mike", 65));
set.add(new User("Jack", 33));
set.add(new User("Jack", 56));
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
/**
* 打印结果如下:如果名字相同,就按年龄排序
* User{name='Tom', age=12}
* User{name='Mike', age=65}
* User{name='Jim', age=2}
* User{name='Jerry', age=32}
* User{name='Jack', age=33}
* User{name='Jack', age=56}
*/
}
}
}
复制代码
定制排序:
- 只能向TreeSet中添加类型相同的对象。否则发生ClassCastException异常 。
- 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器
- 当元素的类型实现java.lang.Comparable 接口,而你又使用了定制排序,那就按照定制排序设定的来排序 记住要将实现Comparator接口的实例作为形参传递给TreeSet的构造器
代码如下:
public class User implements Comparable {
private String name;
private int age;
@Override
public int compareTo(Object o) {
if (o instanceof User) {
User user = (User) o;
int compare = -this.name.compareTo(user.name);
if (compare != 0) {
return compare;
} else {
return Integer.compare(this.getAge(), user.getAge());
}
} else {
throw new RuntimeException("输入的类型不匹配");
}
}
}
public class TreeSet {
@Test
public void test2() {
Comparator com = new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof User && o2 instanceof User) {
User u1 = (User) o1;
User u2 = (User) o2;
int compare = Integer.compare(u1.getAge(), u2.getAge());
if (compare != 0) {
return compare;
} else {
return -u1.getName().compareTo(u2.getName());
}
} else {
throw new RuntimeException("输入的数据类型不匹配");
}
}
};
java.util.TreeSet set = new java.util.TreeSet<>(com);
set.add(new User("Tom", 12));
set.add(new User("Jerry", 32));
set.add(new User("Jim", 2));
set.add(new User("Mike", 65));
set.add(new User("Mary", 33));
set.add(new User("Jack", 33));
set.add(new User("Jack", 56));
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
/**
* 打印结果:先按年龄从小到大排序,如果年龄相同,就按名字从大到小排序
User{name='Jim', age=2}
User{name='Tom', age=12}
User{name='Jerry', age=32}
User{name='Mary', age=33}
User{name='Jack', age=33}
User{name='Jack', age=56}
User{name='Mike', age=65}
*/
}
}
}
复制代码
7.9、关于以上set集合知识点的运用(面试题)
- 关于Set接口中的HashSet存储数据的一道面试题;代码如下:
public class Person {
int id;
String name;
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '/'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return getId() == person.getId() &&
Objects.equals(getName(), person.getName());
}
@Override
public int hashCode() {
return Objects.hash(getId(), getName());
}
}
public class CollectionTest {
@Test
public void test3(){
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
// 1、 打印结果如下:[Person{id=1002, name='BB'}, Person{id=1001, name='AA'}]
System.out.println(set);
p1.name = "CC";
set.remove(p1);
// 2、 打印结果如下:[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}]
// 为啥是这样的结果呢?
