云计算时代的深度学习训练

文 | 林亦宁
云计算时代,数据量和数据维度急剧增加,对深度学习训练造成越来越大的压力,来自七牛云的技术专家林亦宁在 OSC 年终盛典上带来了关于深度学习训练的演讲,将就大量分布式集群下,如何高效、可靠地构建深度学习训练计算任务进行了干货分享。以下是他的演讲内容。
云计算和深度学习这两个东西很火,它们只有紧密地联系在一起才能发挥出各自最大的优势。
在与客户或者同行交流的过程中,我们发现除了一些很大的公司,比如 BAT 或链家这样上轨道的公司之外,大部分的公司做算法、深度学习时用的还是单机版的深度学习平台。这样的平台,对于满足目前的数据量、数据吞吐量以及对计算的迭代速度要求,都有很大的局限性,也无法满足现在的处理要求。
Why?
接下来我将会以七牛为例,分享七牛是如何考虑和实现深度学习的。
主要从三个阶段分享,首先是考虑清楚为什么要做这件事。七牛云是一个以云存储技术为核心的云服务公司,平台上现在有 60 多万企业用户和个人开发者, 80% 的手机 App 或多或少都用到了七牛的云存储,几乎在场的每个人的手机里,都有正在用着七牛云存储服务的 App 。
简要介绍一下七牛的历史,七牛一开始做云存储,开发存储 API 。2012、2013 年短视频有了一个爆发式的增长,包括媒体行业都有爆发式的增长,所以七牛随着这一波互联网 App 的兴起也有了爆发式的增长。后来七牛给客户提供了很多基础服务,主要是一些富媒体数据,例如音视频。随后客户提出更多要求,例如需要计算、文件处理、点播以及直播的解决方案等等。所以现在七牛是一个云平台公司,包含以上所有的服务。
第二个阶段是要到哪里去,七牛提出的口号是 「Time to be an AI Company 」,这个口号不仅是内部的,也是对客户的引导。
提出这个口号有两个原因,第一个是内在原因,可以看到移动终端年增长率在逐年下降;另外,三五年前,拿到一个客户需要一块钱,新增一块钱可以多十块钱的利润,这就是很好的生意。但现在拉一个客户成本是十块钱,产生的经济效益也还是十块钱。这个时候,账就算不平了。所以现在并不是一个做 App 创业的好时机。
第二个是外因,现在的应用环境和技术环境,都已经到了一个 AI 可以成熟应用的时间点。应用环境是有海量的富媒体数据,可以通过一些手段充分挖掘出大数据内在的价值;交互方式开始日益多样化,以前是发短信,后来流量多了可以发图片,后来网络好了,又可以发视频,现在可以看直播,直播以前是用聊天室聊天,现在可以发弹幕、送主播「海陆空」。交互方式越来越多样化,带来的好处是能够更容易让用户付费。
另外一点,从技术环境来说,云计算技术和深度学习技术都已经到了一个可以转化为生产力的时间点。30 年前就有了深度网络,那时候还称为神经网络;上个世纪八十年代的东西到现在突然火起来的主要原因是,硬件技术可以实时把推理的结果返回来,而且结果还不错。做一个人脸检测挺准的,这个就是应用环境和技术环境可以把 AI 转化为生产力的时间,给客户提出一个口号,即寻找更多的连接,让这个连接更加智能,使得客户愿意在单位的连接上掏出更多的钱,这个才是以后生意的方式。
所以要给客户设计这样一个机器学习的平台,包括三部分:一个数据,一个算法,一个模型。这是对一个机器学习平台最简单的抽象。
How ?
