物化视图刷新结合ADG的尝试
之前写过一篇 物化视图刷新结合ADG的尝试,想必绝大多数的朋友看完再没有深究,其实也有些朋友做了建议,让我尝试prebuilt来做。这种数据迁移方式用的比较少,但是个人感觉还是很不错的。如果迁移的表不是很多,这种迁移方式还是非常强大的。
如果一个表非常大,我目前的设想就是通过ADG备库来把数据首先同步到统计库中,然后在主库端通过物化视图日志来增量刷新。
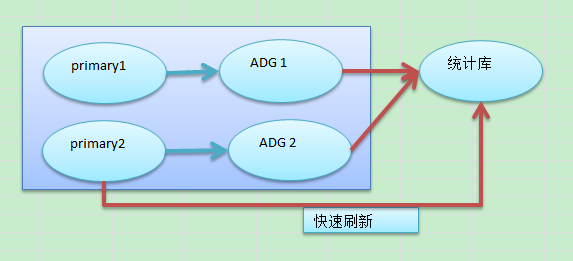
使用物化视图 prebuilt的方式确实可以实现,我产生了几个疑问,物化视图日志该什么时候创建。创建的时间太早或者太晚,对于增量刷新是否有影响,如果没有影响,我都幻想着可能是替代ogg的一个神器了。我做了下面三个测试。
###同步测试,物化视图刷新基于rowid
统计库创建两个db link,一个指向主库,一个指向ADG
主库新增一个表 create table ACCtest20.test_mv_pri as select * from dba_objects where rownum<1001;
SQL> select count(*)from ACCtest20.test_mv_pri;
COUNT(*)
----------
1000
ADG+统计库创建表基于ADG的db link
create table test.test_mv_pri as select *from ACCtest20.test_mv_pri@public_test0;
主库增加一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000001,'test','TABLE');
commit;
主库修改一条数据
SQL> select object_id from ACCtest20.test_mv_pri where rownum<2;
OBJECT_ID
----------
20
update ACCtest20.test_mv_pri set object_id=1000002 where object_id=20;
commit;
主库创建物化视图日志
create materialized view log on ACCtest20.test_mv_pri with rowid;
主库查询
SQL> select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
0
主库+统计库创建物化视图基于主库的db link
create materialized view test.test_mv_pri on prebuilt table refresh fast with rowid as select *from ACCtest20.test_mv_pri@public_test0;
create materialized view test.test_mv_pri on prebuilt table refresh fast with rowid as select *from ACCtest20.test_mv_pri@public_test0
*
ERROR at line 1:
ORA-12058: materialized view cannot use prebuilt table
做到这一步发现已经完全不支持了,所以就放弃了rowid的方式。
继续做第二个测试。
###同步测试 基于主键刷新 物化视图日志在全量同步后创建
统计库创建两个db link,一个指向主库,一个指向ADG
主库新增一个表
create table ACCtest20.test_mv_pri as select owner,object_id,object_name,object_type from all_objects where rownum<1001 and object_id is not null;
alter table ACCtest20.test_mv_pri modify(object_id primary key);
SQL> select count(*)from ACCtest20.test_mv_pri;
COUNT(*)
----------
1000
ADG+统计库创建表基于ADG的db link
create table test.test_mv_pri as select *from ACCtest20.test_mv_pri@public_test0;
主库增加一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000001,'test','TABLE');
commit;
主库修改一条数据
SQL> select object_id from ACCtest20.test_mv_pri where rownum<2;
OBJECT_ID
----------
2
update ACCtest20.test_mv_pri set object_id=1000002 where object_id=2;
commit;
主库创建物化视图日志
create materialized view log on ACCtest20.test_mv_pri ;
主库查询
SQL> select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
0
SQL> select count(*)from ACCtest20.test_mv_pri ;
COUNT(*)
----------
1001
主库+统计库创建物化视图基于主库的db link
create materialized view test.test_mv_pri on prebuilt table refresh fast as select *from ACCtest20.test_mv_pri@public_test0;
查看数据条数
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
增量刷新数据,查看数据条数是否完全同步
exec dbms_mview.refresh('test.test_mv_pri','F');
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
所以得到的结论是,在物化视图快速刷新的场景中,在本次测试中,在全量同步数据之后创建物化视图日志,快速刷新可能数据不一致,在全量同步的过程中,任何的dml操作可能都会丢失。
###同步测试 基于主键刷新 物化视图日志在全量同步前创建
统计库创建两个db link,一个指向主库,一个指向ADG
主库新增一个表
create table ACCtest20.test_mv_pri as select owner,object_id,object_name,object_type from all_objects where rownum<1001 and object_id is not null;