// 答:这就关系到HashSet底层存储数据的特点,首先存储new Person(1001,"AA")数据时根据Hash值来判断存储在数组中的哪个位置,当把其中的值改变后又 需要根据计算Hash值来判断存储位置与之前的newPerson(1001,"AA")数据的位置不同,但其值是空的,然后再去删除的时候是空的,未删除掉。
System.out.println(set);
set.add(new Person(1001,"CC"));
// 3、 打印结果如下:[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}]
// 此时添加的位置就是上面删除时为空的那个位置
System.out.println(set);
set.add(new Person(1001,"AA"));
// 4、 打印结果如下:[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}, Person{id=1001, name='AA'}]
// 此时添加的元素new Person(1001,"AA")位置的hash值跟这个元素中new Person(1001,"AA")的值改变后的位置是一样的,然后再根据equals()方法来判 断,发现值不相同则就存储
System.out.println(set);
}
}
复制代码
- 关于List中去除重复数据的一道练习题,代码如下:
public class CollectionTest {
//第一种方式去重
@Test
public void test2(){
List list = new ArrayList();
list.add(new Integer(1));
list.add(new Integer(2));
list.add(new Integer(2));
list.add(new Integer(4));
list.add(new Integer(4));
List list1 = duplicateList(list);
for(Object obj : list1){
System.out.println(obj);
}
}
public List duplicateList (List list){
HashSet set = new HashSet(list);
return new ArrayList(set);
}
//第二种方式去重
@Test
public void test2(){
List list = new ArrayList();
list.add(new Integer(1));
list.add(new Integer(2));
list.add(new Integer(2));
list.add(new Integer(4));
list.add(new Integer(4));
List list1 = duplicateList(list);
for(Object obj : list1){
System.out.println(obj);
}
}
public List duplicateList (List list){
HashSet set = new HashSet();
set.addAll(list);
return new ArrayList(set);
}
//第三种方式去重
@Test
public void test2(){
List list = new ArrayList();
list.add(new Integer(1));
list.add(new Integer(2));
list.add(new Integer(2));
list.add(new Integer(4));
list.add(new Integer(4));
List list1 = duplicateList(list);
for(Object obj : list1){
System.out.println(obj);
}
}
public List duplicateList (List list){
HashSet set = new HashSet(list);
list.clear();
list.addAll(set);
return list;
}
}
复制代码
8.0、比较器(排序)
1. Java中的对象,正常情况下,只能进行比较:== 或 != 。 不能使用 > 或 < ,但需要对多个对象进行排序就要使用 Comparable 和 Comparator 两个接口
2.像String、包装类等实现了Comparable接口,重写了compareTo(obj)方法,默认是自然排序,从小到大排
** 3. **对于自定义类来说,如果需要排序,我们可以让自定义类实现Comparable接口,重写compareTo(obj)方法。在compareTo(obj)方法中指明如何排序
Java实现对象排序的方式有两种:
- 自然排序:java.lang.Comparable ------>重写 compareTo(Object obj) 方法
- 定制排序:java.util.Comparator -------->重写**compare(Object o1,Object o2)**方法
Comparable接口与Comparator接口的使用的对比
- Comparable接口的方式一旦定制下来,保证Comparable接口实现类的对象在任何位置都可以比较大小。
- Comparator接口属于临时性的比较
8.1、自然排序:java.lang.Comparable
-
Comparable接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序
