面试官:简历上说精通垃圾收集器?来吧,挨个给我说一遍

面试官:你认识到的收集器都有哪些啊?
答:Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1;
面试官:为什么HotSpot虚拟机需要这么多收集器?
答:HotsSpot垃圾是分代收集的,所以不用的分代收集器也不同,即使是同一年代里收集器也会不同,因为每个收集器特点和性能不同也就有了收集器的多样性,所以各个收集器互相组合使用才能适应不同场景。
面试官:那你说一下每个收集器都有什么特点吧!
新生代收集器:Serial、ParNew、Parallel Scavenge;
老年代收集器:Serial Old、Parallel Old、CMS;
整堆收集器:G1;
开始之前我们了解一个概念
Minor GC
又称新生代GC,指发生在新生代的垃圾收集动作;
因为Java对象大多是朝生夕灭,所以Minor GC非常频繁,一般回收速度也比较快;
Full GC
又称Major GC或老年代GC,指发生在老年代的GC;
出现Full GC经常会伴随至少一次的Minor GC(不是绝对,Parallel Sacvenge收集器就可以选择设置Major GC策略);
Major GC速度一般比Minor GC慢10倍以上;
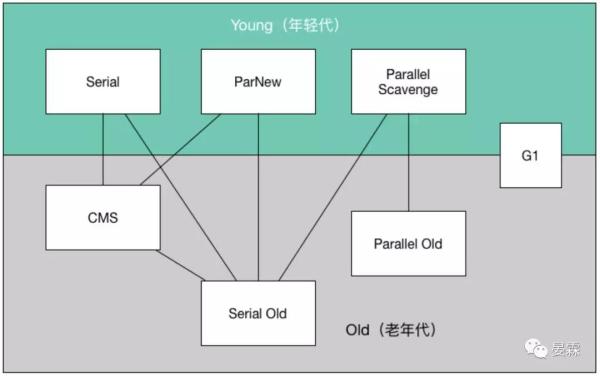
Serial收集器
这个收集器是最基本的,也是历史最悠久的收集器,目前基本不会用了,想当年那也是新生代的唯一选择,但是这么多年过去了,HotSpot也没有说过河拆桥把它废了,“老而无用、食之无味弃之可惜”。
他是一个单线程收集器,他在工作的时候,必须暂停其他所有的工作线程,直到收集结束。这里要知道一个很严重的问题就是,暂停一切线程的结果就是当前运行在这个JDK的所有程序里的用户线程全部暂停,也就是说这一瞬间都是死掉的,用户看到的现象就是页面无任何响应,如果这种现象出现的时间长且频繁用户就崩溃了。
这里埋下了一个伏笔,越优秀的收集器,他的停顿时间一定越短,这也是所有收集器共同追求的目标。
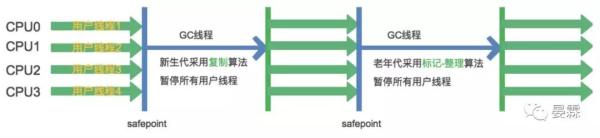
ParNew收集器
他是Serial收集器多线程版本,其所有控制参数、收集算法、对象分配规则、回收策略等都与Serial完全一样。下面是ParNew收集器工作的过程。
他的重要之处在于,除了多线程提高了性能之外,他还可以与CMS收集器(下面介绍)搭配使用的原因。
在单CPU环境下ParNew的性能没办法超过Serial,但是随着CPU数量增多他的优势就会越来越明显。
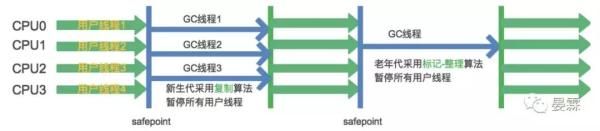
Parallel Scavenge收集器
他也是一款新生代收集器,使用的是复制算法,并且是并行对线程收集器。可以看到收集器的进步都是保留上一代之长,弥补上一代之短。
很多收集器关注用户线程的停顿时间,但是Parallel Scavenge则关注吞吐量。所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),例:虚拟机运行100分钟,其中垃圾收集时间用了1分钟,那吞吐量就是99%。
他是怎样控制吞吐量呢?
