【问底】许鹏:Standalone部署模式下临时文件的生成和清除
【导读】笔者(许鹏)看Spark源码的时间不长,记笔记的初衷只是为了不至于日后遗忘。在源码阅读的过程中秉持着一种非常简单的思维模式,就是努力去寻找一条贯穿全局的主线索。
我在对Spark内部实现有了一定了解之后,当然希望将其应用到实际的工程实践中,这时候会面临许多新的挑战,比如选取哪个作为数据仓库,是HBase、MongoDB还是Cassandra。即便一旦选定之后,在实践过程还会遇到许多意想不到的问题。
笔者不才,就遇到的一些问题,整理出来与诸君共同分享。此前已分享了:使用Spark+Cassandra打造高性能数据分析平台(一)、( 二)。
概要
Spark运行过程中资源的申请和释放一直是源码分析时需要关注的重点,从资源种类上来说,有CPU、内存、网络、磁盘,其中前三者会在进程退出时由OS来负责释放。而占用的磁盘资源,如果Spark自身不及时的清理,就势必会造成文件的堆积,直至磁盘被占满不可用。
因此有必要弄清楚Spark运行过程中产生的临时文件及其释放的时机,这样有助于部署和运维过程中采取相应的文件清理策略。
部署时的第三方包依赖
再提出具体的疑问之前,先回顾一下standalone的部署模式。
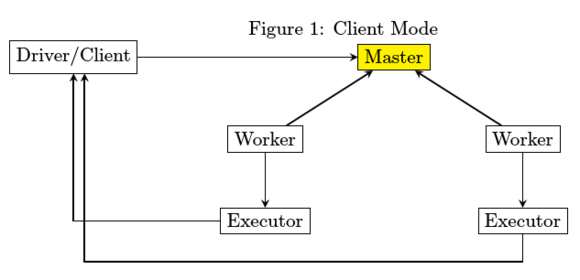
在standalone下又分为client模式和cluster模式,其中client模式下,driver和client运行于同一JVM中,不由worker启动,该JVM进程直到spark application计算完成返回结果后才退出。如下图所示。
而在cluster模式下,driver由worker启动,client在确认spark application成功提交给cluster后直接退出,并不等待spark application运行结果返回。如下图所示
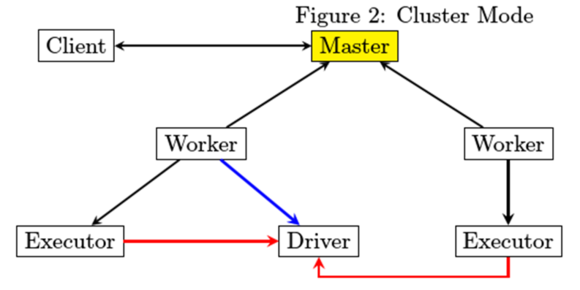
从部署图来进行分析,每个JVM进程在启动时的文件依赖如何得到满足。
1. Master进程最为简单,除了spark jar包之外,不存在第三方库依赖
2. Driver和Executor在运行的时候都有可能存在第三方包依赖,分开来讲
- Driver比较简单,spark-submit在提交的时候会指定所要依赖的jar文件从哪里读取
- Executor由worker来启动,worker需要下载Executor启动时所需要的jar文件,那么从哪里下载呢。
为了解决Executor启动时依赖的Jar问题,Driver在启动的时候要启动HttpFileServer存储第三方jar包,然后由worker从HttpFileServer来获取。为此HttpFileServer需要创建相应的目录,而Worker也需要创建相应的目录。
HttpFileServer创建目录的过程详见于SparkEnv.scala中create函数。
spark会为每一个提交的application生成一个文件夹,默认位于$SPARK_HOME/work目录下,用以存放从HttpFileServer下载下来的第三方库依赖及Executor运行时生成的日志信息。

实验1
运行spark-shell,查看在/tmp目录下会新产生哪些目录。
#$SPARK_HOME/bin/spark-shell<br>
在/tmp目录下会新增四个与spark-shell相关的文件夹,
spark+随机数目录
分别用于driver本身,driver创建的tmp目录,httpfileserver创建的目录
spark-local目录
用以存放executor执行过程中生成的shuffle output和cache的目录

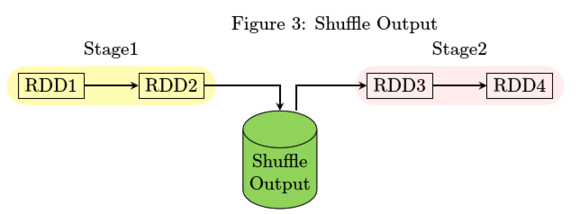
运行中的临时文件Executor在运行的时候,会生成Shuffle Output,如果对RDD进行Cache的话,还有可能会将RDD的内容吐到磁盘中。这些都意味着需要有一个文件夹来容纳这些东西。
在上文中提到的形如spark-local-*的目录就是用以存储executor运行时生成的临时文件。
可以通过两个简单的实验来看spark-local-*目录下内容的变化。
实验2 不进行RDD Cache
进入spark-shell之后运行
spark-shell>sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _).foreach(println)<br>
上述指令会生成两个不同的Stage, 所以会有Shuffle Output,具体划分原因就不再细述了。
如果使用的是spark 1.2.x,可以看到有在spark-local-*目录下有index文件生成。
实验3 进行RDD Cache