alter table ACCtest20.test_mv_pri modify(object_id primary key);
SQL> select count(*)from ACCtest20.test_mv_pri;
COUNT(*)
----------
1000
主库创建物化视图日志
create materialized view log on ACCtest20.test_mv_pri ;
ADG+统计库创建表基于ADG的db link
create table test.test_mv_pri as select *from ACCtest20.test_mv_pri@public_test0;
主库增加一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000001,'test','TABLE');
commit;
主库修改一条数据
SQL> select object_id from ACCtest20.test_mv_pri where rownum<2;
OBJECT_ID
----------
2
update ACCtest20.test_mv_pri set object_id=1000002 where object_id=2;
commit;
主库查询
SQL> select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
3
SQL> select count(*)from ACCtest20.test_mv_pri ;
COUNT(*)
----------
1001
主库+统计库创建物化视图基于主库的db link
create materialized view test.test_mv_pri on prebuilt table refresh fast as select *from ACCtest20.test_mv_pri@public_test0;
查看数据条数
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
增量刷新数据,查看数据条数是否完全同步
exec dbms_mview.refresh('test.test_mv_pri','F');
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
主库查询
select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
0
###数据不一致 #############
主库继续插入一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000003,'test','TABLE');
commit;
增量刷新数据,查看数据条数是否完全同步
SQL> select count(*)from ACCtest20.test_mv_pri ;
COUNT(*)
----------
1002
结论,在这种场景中,可能会有数据丢失的情况。主要原因就是统计库的物化视图创建时间晚于源库的物化视图日志时间。
我这种测试不是说物化视图prebuilt的方式不好,而是在这种场景中还是会有一些影响。如果通过主库全量同步数据,再增量刷新肯定是没有问题的。我这个场景只是想通过ADG来实现间接的全量刷新,不是主流的使用方法。
如果一个表非常大,我目前的设想就是通过ADG备库来把数据首先同步到统计库中,然后在主库端通过物化视图日志来增量刷新。
使用物化视图 prebuilt的方式确实可以实现,我产生了几个疑问,物化视图日志该什么时候创建。创建的时间太早或者太晚,对于增量刷新是否有影响,如果没有影响,我都幻想着可能是替代ogg的一个神器了。我做了下面三个测试。
###同步测试,物化视图刷新基于rowid
统计库创建两个db link,一个指向主库,一个指向ADG
主库新增一个表 create table ACCtest20.test_mv_pri as select * from dba_objects where rownum<1001;
SQL> select count(*)from ACCtest20.test_mv_pri;
COUNT(*)
----------
1000
ADG+统计库创建表基于ADG的db link
create table test.test_mv_pri as select *from ACCtest20.test_mv_pri@public_test0;
主库增加一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000001,'test','TABLE');
commit;
主库修改一条数据
SQL> select object_id from ACCtest20.test_mv_pri where rownum<2;
OBJECT_ID
----------
20
update ACCtest20.test_mv_pri set object_id=1000002 where object_id=20;
commit;
主库创建物化视图日志
create materialized view log on ACCtest20.test_mv_pri with rowid;
主库查询
SQL> select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
0
主库+统计库创建物化视图基于主库的db link
create materialized view test.test_mv_pri on prebuilt table refresh fast with rowid as select *from ACCtest20.test_mv_pri@public_test0;
create materialized view test.test_mv_pri on prebuilt table refresh fast with rowid as select *from ACCtest20.test_mv_pri@public_test0
*
ERROR at line 1:
ORA-12058: materialized view cannot use prebuilt table
做到这一步发现已经完全不支持了,所以就放弃了rowid的方式。
继续做第二个测试。
###同步测试 基于主键刷新 物化视图日志在全量同步后创建
统计库创建两个db link,一个指向主库,一个指向ADG
主库新增一个表
create table ACCtest20.test_mv_pri as select owner,object_id,object_name,object_type from all_objects where rownum<1001 and object_id is not null;