-
实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。如果*** 当前对象this大于形参对象obj,则返回正整数 ,如果 当前对象this小于形参对象obj,则返回负整数 ,如果 当前对象this等于形参对象obj,则返回零 *。
-
对于类 C 的每一个 e1 和 e2 来说,当且仅当
e1.compareTo(e2) == 0与e1.equals(e2)具有相同的 boolean 值时,类 C 的自然排序才叫做与 equals一致。 ***最好使自然排序与 equals 一致。*** -
实现Comparable接口的对象列表(和数组)可以通过 Collections.sort 或Arrays.sort进行自动排序。实现此接口的对象可以用作有序映射中的键或有序集合中的元素, 无需指定比较器
-
Comparable 的典型 实现:(默认都是从小到大排列的)
- String:按照字符串中字符的Unicode值进行比较
- Character:按照字符的Unicode值来进行比较
- 数值类型对应的包装类以及BigInteger、BigDecimal:按照它们对应的数值大小进行比较
- Boolean:true 对应的包装类实例大于 false 对应的包装类实例
- Date、Time等:后面的日期时间比前面的日期时间大
代码案例如下:
public class Goods implements Comparable {
private String name;
private double price;
//重写compareTo方法
@Override
public int compareTo(Object o) {
if (o instanceof Goods) {
Goods goods = (Goods) o;
////按照价格从高到低排序
if (this.price > goods.price) {
return 1;
//按照价格从低到高排序
} else if (this.price < goods.price) {
return -1;
} else {
//按照产品名称从高到低排序
return -this.name.compareTo(goods.name);
}
}
throw new RuntimeException("传入的数据类型不一致!");
}
}
public class CompareTest {
@Test
public void test2(){
Goods[]arr = new Goods[5];
arr[0] = new Goods("lenovoMouse",34);
arr[1] = new Goods("dellMouse",43);
arr[2] = new Goods("xiaomiMouse",12);
arr[3] = new Goods("huaweiMouse",65);
arr[4] = new Goods("microsoftMouse",43);
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
//打印结果如下,价格相同按名称排序
//[Goods{name='xiaomiMouse', price=12.0}, Goods{name='lenovoMouse', price=34.0}, Goods{name='microsoftMouse', price=43.0}, Goods{name='dellMouse', price=43.0}, Goods{name='huaweiMouse', price=65.0}]
}
}
复制代码
8.2、定制排序:java.util.Comparator
- 当元素的类型没有实现java.lang.Comparable 接口而又不方便修改代码,了 或者实现java.lang.Comparable 接口的排序规则不适合当前的操作,那用 么可以考虑使用 Comparator 的对象来 排序,强行对多个对象进行整体排序的比较。
- 重写**compare(Object o1,Object o2)**方法,比较o1和o2的大小: 如果方法返示 回正整数,则表示o1 大于o2 如果返回0 ,表示相等;返回负整数,表示o1 小于o2。
- 可以将 Comparator 传递给 sort 方法可以使用匿名内部类进行操作(如 Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。
- 当元素的类型实现java.lang.Comparable 接口,而你又使用了定制排序,那就按照定制排序设定的来排序
代码案例如下:
public class Goods implements Comparable {
private String name;
private double price;
//重写compareTo方法
@Override
public int compareTo(Object o) {
if (o instanceof Goods) {
Goods goods = (Goods) o;
////按照价格从高到低排序
if (this.price > goods.price) {
return 1;
//按照价格从低到高排序
} else if (this.price < goods.price) {
return -1;
} else {
//按照产品名称从高到低排序
return -this.name.compareTo(goods.name);
}
}
throw new RuntimeException("传入的数据类型不一致!");