首先思考需要解决哪些问题,最重要的分为三个方面:效率、规模以及机器学习本身的一些内在性的需求。
规模
所谓的规模问题有三点。一是数据总量增长很快,每年公有云和视频数据增长比例达 60% 多。第二点是数据量非常大,比如七牛有 2000 亿张图片,有超过 10 亿小时的视频,如何去挖掘数据内在的价值,这本身就是一个非常头疼的问题。第三点是吞吐量大,例如 1080P 的摄像头,一个摄像头在一个小时产生的数据是 1.8G,一个城市有几十万个摄像头,像北京这种城市甚至几百万,三个月产生的数据是 EB 级别,数据的吞吐量非常大,所以在设计系统的时候必须能跟上新增数据的节奏。
效率
很多人说现在的互联网是云计算。但是实际上云计算不是一朵云,互联网上也不是只有一朵公有云,而是有很多云,例如存储、日志服务器、计算集群等等。我们的系统需要在这一朵朵云之间架起桥梁,连接起来。很多时候它们不在同一个机房,甚至不在同一个城市,而系统需要在能保证足够的速度和带宽的前提下,让数据可靠地传到最终学习的集群。
规模机器学习的原生需求
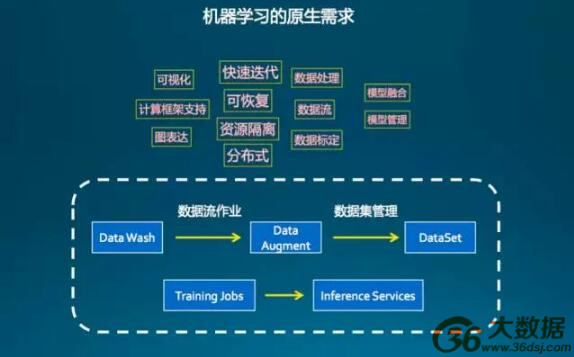
图 1
第三个是机器学习的原生需求,七牛把机器学习的计算过程抽象为两种:数据和训练的作业。原生的需求包括很多方面,图 1 列了几条需求,例如一个是能让整个训练快速迭代;第二个是进程停了可以随时重启,数据应该是安全的;然后是各个训练任务之间需要与它的资源隔离开;训练作业需要分布式。还有其他的需求,例如可视化、模型融合、模型管理,这些都是机器学习本身训练的需求。
What ?
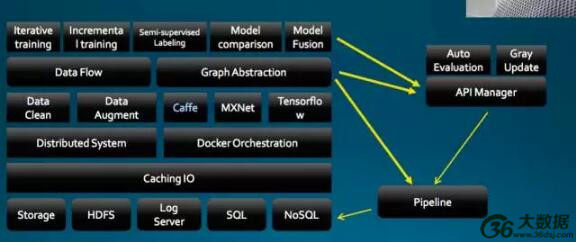
图 2
图 2 是深度学习平台的架构,底层是前面介绍的各个文件系统,在这个上面做了一层 Caching IO ,即分布式内存服务器,计算时所需要的数据都是通过它来做提取,大家可以参考一个开源项目 – AlluxIO ,七牛的设计跟它有一些近似。在 IO 之上抽象为 Docker,来计算任务和资源分配以及调度。在这个基础之上,编排系统也是参考了开源的项目。七牛做这个项目的时间其实比较早,大概一年两年前就做了,主要是担心开源项目任性说不干就不干了,所以自己写了一套东西。
有这么一套编排系统以后,可以很方便地构建一个分布式的系统,它的核心是一个参数服务器,这里推荐一个基于 Caffe 的分布式框架 Poseidon,它针对深度学习任务优化了计算集群内部的通信,在降低通信量的同时保证很好的迭代性。有了分布式的系统和编排系统之后,把上面的作业抽象为一个一个的独立镜像,比如数据清理,有五种数据清理的方法就做五个镜像。数据放大也类似,包括训练和推理,都会做出相应基本的镜像去调用。在这个基础上会把作业全都抽象为一个图的形式表达,以及用数据流的方式去表达整个作业的过程。
这些抽象完了以后,就是上面一个一个的应用,可以看到有迭代学习的需求,有增量学习的一些任务或者半监督的任务,包括模型怎么比较、怎么融合,都是跑在整个系统的 App。这个 App 通过底层这一套基于图和流式的系统来支撑。最后模型训练完了,会有一个 API 的管理系统,这个管理系统可以提供自动的 API 生成,提供自动的评估以及恢复的升级这些功能。