alter table ACCtest20.test_mv_pri modify(object_id primary key);
SQL> select count(*)from ACCtest20.test_mv_pri;
COUNT(*)
----------
1000
ADG+统计库创建表基于ADG的db link
create table test.test_mv_pri as select *from ACCtest20.test_mv_pri@public_test0;
主库增加一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000001,'test','TABLE');
commit;
主库修改一条数据
SQL> select object_id from ACCtest20.test_mv_pri where rownum<2;
OBJECT_ID
----------
2
update ACCtest20.test_mv_pri set object_id=1000002 where object_id=2;
commit;
主库创建物化视图日志
create materialized view log on ACCtest20.test_mv_pri ;
主库查询
SQL> select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
0
SQL> select count(*)from ACCtest20.test_mv_pri ;
COUNT(*)
----------
1001
主库+统计库创建物化视图基于主库的db link
create materialized view test.test_mv_pri on prebuilt table refresh fast as select *from ACCtest20.test_mv_pri@public_test0;
查看数据条数
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
增量刷新数据,查看数据条数是否完全同步
exec dbms_mview.refresh('test.test_mv_pri','F');
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
所以得到的结论是,在物化视图快速刷新的场景中,在本次测试中,在全量同步数据之后创建物化视图日志,快速刷新可能数据不一致,在全量同步的过程中,任何的dml操作可能都会丢失。
###同步测试 基于主键刷新 物化视图日志在全量同步前创建
统计库创建两个db link,一个指向主库,一个指向ADG
主库新增一个表
create table ACCtest20.test_mv_pri as select owner,object_id,object_name,object_type from all_objects where rownum<1001 and object_id is not null;
alter table ACCtest20.test_mv_pri modify(object_id primary key);
SQL> select count(*)from ACCtest20.test_mv_pri;
COUNT(*)
----------
1000
主库创建物化视图日志
create materialized view log on ACCtest20.test_mv_pri ;
ADG+统计库创建表基于ADG的db link
create table test.test_mv_pri as select *from ACCtest20.test_mv_pri@public_test0;
主库增加一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000001,'test','TABLE');
commit;
主库修改一条数据
SQL> select object_id from ACCtest20.test_mv_pri where rownum<2;
OBJECT_ID
----------
2
update ACCtest20.test_mv_pri set object_id=1000002 where object_id=2;
commit;
主库查询
SQL> select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
3
SQL> select count(*)from ACCtest20.test_mv_pri ;
COUNT(*)
----------
1001
主库+统计库创建物化视图基于主库的db link
create materialized view test.test_mv_pri on prebuilt table refresh fast as select *from ACCtest20.test_mv_pri@public_test0;
查看数据条数
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
增量刷新数据,查看数据条数是否完全同步
exec dbms_mview.refresh('test.test_mv_pri','F');
SQL> select count(*)from test.test_mv_pri;
COUNT(*)
----------
1000
主库查询
select count(*)from ACCtest20.MLOG$_TEST_MV_PRI;
COUNT(*)
----------
0
###数据不一致 #############
主库继续插入一条数据
insert into ACCtest20.test_mv_pri(owner,object_id,object_name,object_type) values('test',1000003,'test','TABLE');
commit;
增量刷新数据,查看数据条数是否完全同步
SQL> select count(*)from ACCtest20.test_mv_pri ;
COUNT(*)
----------
1002
结论,在这种场景中,可能会有数据丢失的情况。主要原因就是统计库的物化视图创建时间晚于源库的物化视图日志时间。
我这种测试不是说物化视图prebuilt的方式不好,而是在这种场景中还是会有一些影响。如果通过主库全量同步数据,再增量刷新肯定是没有问题的。我这个场景只是想通过ADG来实现间接的全量刷新,不是主流的使用方法。
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