}
}
public class CompareTest {
@Test
public void test4() {
Goods[] arr = new Goods[6];
arr[0] = new Goods("lenovoMouse", 34);
arr[1] = new Goods("dellMouse", 43);
arr[2] = new Goods("xiaomiMouse", 12);
arr[3] = new Goods("huaweiMouse", 65);
arr[4] = new Goods("huaweiMouse", 224);
arr[5] = new Goods("microsoftMouse", 43);
Arrays.sort(arr, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Goods && o2 instanceof Goods) {
Goods g1 = (Goods) o1;
Goods g2 = (Goods) o2;
if (g1.getName().equals(g2.getName())) {
//如果名字相同,就比较价格从大到小排序
return -Double.compare(g1.getPrice(), g2.getPrice());
} else {
//否则就比较名字
return g1.getName().compareTo(g2.getName());
}
}
throw new RuntimeException("输入的数据类型不一致");
}
});
System.out.println(Arrays.toString(arr));
//打印结果:
//[Goods{name='dellMouse', price=43.0}, Goods{name='huaweiMouse', price=224.0}, Goods{name='huaweiMouse', price=65.0}, Goods{name='lenovoMouse', price=34.0}, Goods{name='microsoftMouse', price=43.0}, Goods{name='xiaomiMouse', price=12.0}]
}
@Test
public void test3() {
String[] arr = new String[]{"aa", "bb", "cc", "dd", "ee", "ff", "gg"};
Arrays.sort(arr, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
if (o1 instanceof String && o2 instanceof String) {
String s1 = (String) o1;
String s2 = (String) o2;
//从大到小进行排序
return -s1.compareTo(s2);
}
throw new RuntimeException("输入的数据类型不一致");
}
});
System.out.println(Arrays.toString(arr));
//打印结果如下:[gg, ff, ee, dd, cc, bb, aa]
}
}
复制代码
八、Map接口
8.1、Map接口
- Map 中的 key 和 value 都可以是任何引用类型的数据
- Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中,HashMap是 Map 接口使用频率最高的实现类
- key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到唯一的、确定的 value
- Map 中的 key 用Set来存放, 不允许重复,即同一个 Map 对象所对应的类, 须重写hashCode()和equals()方法
8.2、Map存储数据结构图
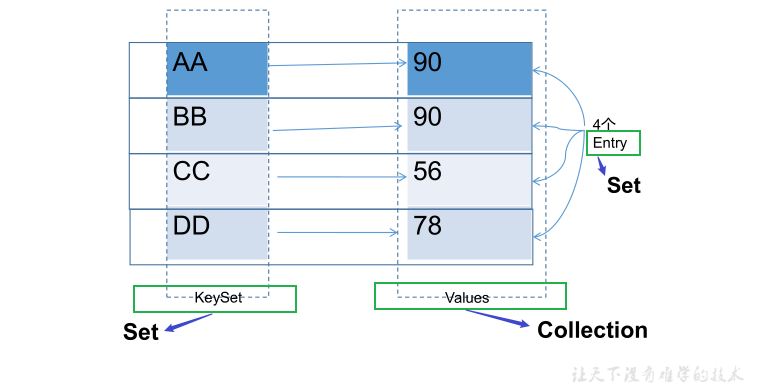
8.3、Map中常用的接口方法
添加、删除、修改操作:
-
Object put(Object key,Object value):将指定key-value 添加 到(或 修改 )当前map对象中 -
void putAll(Map m):将m中的所有key-value对存放到当前map中 -
Object remove(Object key):移除指定key的key-value对,并返回当前删除的value -
void clear():清空当前map中的所有数据,当前size为零
元素查询的操作:
Object get(Object key) boolean containsKey(Object key) boolean containsValue(Object value) int size() boolean isEmpty() boolean equals(Object obj)
元视图操作的方法(相当于遍历Map集合):
- Set keySet():返回所有key构成的Set集合
- Collection values():返回所有value构成的Collection集合
- Set entrySet():返回所有key-value对构成的Set集合
对于遍历的方法,如下代码所示:
public class MapTest {
@Test
public void test() {
Map map = new HashMap();
map.put("AA", 123);
map.put(45, 1234);
map.put("BB", 56);