进行spark-shell之后运行
<br><p>spark-shell>val rdd1 = sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _)</p><p>spark-shell> rdd1.persist(MEMORY_AND_DISK_SER)</p><p>spark-shell>rdd1.foreach(println)</p>
上述指令执行后,不仅会有index文件还会有形如rdd*的文件生成,这些rdd打头的文件就是cache内容。
配置项
可以通过在$SPARK_HOME/conf/spark-env.sh中指定配置内容来更改默认的存储位置。
SPARK_WORK_DIR 指定work目录,默认是$SPARK_HOME/work子目录
SPARK_LOCAL_DIRS 指定executor运行生成的临时文件目录,默认是/tmp,由于/tmp目录有可能是采用了tmpfs,建议在实际部署中将其更改到其它目录
文件的清理
上述过程中生成的临时文件在什么时候会被删除掉呢?
也许第一感觉就是spark application结束运行的时候呗,直觉有时不见得就是对的。
SPARK_LOCAL_DIRS下的产生的文件夹,确实会在应用程序退出的时候自动清理掉,如果观察仔细的话,还会发现在spark_local_dirs目录有有诸如*_cache和*_lock的文件,它们没有被自动清除。这是一个BUG,可以会在spark 1.3中加以更正。有关该BUG的具体描述,参考 spark-4323 。
$SPARK_LOCAL_DIRS下的*_cache文件是为了避免同一台机器中多个executor执行同一application时多次下载第三方依赖的问题而引进的patch,详见JIRA case spark-2713. 对就的代码见 spark/util/Utils.java中的fetchFile函数 。
如果已经在使用了,有什么办法来清除呢?暴力删除,不管三七二十一,过一段时间将已经存在的cache和lock全部删除。这不会有什么副作用,大不了executor再去下载一次罢了。
<p> find $SPARK_LOCAL_DIRS -max-depth 1 -type f -mtime 1 -exec rm -- {} /;</p> 而SPARK_WORK_DIR目录下的形如app-timestamp-seqid的文件夹默认不会自动清除。
那么可以设置哪些选项来自动清除已经停止运行的application的文件夹呢?当然有。
在spark-env.sh中加入如下内容
<p>SPARK_WORKER_OPTS=”-Dspark.worker.cleanup.enabled=true”</p>
注意官方文档中说不管程序是否已经停止,都会删除文件夹,这是不准确的,只有停止掉的程序文件夹才会被删除,我已提交相应的PR.
写一个简单的WordCount,然后以Standalone Cluster模式提交运行,察看$SPARK_LOCAL_DIRS下文件内容的变化。
import org.apache.spark._ import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.SparkContext._ import java.util.Date object HelloApp { def main(args: Array[String]): Unit = { val conf = new SparkConf() val sc = new SparkContext() val fileName = "$SPARK_HOME/README.md" val rdd1 = sc.textFile(fileName).flatMap(l => l.split(" ")).map(w => (w, 1)) rdd1.reduceByKey(_ + _).foreach(println) var i: Int = 0 while ( i < 10 ) { Thread.sleep(10000) i = i + 1 } } } 提交运行
spark-submit –class HelloApp –master spark://127.0.0.1:7077 --deploy-mode cluster HelloApp.jar
小结
本文通过几个简单易行的实验来观测standalone模式下临时文件的产生和清除,希望有助于理解spark中磁盘资源的申请和释放过程。
Spark部署时相关的配置项比较多,如果先进行分类,然后再去配置会容易许多,分类有CPU、Memory、Network、Security、Disk及Akka相关。
参考
- https://spark.apache.org/docs/1.2.0/submitting-applications.html
- https://spark.apache.org/docs/1.2.0/spark-standalone.html
- http://mail-archives.apache.org/mod_mbox/spark-commits/201410.mbox/%3C2c2ce06abc7d48d48f17f8e458a53219@git.apache.org%3E
- https://issues.apache.org/jira/browse/SPARK-4323
- https://issues.apache.org/jira/browse/SPARK-2713
(责编/钱曙光)
更多《问底》内容:
- 【问底】严澜:数据挖掘入门(一)——分词
- 【问底】Yao Yu谈Twitter的百TB级Redis缓存实践
- 【问底】王帅:深入PHP内核(一)——弱类型变量原理探究
- 【问底】王帅:深入PHP内核(二)——SAPI探究
- 【问底】王帅:深入PHP内核(三)——内核利器哈希表与哈希碰撞攻击
- 【问底】静行:FastJSON实现详解
- 【问底】李平:大型网站的灵魂——性能
- 【问底】许鹏:使用Spark+Cassandra打造高性能数据分析平台(一)
- 【问底】许鹏:使用Spark+Cassandra打造高性能数据分析平台(二)
- 【问底】徐汉彬:大规模网站架构的缓存机制和几何分形学
- 【问底】徐汉彬:亿级Web系统搭建——单机到分布式集群
- 【问底】徐汉彬:Web系统大规模并发——电商秒杀与抢购
- 【问底】徐汉彬:PHP7和HHVM的性能之争
- 【问底】徐汉彬:高并发Web服务的演变——节约系统内存和CPU
- 【问底】OpenStack在天河二号的大规模部署实践
- 【问底】Michael G. Noll:整合Kafka到Spark Streaming——代码示例和挑战
- 【问底】伍艺:一种基于Rsync算法的数据库备份方案设计
- 【问底】陈焕生:深入理解Oracle 的并行执行
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

