Spark常见问题解决办法
以下是在学习和使用spark过程中遇到的一些问题,记录下来。
1、首先来说说spark任务运行完后查错最常用的一个命令,那就是把任务运行日志down下来。 程序存在错误,将日志down下来查看具体原因!down日志命令:yarn logs -applicationId app_id
2、Spark性能优化的9大问题及其解决方案
Spark程序优化所需要关注的几个关键点——最主要的是数据序列化和内存优化
问题1:reduce task数目不合适
解决方法:需根据实际情况调节默认配置,调整方式是修改参数spark.default.parallelism。通常,reduce数目设置为core数目的2到3倍。数量太大,造成很多小任务,增加启动任务的开销;数目太少,任务运行缓慢。
问题2:shuffle磁盘IO时间长
解决方法:设置spark.local.dir为多个磁盘,并设置磁盘为IO速度快的磁盘,通过增加IO来优化shuffle性能;
问题3:map|reduce数量大,造成shuffle小文件数目多
解决方法:默认情况下shuffle文件数目为map tasks * reduce tasks. 通过设置spark.shuffle.consolidateFiles为true,来合并shuffle中间文件,此时文件数为reduce tasks数目;
问题4:序列化时间长、结果大
解决方法:Spark默认使.用JDK.自带的ObjectOutputStream,这种方式产生的结果大、CPU处理时间长,可以通过设置spark.serializer为org.apache.spark.serializer.KryoSerializer。另外如果结果已经很大,可以使用广播变量;
问题5:单条记录消耗大
解决方法:使用mapPartition替换map,mapPartition是对每个Partition进行计算,而map是对partition中的每条记录进行计算;
问题6:collect输出大量结果时速度慢
解决方式:collect源码中是把所有的结果以一个Array的方式放在内存中,可以直接输出到分布式?文件系统,然后查看文件系统中的内容;
问题7:任务执行速度倾斜
解决方式:如果是数据倾斜,一般是partition key取的不好,可以考虑其它的并行处理方式 ,并在中间加上aggregation操作;如果是Worker倾斜,例如在某些worker上的executor执行缓慢,可以通过设置spark.speculation=true 把那些持续慢的节点去掉;
问题8:通过多步骤的RDD操作后有很多空任务或者小任务产生
解决方式:使用coalesce或repartition去减少RDD中partition数量;
问题9:Spark Streaming吞吐量不高
解决方式:可以设置spark.streaming.concurrentJobs
3、intellij idea直接编译spark源码及问题解决:
http://blog.csdn.net/tanglizhe1105/article/details/50530104
http://stackoverflow.com/questions/18920334/output-path-is-shared-between-the-same-module-error
Spark编译:clean package -Dmaven.test.skip=true
参数:-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m
4、import Spark source code into intellj, build Error:
not found: type SparkFlumeProtocol and EventBatch
http://stackoverflow.com/questions/33311794/import-spark-source-code-into-intellj-build-error-not-found-type-sparkflumepr
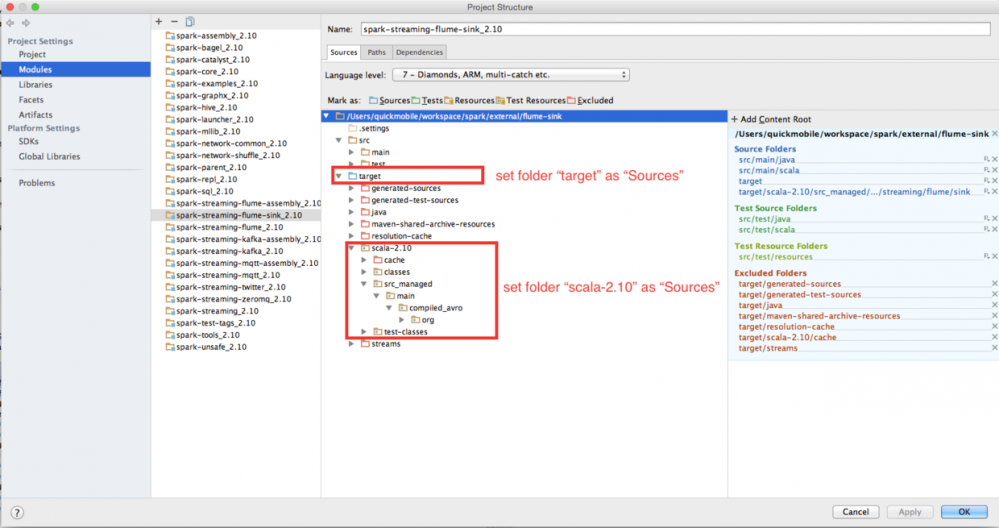
spark_complie_config.png
5、org.apache.spark.SparkException: Exception thrown in awaitResult
set "spark.sql.broadcastTimeout" to increase the timeout
6、Apache Zeppelin编译安装:
Apache Zeppelin installation grunt build error:
解决方案:进入web模块npm install;
http://stackoverflow.com/questions/33352309/apache-zeppelin-installation-grunt-build-error?rq=1
7、Spark源码编译遇到的问题解决:http://www.tuicool.com/articles/NBVvai
内存不够,这个错误是因为编译的时候内存不够导致的,可以在编译的时候加大内存。
[ERROR] PermGen space -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors,re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions,
please read the following articles:
[ERROR] [Help 1]http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryError
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
8、Exception in thread "main" java.lang.UnsatisfiedLinkError: no jnind4j in java.library.path
解决方案:I’m using a 64-Bit Java on Windows and still get the no jnind4j in java.library.path error It may be that you have incompatible DLLs on your PATH. In order to tell DL4J to ignore those you have to add the following as a VM parameter (Run -> Edit Configurations -> VM Options in IntelliJ): -Djava.library.path=""
9、spark2.0本地运行源码报错解决办法:
修改对应pom中的依赖jar包,将scope级别由provided改为compile
运行类之前,去掉make选项;在运行vm设置中增加-Dspark.master=local
Win7下运行spark example代码报错:
java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: file:D:/SourceCode/spark-2.0.0/spark-warehouse修改SQLConf类中WAREHOUSE_PATH变量,将file:前缀改为file:/或file:///
createWithDefault("file:/${system:user.dir}/spark-warehouse")
local模式运行:-Dspark.master=local
10、解决Task not serializable Exception错误
方法1:将RDD中的所有数据通过JDBC连接写入数据库,若使用map函数,可能要为每个元素都创建connection,这样开销很大,如果使用mapPartitions,那么只需要针对每个分区建立connection;mapPartitions处理后返回的是Iterator。
方法2:对未序列化的对象加@transisent引用,在进行网络通信时不对对象中的属性进行序列化
11、这个函数在func("11")调用时候正常,但是在执行func(11)或func(1.1)时候就会报error: type mismatch的错误. 这个问题很好解决
针对特定的参数类型, 重载多个func函数,这个不难, 传统JAVA中的思路, 但是需要定义多个函数
使用超类型, 比如使用AnyVal,Any;这样的话比较麻烦,需要在函数中针对特定的逻辑做类型转化,从而进一步处理上面两个方法使用的是传统JAVA思路,虽然都可以解决该问题,但是缺点是不够简洁;在充满了语法糖的Scala中,针对类型转换提供了特有的implicit隐式转化的功能;
12、org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle
解决方案:这种问题一般发生在有大量shuffle操作的时候,task不断的failed,然后又重执行,一直循环下去,直到application失败。一般遇到这种问题提高executor内存即可,同时增加每个executor的cpu,这样不会减少task并行度。
13、Spark ML PipeLine GBT/RF预测时报错,java.util.NoSuchElementException: key not found: 8.0
错误原因:由于GBT/RF模型输入setFeaturesCol,setLabelCol参数列名不一致导致。
解决方案:只保存训练算法模型,不保存PipeLineModel
14、linux删除乱码文件,step1. ls -la; step2. find . -inum inode num -exec rm {} -rf /;
15、Caused by: java.lang.RuntimeException: Failed to commit task Caused by: org.apache.spark.executor.CommitDeniedException: attempt_201603251514_0218_m_000245_0: Not committed because the driver did not authorize commit
如果你比较了解spark中的stage是如何划分的,这个问题就比较简单了。一个Stage中包含的task过大,一般由于你的transform过程太长,因此driver给executor分发的task就会变的很大。所以解决这个问题我们可以通过拆分stage解决。也就是在执行过程中调用cache.count缓存一些中间数据从而切断过长的stage。

正文到此结束
- 本文标签: 解决方法 apache 删除 ip 配置 executor CTO lib windows 数据库 Jobs NSA id 参数 java http pom 安装 cache Full Stack build 源码 Logging find IDE Master 快的 linux ask maven map ORM 时间 example 编译 Job confluence 数据 文件系统 key core db sql scala 代码 Connection web ACE UI IO App src node cat Features SDN 分布式
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