//遍历所有的key集:KeySet()
Set set = map.keySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
/**
* 打印结果如下:
* AA
* BB
* 45
*/
}
//遍历Value集:values()
Collection values = map.values();
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
System.out.println(iterator1.next());
/**
* 打印结果如下:
* 123
* 56
* 1234
*/
}
//方式一、 遍历所有的Key-value
Set entrySet = map.entrySet();
Iterator iterator2 = entrySet.iterator();
while (iterator2.hasNext()) {
Object obj = iterator2.next();
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue());
/**
* 打印结果如下:
* AA---->123
* BB---->56
* 45---->1234
*/
}
//方式二、 遍历所有的Key-value
Set set1 = map.keySet();
Iterator iterator3 = set1.iterator();
while (iterator3.hasNext()) {
Object key = iterator3.next();
Object value = map.get(key);
System.out.println(key + "---->" + value);
/**
* 打印结果如下:
* AA---->123
* BB---->56
* 45---->1234
*/
}
}
}
复制代码
九、Map实现类之一:HashMap
9.1、HashMap实现类
-
HashMap是 Map 接口 使用频率最高的实现类
-
HashMap底层:
JDK7之前:数组+链表 JDK8之后:数组+链表+红黑树
-
Map中的key:无序的、不可重复的,使用Set存储所有的key -------> key所在的类要重写equals()和hashCode()
-
Map中的value:无序的、可重复的,使用Collection存储所有的value -----> value所在的类要重写equals()
-
Map中的一个键值对:key-value 构成了一个Entry对象。
-
Map中的键值对构成的Entry对象:无序的、不可重复的,使用Set存储所有的entry对象
-
HashMap:线程不安全的,效率高;可以存储null的key和null的value
-
HashMap 判断两个 key 相等的标准是:两个 key 通过 equals() 方法返回 true,hashCode 值也相等。
-
HashMap 判断两个 value 相等的标准是:两个 value 通过 equals() 方法返回 true
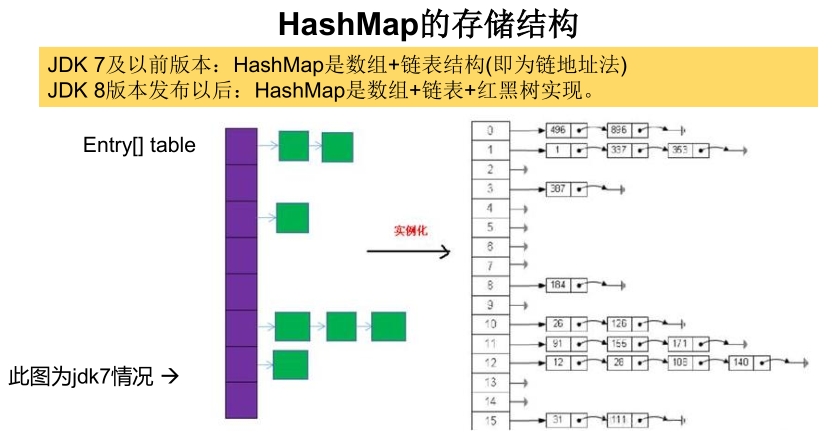
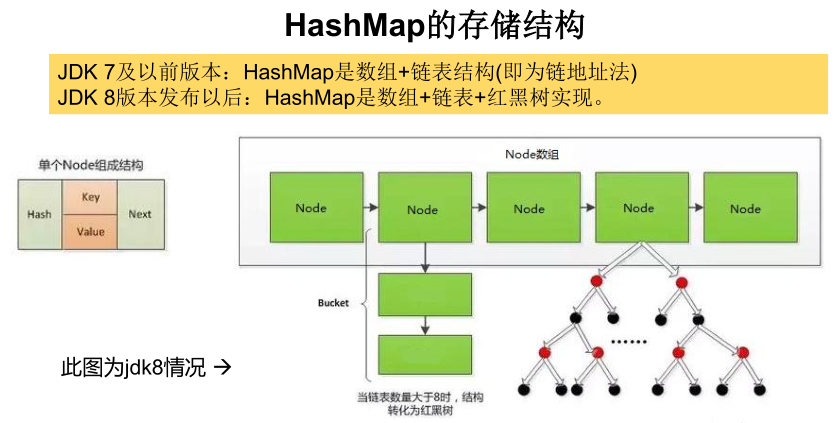
9.2、HashMap的存储结构
JDK7之前:
JDK8之后:
9.3、HashMap源码中的重要常量
DEFAULT_INITIAL_CAPACITY MAXIMUM_CAPACITY DEFAULT_LOAD_FACTOR TREEIFY_THRESHOLD UNTREEIFY_THRESHOLD MIN_TREEIFY_CAPACITY table entrySet size modCount threshold loadFactor
9.4、HashMap在JDK1.7之前存储数据的过程
-
HashMap的内部存储结构其实是 数组和链表的结合,当实例化一个HashMap时,系统会创建一个长度为16的Entry数组,在这个数组中可以存放元素的位置我们称之为“桶”(bucket)
-
每个bucket中存储一个元素,即一个Entry对象,但每一个Entry对象可以带一个引用变量,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Entry链。而且新添加的元素作为链表的头节点(head)。
-
添加元素过程:
向HashMap中添加entry1(key,value),1、需要首先计算entry1中key的哈希值(根据key所在类hashCode()计算得到),此哈希值经过处理以后,得到在底层Entry[]数组中要存储的位置i。2、如果位置i上没有元素,则entry1直接添加成功。3、如果位置i上已经存在entry2(或还有链表存在的entry3,entry4),则需要通过循环的方法,依次比较entry1中key和其他的entry。4、如果彼此hash值不同,则直接添加成功。5、如果hash值相同,继续调用equals()方法比较,如果返回值为true,则使用entry1的value去替换equals为true的entry的value。如果遍历一遍以后,发现所有的equals返回都为false,则entry1仍可添加成功。entry1指向原有entry元素。
-
HashMap扩容:
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,而在HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
-
那么HashMap 什么时候进行扩容呢 ?
