G1收集器中的to-space exhausted问题一则
最近刚刚将自己的一个应用从CMS升级到G1,在一天早上,刚刚到办公室坐下,就收到手机一阵报警,去查看了监控,发现机器的内存出现了一个90度的涨幅,如下图所示:
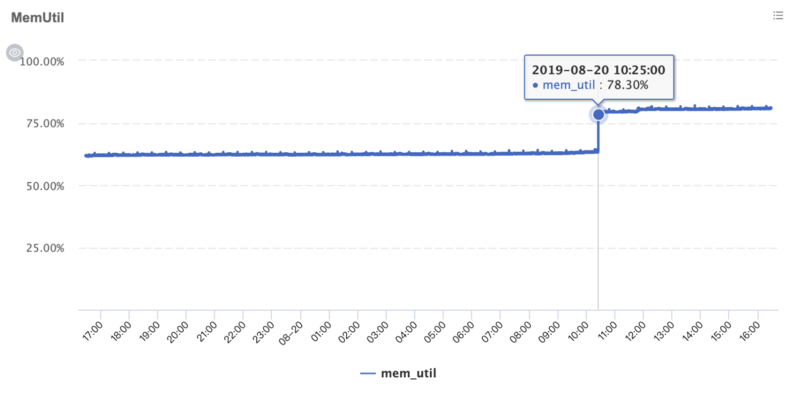
在查看GC日志后,发现那个时间点附近出现了“to-space exhausted”这种日志
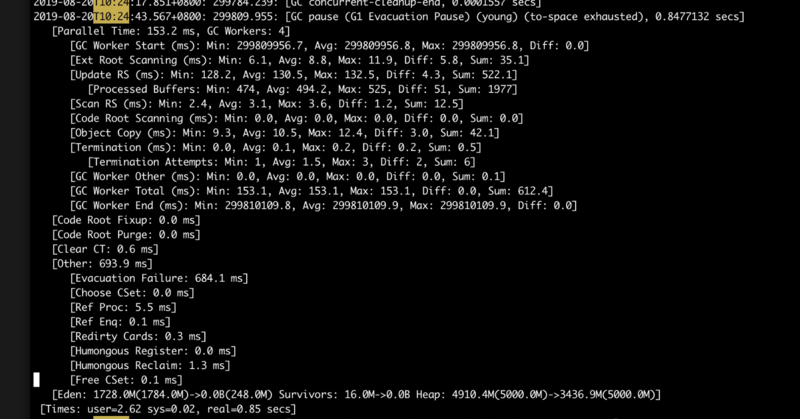
在这里,我比较奇怪的是为啥to-sapce exhausted会导致整个机器的内存激增。我们JVM团队同学给我的解释是: 老区不够了,这个时候会把young区所有对象不管死活都转成old区对象,所以总的内存使用量会暴增 。这一个知识点,我之前学习G1的时候还真没有get到。
不过,我有另外一个疑问:xmx和xms相同的话堆空间应该不变,一开始就分配5g,然后加上非堆内存,那么java进程起来后就会超过5g,这是没问题的;但是这里利用空闲的内存也应该是利用堆上的空间,然后整体的内存块应该已经分配出去了,应该不会出现机器内存激增的情况。JVM团队的同学给我解释道:没有,第一次读写到了才会实际从os分配出来物理内存。
针对上面的问题,我们最终确定了下面的调优建议:
- 这次没有发生FGC,可能是由于我前面将xmx和xms调大了导致的,这次准备将xmx和xms先调回到原来的值;
- 加上HeapDumpAfterFullGC参数,下次再发生类似情况的时候,就会触发FGC,然后自动dump堆内存,就可以针对堆内存进行分析,看看是什么对象占用了这么多内存,然后就可以针对性优化。
关于to-space exhausted的更多总结
基于上面这个问题,我又去找了一些资料,整理如下。
《Java性能权威指南》
在这本书的123页有提到,上面这种情况属于晋升失败的情况——G1收集器完成了标记阶段,开始启动混合式垃圾收集,准备要清理老年代分区,但是老年代分区在垃圾收集器释放出足够的空间之前就已经被耗尽了。这种失败通常意味着混合式垃圾收集需要更迅速得完成垃圾收集,每次新生代垃圾收集需要处理更多的老年代分区。一般来说,一系列的to-space exhausted之后会跟着一次FGC。
在我们上面的这个例子中,是old区的使用速度超过了垃圾收集器的回收速度,因此可以考虑两种调优的思路
-XX:InitiatingHeapOccupancyPercent=N -XX:G1MixedGCCountTarget=N
《Java性能调优指南》
要特别关注日志片段中的"to-space exhausted"和“Evacuation Failure”两个日志,如下图所示 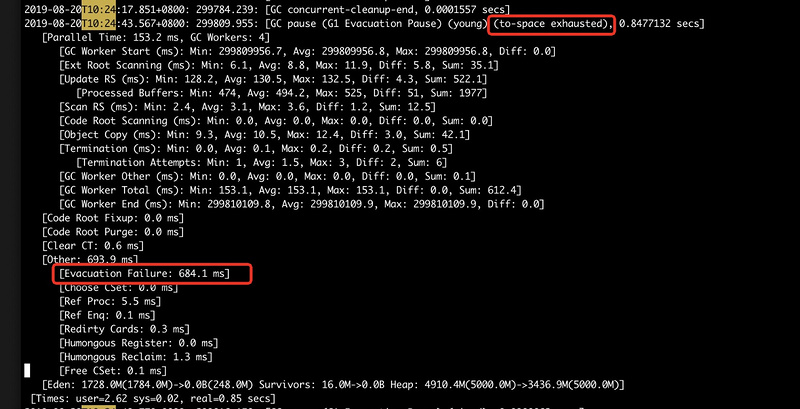
这种情况属于失败的情况,这本书给出了两点建议:
-XX:InitiatingHeapOccupancyPercent=N -XX:ConcGCThreads -XX:G1ReservePercent
总结
JVM参数的调优,是一个不断推导和尝试的过程,其中最重要的数据就是GC日志和Java堆内存快照,因此:(1)在JVM参数中一定要设置HeapDumpAfterFullGC和HeapDumpOnOutOfMemoryError两个参数,可以在发送FGC和OOM的时候将当时的Java堆情况记录下来,用于事后分析;(2)GC日志要单独打印到一个日志文件中,方便分析,如果不特别设置,GC日志会打印到stdout.log中,会有其他的日志混合在中间,影响问题排查。
JVM的参数调优并不是万能的,发生OOM或者FGC的时候,业务代码中也一定有不合理的地方,需要做合理的限制和优化,不能将所有的事情都交给JVM抗。
本号专注于后端技术、JVM问题排查和优化、Java面试题、个人成长和自我管理等主题,为读者提供一线开发者的工作和成长经验,期待你能在这里有所收获。

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

