

")





本文非常长,阅读需要勇气。
作者尝试在移动端总结出一套面向页面的架构设计,暂定命名为POA(page-oriented architecture),因为核心的关注点在于page,阅读本文更多的是了解移动端架构的方式方法。
另外,本文主要是方法论层面的阐述,具体案例因为每一种编程语言的不一样实现会有所不同,所以文中代码均为伪代码。作者已经部分实现这套方案,但具体的实现并不重要,重要的是希望这套方...
阅读全文
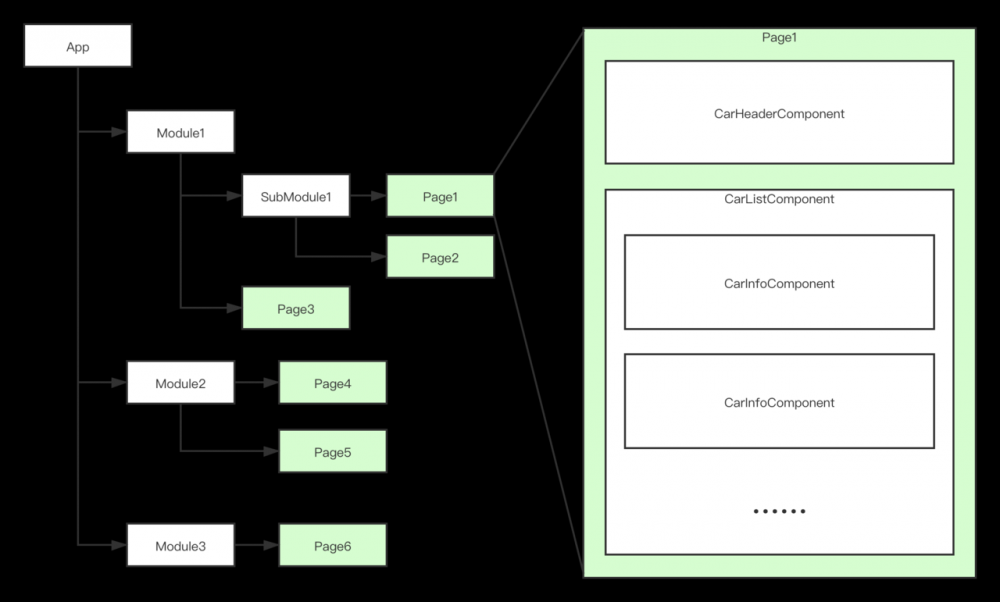 软件架构
软件架构
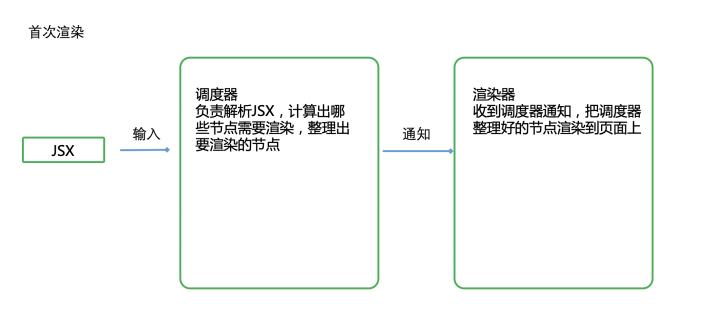
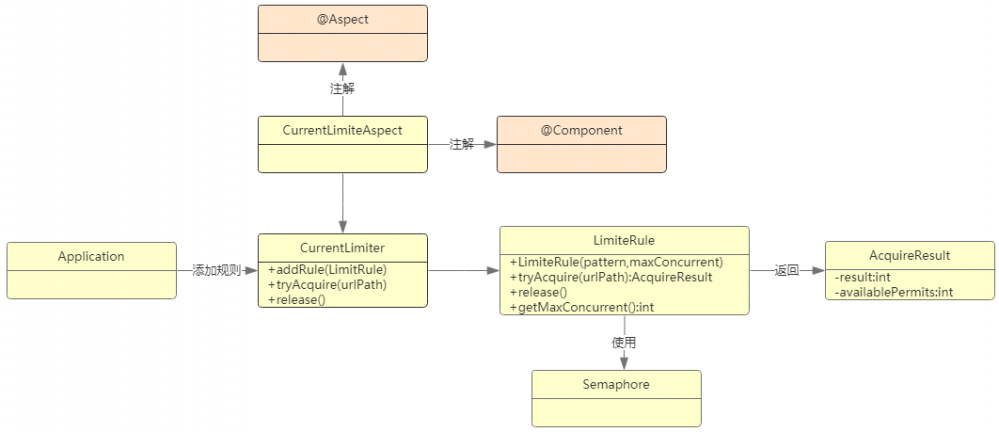
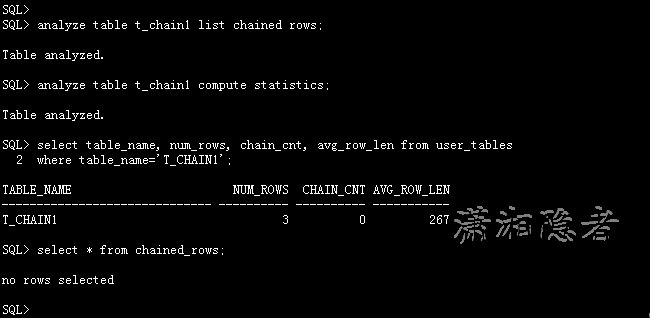







 搞个gitee的项目
搞个gitee的项目

![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