当HashMap中的元素个数超过数组的
size*DEFAULT_LOAD_FACTOR时且在数组中要存放的位置非空)时就会进行数组扩容。DEFAULT_LOAD_FACTOR=0.75这是一个折中的取值。数组中大小默认值为16,当HashMap中元素个数超过16*0.75=12(临界值)就会将数组的大小扩大为2乘以16=32并将原有的数据复制过来,这是非常消耗性能的, 如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
9.5、HashMap在JDK1.8之后存储数据的过程
-
HashMap的内部存储结构其实是 数组+ 链表+ 树 的结合 。当实例化一个HashMap时,会初始initialCapacity和loadFactor,在put第一对映射关系时,系统会创建一个长度为16的Node数组,在这个数组中可以存放元素的位置我们称之为“桶”(bucket)
-
每个bucket中存储一个元素,即一个Node对象,但每一个Node对象可以带一个引用变量next,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Node链。也可能是一个一个TreeNode对象,每一个TreeNode对象可以有两个叶子结点left和right,因此,在一个桶中,就有可能生成一个TreeNode树。而新添加的元素作为链表的last,或树的叶子结点。
-
那么HashMap 什么时候进行扩容和树形化呢 ?
当HashMap中的元素个数超过数组的
size*DEFAULT_LOAD_FACTOR时且在数组中要存放的位置非空)时就会进行数组扩容。DEFAULT_LOAD_FACTOR=0.75这是一个折中的取值。数组中大小默认值为16,当HashMap中元素个数超过16*0.75=12(临界值threshold)就会将数组的大小扩大为2乘以16=32并将原有的数据复制过来,这是非常消耗性能的, 如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提HashMap的性能。当HashMap中的其中一个链的对象个数如果达到了8个,此时如果capacity没有达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链会变成树,结点类型由Node变成TreeNode类型。当然,如果当映射关系被移除后,下次resize方法时判断树的结点个数低于6个,也会把树再转为链表
9.6、关于映射关系的key 是否可以修改(会修改hashcode的值) ?
- 答:最好不要,映射关系存储到HashMap中会存储key的hash值,这样就不用在每次查找时重新计算每一个Entry或Node(TreeNode)的hash值了,因此如果已经put到Map中的映射关系,再修改key的属性,而这个属性又参与hashcode值的计算,那么会导致匹配不上
9.7、JDK8相对于JDK7的变化:
- HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组,会加载加载因子
- 当首次调用map.put()时,再创建长度为16的数组
- JDK8中数组为Node类型,在jdk7中称为Entry类型
- 形成链表结构时,新添加的key-value对在链表的尾部( 七上八下 )
- 当数组指定索引位置的链表长度>8时,且map中的数组的长度> 64时,此索引位置上的所有key-value对使用红黑树进行存储
9.8、对于HashMap的面试题(负载对 因子值的大小,对HashMap 有什么影响?)
- 负载因子的大小决定了HashMap的数据密度
- 负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成查询或插入时的比较次数增多,性能会下降
- 负载因子越小,就越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也就越短,查询和插入时比较的次数也越小,性能会更高。但是会浪费一定的内容空间。而且经常扩容也会影响性能,建 议初始化预设大一点的空间。
- 会考虑将负载因子设置为0.7~0.75,此时平均检索长度接近于常数
十、Map实现类之二:LinkedHashMap
-
在遍历map元素时,可以按照添加的顺序实现遍历。
-
LinkedHashMap 是 HashMap 的子类
-
在HashMap存储结构的基础上,使用了一对双向链表来记录添加元素的顺序
-
与LinkedHashSet类似,LinkedHashMap 可以维护 Map 的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致
-
为什么会按照添加的顺序实现遍历,请看源码如下:
//LinkedHashMap内部类: Entry static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } //HashMap内部类:Node static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } } 复制代码实现了双向链表记录添加元素的顺序,才会按照添加的顺序实现遍历
十一、Map实现类之三:TreeMap
-
TreeMap存储 Key-Value 对时,需要根据 key-value 对进行排序。TreeMap 可以保证所有的 Key-Value 对处于 有序状态。
-
向TreeMap中添加key-value, 要求key必须是由同一个类创建的对象
-
TreeMap底层使用 红黑树结构存储数据
-
TreeMap 的 Key 的排序:
- 自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClasssCastException
- 定制排序:创建 TreeMap 时,传入一个 Comparator 对象,该对象负责对TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现Comparable 接口
-
treeMap判断 两个key 相等的标准:两个key通过compareTo()方法或者compare()方法返回0。
案例如下:自然排序