例如训练完一个模型后,但不知道这个模型实际效果如何,这时可以选择一个恢复升级的方式,先升级 10%,再自动验证效果,如果好再升级 30%,可以把这个过程全部编排在 API 里。所有数据到达数据库存里,这就是整个深度学习系统。七牛用电影“机械姬”的女主角之名 Ava 来命名它,希望它能像 Ava 一样冰雪聪明。
下面稍微介绍一下上面跑的几个 App,流式的计算用法,例如一个镜像是一个基本的操作单元,还有一个是 eval 评估服务,只需要把数据流画出一张图,把地址指定,得到结果的集合,这是一个能够极大降低算法人员的工作成本的服务,使算法工程师能更专注算法本身。
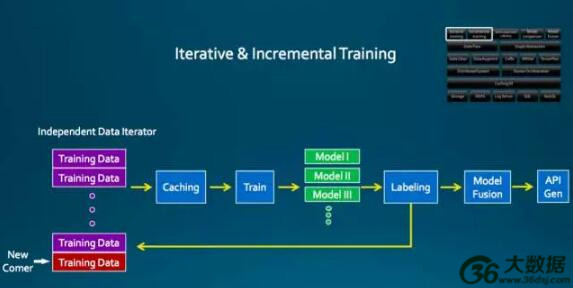
图 3
图 3 是迭代和增量训练的系统,也是基于刚才那一套训练平台开发的 App。为了解决不断有新数据的流式训练的任务,传统的方法需要先建立一个数据文件,现在把这个过程放到一个独立的进程来做。
没有新数据来的时候就会把这个数据编排到整个数据池的底部,在训练的时候可能会用一些 Cheet,会用同个模型,因为不知道是哪个,甚至训练到一半发现不对劲,但是又不想把当前的训练停下来,随时可以开启一个新的训练,用当前这个模型改一个参数让它跑,前面的训练以一个副本的形式在跑,最后达到做模型融合或者模型比较的方法。
最后在模型融合或者模型比较完成以后,把模型推到一个 API 生成器上自动生成 API 。整套过程下来,可以减少总是重复训练同一批数据的环节。
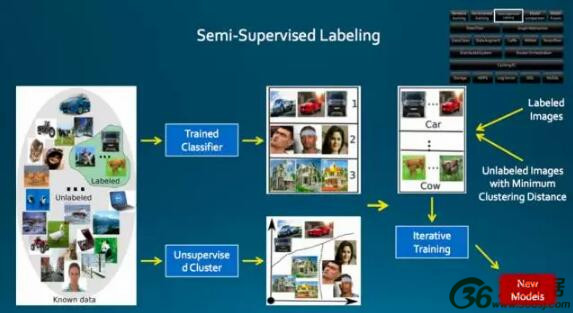
图 4
这个也是七牛做得比较有意思的实验,半监督的方式打标,怎么做?来了数据先保证数据打过标,不过还是会有没打过标的,尤其流式进来的数据,这个数据量很大,打标也很痛苦,七牛用一些训练好的分类器对未打标的数据做分类,同时做一个聚类,未打过标的数据中跟打过标的数据聚类最接近的一些数据,以及标签是一致的数据,用打过标的训练新的模型,这个过程需要迭代,一开始没有打过标的用了 20%,下次迭代一次以后又会加 10%,迭代几轮以后可以很大程度降低一个打标的工作,最后用这样的方式训练新的模型。
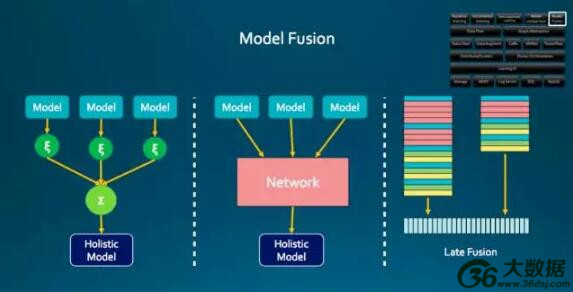
图 5
图 5 是模型融合的方法,列举了三种方法,七牛都在做一些尝试。最简单的是线性的融合方式,比较复杂的是中间有一个网络做融合,第三个比较传统,把融合放在前面一层。用的最多是线性的融合方法,节省资源,也不太伤脑筋。
总结
AI 需要三方面的结合:平台、算法和数据。只有这三点能非常好地结合到一起,才能产生经济效益。
36大数据(www.36dsj.com)成立于2013年5月,是中国访问量最大的大数据网站。36大数据(微信号:dashuju36)以独立第三方的角度,为大数据产业生态图谱上的需求商 、应用商、服务商、技术解决商等相关公司及从业人员提供全球资讯、商机、案例、技术教程、项目对接、创业投资及专访报道等服务。
End.
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

