在Solr中配置和使用ansj分词
一、下载或者编译ansj-seg和nlp-lang等jar包。
1、您可以到 http://maven.ansj.org/org/ansj/ansj_seg/ | http://maven.ansj.org/org/nlpcn/ 中下载相关jar包。
ansj-seg相关jar包,如下图所示:

nlp-lang 是ansj-seg分词中关于自然语言处理相关工具类,功能比较强大:

2、下载相关源码,自己编译。
这种是相对复杂的,但是如果长久使用,这种是很有必要的。对于这种优秀的分词,我们更有必要好好研究一番。
github地址:https://github.com/NLPchina/ansj_seg
git客户端地址:http://git-scm.com/download/
git下载源码命令:git clone https://github.com/NLPchina/ansj_seg.git
下载后的文件结构如下:
可见代码是用maven组中管理的。对于maven的安装配置本文旧粗略带过,主要包括:
下载maven相关包,解压:
配置环境变量M2_HOME:C:/apache-maven-3.2.1
配置PATHb环境变量:%M2_HOME%/bin;
mvn常有命令:mvn clean install#清理本地缓存、下载依赖jar包 可以添加-DskipTests=true忽略单元测试;mvn eclipse:clean #清理mvn生成的eclipse工程;mvn eclipse:eclipse #根据pom.xml生成eclipse工程。
步骤:
在源码根路径下执行: mvn clean install -DskipTests=true 命令,在target目录下生成jar包。
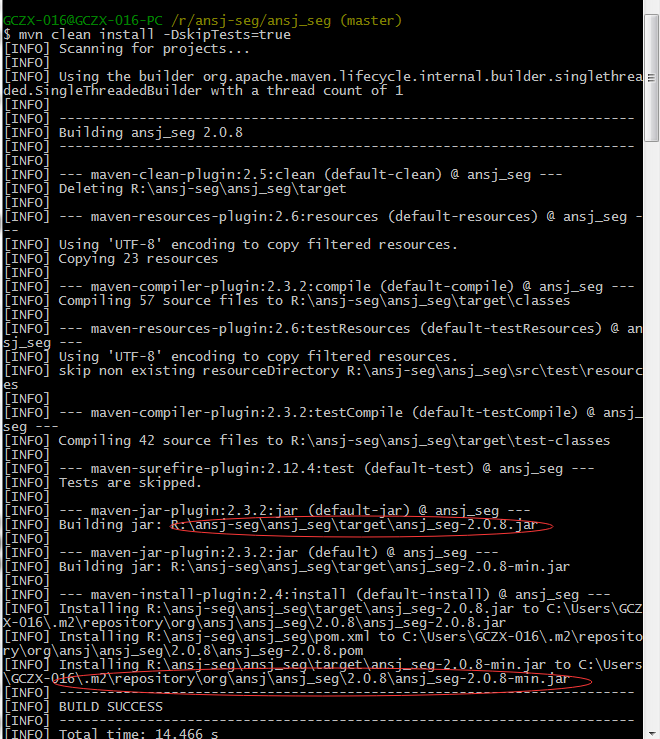
target目录:
同义的道理,可以编译nlp-lang jar包,地址:https://github.com/NLPchina/nlp-lang
二、在solr schema.xml中配置好ansj字段类型。
1、创建ansj类型。
找到schema.xml,添加ansj类型text_ansj:
<!--ansj start --> <fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.ansj.solr.AnsjTokenizerFactory" isQuery="false"/> </analyzer> <analyzer type="query"> <tokenizer class="org.ansj.solr.AnsjTokenizerFactory"/> </analyzer> </fieldType> <!--ansj end -->
org.ansj.solr.AnsjTokenizerFactory 是我们编译的ansj-lucene插件。
2、配置需要索引的字段。
<!-- ansj_test field --> <field name="POI_OID" type="string" indexed="false" stored="true"/> <field name="POI_NAME" type="text_ansj" indexed="true" stored="false"/> <field name="POI_NAME_SUGGEST" type="string" indexed="false" stored="true"/> <field name="POI_ADDRESS" type="text_ansj" indexed="true" stored="false"/> <field name="POI_ADDRESS_SUGGEST" type="string" indexed="false" stored="true"/> <field name="POI_PHONE" type="string" indexed="true" stored="true"/> <field name="POI_TYPE" type="string" indexed="true" stored="true" multiValued="true"/> <field name="POI_URL" type="string" indexed="false" stored="true"/> <field name="POI_DIANPING" type="string" indexed="true" stored="true" /> <field name="POI_BRAND" type="string" indexed="true" stored="true"/> <field name="POI_CITY" type="string" indexed="true" stored="true" multiValued="true"/> <field name="POI_TAG" type="text_ansj" indexed="true" stored="true"/> <field name="POI_LAT" type="double" indexed="false" stored="true"/> <field name="POI_LON" type="double" indexed="false" stored="true"/> <field name="POI_DATA_TYPE" type="string" indexed="true" stored="false"/>
三、在solr环境中配置好ansj。
在编译好的ansj-seg、nlp-lang、ansj_lucene4_plug 放到solr war包的lib下。
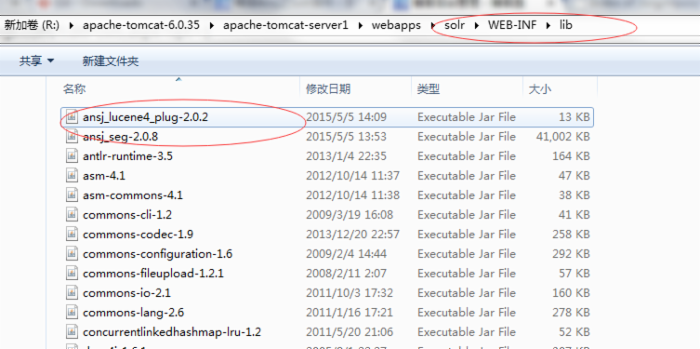

配置ansj相关词库和配置文件,这些配置文件在ansj源码目录下:
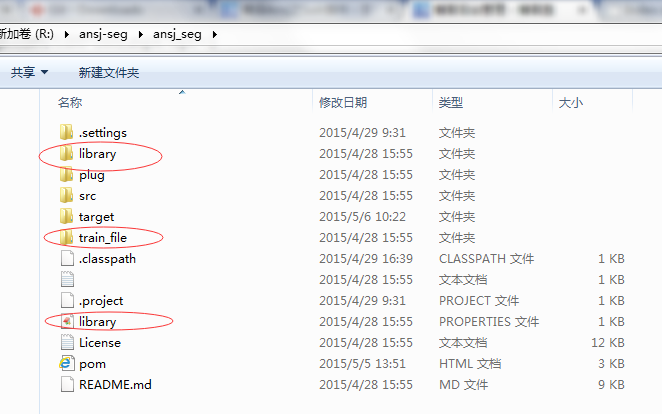
把这三个配置文件放到solr程序WEB-INF/classes目录下,classes目录不存在则手动创建。

四、测试ansj分词效果。
ansj配置好了以后,把solr所在的tomcat启动一下。用solr管理页面查看效果:
1、测试分词 "南京市长江大桥”

备注:在文本框中输入“南京市长江大桥” 点击右边蓝色的按钮“ ”
文章转载,请注明出处:http://www.cnblogs.com/likehua/p/4481219.html
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