public class User implements Comparable{
private String name;
private int age;
//按照姓名从大到小排列,年龄从小到大排列
@Override
public int compareTo(Object o) {
if(o instanceof User){
User user = (User)o;
//return -this.name.compareTo(user.name);
int compare = -this.name.compareTo(user.name);
if(compare != 0){
return compare;
}else{
return Integer.compare(this.age,user.age);
}
}else{
throw new RuntimeException("输入的类型不匹配");
}
}
}
public class TreeMapTest {
@Test
public void test1(){
TreeMap map = new TreeMap();
User u1 = new User("Tom",23);
User u2 = new User("Jerry",32);
User u3 = new User("Jack",20);
User u4 = new User("Rose",18);
map.put(u1,98);
map.put(u2,89);
map.put(u3,76);
map.put(u4,100);
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()){
Object obj = iterator1.next();
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue());
}
}
}
复制代码
定制排序:
public class TreeMapTest {
@Test
public void test2(){
TreeMap map = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
return Integer.compare(u1.getAge(),u2.getAge());
}
throw new RuntimeException("输入的类型不匹配!");
}
});
User u1 = new User("Tom",23);
User u2 = new User("Jerry",32);
User u3 = new User("Jack",20);
User u4 = new User("Rose",18);
map.put(u1,98);
map.put(u2,89);
map.put(u3,76);
map.put(u4,100);
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()){
Object obj = iterator1.next();
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue());
}
}
}
复制代码
十二、Map实现类之四:Hashtable
- Hashtable是个古老的 Map 实现类,JDK1.0就提供了
- Hashtable是线程安全的
- 与HashMap不同,Hashtable 不允许使用 null 作为 key 和 null 作为value
- Hashtable判断两个key相等、两个value相等的标准,与HashMap一致。
- Hashtable实现原理和HashMap相同,底层都使用数组+红黑树+链表结构
代码案例如下:
public class MapTest {
@Test
public void test(){
//HashTable
Map map1 = new Hashtable();
map1.put(null, null);
System.out.println(map1);
/**
* 会报错:不能添加为null的元素
* java.lang.NullPointerException
*/
//HashMap
Map map = new HashMap();
map.put(null, null);
System.out.println(map);
/**
* 打印结果如下:
* {null=null}
*/
}
}
复制代码
十三、Map实现类之五:Properties
- Properties 类是 Hashtable 的子类,该对象用于处理属性文件
- 由于属性文件里的 key、value 都是字符串类型,所以 Properties 里的 key和 value 都是字符串类型
- 存取数据时,建议使用
setProperty(String key,String value)方法和getProperty(String key)方法
案例如下:
public class PropertiesTest {
//Properties:常用来处理配置文件且key和value都是String类型
public static void main(String[] args) {
FileInputStream fis = null;
try {
Properties pros = new Properties();
fis = new FileInputStream("jdbc.properties");
pros.load(fis);//加载流对应的文件
String name = pros.getProperty("name");
String password = pros.getProperty("password");
System.out.println("name = " + name + ", password = " + password);
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
复制代码
十五、Collections工具类(操作集合)Arrays工具类(操作数组)
1、Collections工具类
- Collections 是一个操作 Set、List 和 Map 等集合的工具类
- Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法
2、Collections常用方法
排序操作:
reverse(List) shuffle(List) sort(List) sort(List,Comparator) swap(List,int, int)
查找、替换:
-
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素 -
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素 -
Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素 -
Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素 -
int frequency(Collection,Object):返回指定集合中指定元素的出现次数 -
void copy(List dest,List src):将src中的内容复制到dest中 -
boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List 对象的所有旧值 -
注意
void copy(List dest,List src)方法的使用,给个案例如下:public class Collections { @Test public void test(){ List list = new ArrayList(); list.add(123); list.add(43); list.add(765); list.add(-97); list.add(0); //错误写法;报异常java.lang.IndexOutOfBoundsException: Source does not fit in dest List dest = new ArrayList(); java.util.Collections.copy(dest,list); System.out.println(dest); System.out.println(dest.size()); } } 复制代码 -
为啥会报异常错误,我们可以看下
void copy(List dest,List src)源码:public static <T> void copy(List<? super T> dest, List<? extends T> src) { int srcSize = src.size(); if (srcSize > dest.size())//注意这里,dest.size() throw new IndexOutOfBoundsException("Source does not fit in dest"); if (srcSize < COPY_THRESHOLD || (src instanceof RandomAccess && dest instanceof RandomAccess)) { for (int i=0; i<srcSize; i++) dest.set(i, src.get(i)); } else { ListIterator<? super T> di=dest.listIterator(); ListIterator<? extends T> si=src.listIterator(); for (int i=0; i<srcSize; i++) { di.next(); di.set(si.next()); } } } 复制代码 -
解决方法:
public class Collections { @Test public void test(){ List list = new ArrayList(); list.add(123); list.add(43); list.add(765); list.add(-97); list.add(0); //解决方法 List<Object> dest = Arrays.asList(new Object[list.size()]); java.util.Collections.copy(dest,list); //[123, 43, 765, -97, 0] System.out.println(dest); //5 System.out.println(dest.size()); } } 复制代码
同步控制:
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题

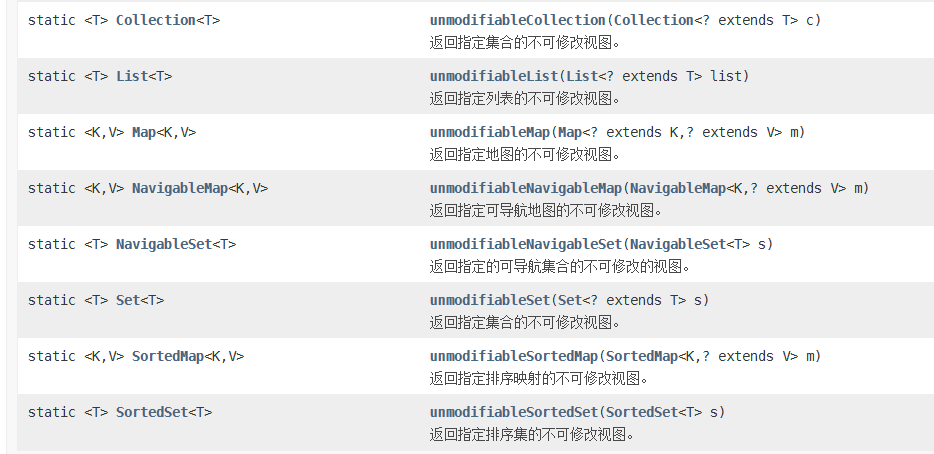
创建只读集合,不可更改:
- Collections类中提供了多个unmodifiableXxx()方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常
3、Collection和Collections的区别
- Collection:存储单列数据的一个接口,里面有继承它的Set接口和List接口
- Collections:是一个操作 Set、List 和 Map 等集合的工具类
如果,此文章对你有所帮助,请帮忙点个赞呗! 谢谢!!!

正文到此结束
- 本文标签: rand tar final 文章 数据 HashMap 基本原则 并发 eclipse key DDL cat Collection FIT ArrayList 定制 CTO tk 开发 ACE UI 集合类 时间 stream db Collections src 产品 IO API LinkedList update CEO tag js 解决方法 Word 配置 线程同步 需求 JDBC node 实例 同步 线程 Property NSA 索引 java 空间 HashSet https list 删除 map id 代码 synchronized tab DOM swap 总结 queue IDE HashTable 游标 设计模式 BigInteger ip value http 安全 Java集合 多线程 equals 源码 遍历
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