使用参数控制最大垃圾收集停顿时间 -XX:MaxGCPauseMillis ,以及直接设置吞吐量大小 -XX:GCTimeRatio参数。
MaxGCPauseMillis参数是一个大于0的毫秒数,收集器一次工作尽可能不超过设定的这个值,但是设置太小GC停顿时间缩短,造成了垃圾收集频率变快。如果你设定停顿100毫秒,10秒收集一次的频率,改成70毫秒的停顿时间,那么频率就可能变成5秒一次。停顿时间下降,吞吐量也会下降,GC还会变得更频繁。
XX:GCTimeRatio参数设置垃圾收集时间占总时间的比率,0
GCTimeRatio相当于设置吞吐量大小;
垃圾收集执行时间占应用程序执行时间的比例的计算方法是:1 / (1 + n)
例如,选项-XX:GCTimeRatio=19,设置了垃圾收集时间占总时间的5%--1/(1+19);
默认值是1%--1/(1+99),即n=99;
看来找准最优的临界点真的是Parallel Scavenge收集器比较配置的。
不要担心,HotSpot又提供了一个参数 XX:+UseAdptiveSizePolicy帮助我们实现GC自适应的调节策略,他会根据当前系统运行情况收集性能监控信息,动态调整这些参数,以提供最合适的停顿时间或最大的吞吐量。
这个参数开启,JVM就可以动态分配新生代的大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRation)、晋升老年代的对象年龄(-XX:PretenureSizeThreshold)等;
这里插入一个笔者的经历:当时面试有人问我,Eden与Survivor区的比例可以变化吗?
看到这里童鞋们就可以回答:Parallel Scavenge收集器开启 XX:+UseAdptiveSizePolicy可以动态分配。
这也是Parallel Scavenge收集器优越于ParNew收集器一个重要点。
Serial Old收集器
Serial Old是 Serial收集器的老年代版本,也是继承Serial收集器单线程的特点。
工作模型图在Serial收集器中展示了。
Parallel Old收集器
Parallel Old垃圾收集器是Parallel Scavenge收集器的老年代版本,继承了Parallel New多线程对特点,在JDK1.6及之后用来代替老年代的Serial Old收集器;
参数"-XX:+UseParallelOldGC":指定使用Parallel Old收集器;
工作模型图在Parallel New收集器中展示了。
接下来讲解CMS于G1收集器,在将之前要理解一个概念
可能前面也提到过,不过在这里了解以下也不晚
并行(Parallel)
指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态;
如ParNew、Parallel Scavenge、Parallel Old;
并发(Concurrent)
指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行);
用户程序在继续运行,而垃圾收集程序线程运行于另一个CPU上;
如CMS、G1(也有并行);
CMS收集器
并发标记清理收集器也称为并发低停顿收集器或低延迟垃圾收集器;他的宗旨是:低停顿。
HotSpot在JDK1.5推出的第一款真正意义上的并发(Concurrent)收集器;
他采用的是“标记-清除算法",因此会生大量的空间碎片。为了解决这个问题,CMS可以通过配置以下两种参数解决:
- -XX:+UseCMSCompactAtFullCollection:参数,强制JVM在FGC完成后対老年代迸行圧縮,执行一次空间碎片整理,但是空间碎片整理阶段也会引发STW。为了减少STW次数,CMS还可以通过配置。
- -XX:+CMSFullGCsBeforeCompaction=n :参数,在执行了n次FGC后, JVM再在老年代执行空间碎片整理
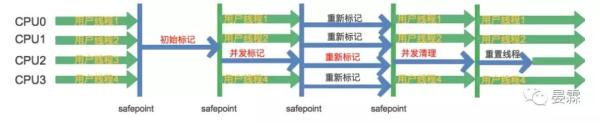
初始标记 (Initial Mark)
停止一切用户线程,仅使用一条初始标记线程对所有与GC Roots直接相关联的 老年代对象进行标记,速度很快
并发标记 (Concurrent Marking Phase)
使用多条并发标记线程并行执行,并与用户线程并发执行.此过程进行可达性分析,标记所有这些对象可达的存货对象,速度很慢
重新标记 ( Remark)
因为并发标记时有用户线程在执行,标记结果可能有变化
停止一切用户线程,并使用多条重新标记线程并行执行,重新遍历所有在并发标记期间有变化的对象进行最后的标记.这个过程的运行时间介于初始标记和并发标记之间
并发清除 (Concurrent Sweeping)
只使用一条并发清除线程,和用户线程们并发执行,清除刚才标记的对象
这个过程非常耗时
G1收集器
G1(Garbage-First)是JDK7-u4才推出商用的收集器;他比CMS更高级了,他是并行与并发,能充分利用多CPU、多核环境下的硬件优势;
G1以下特点
并行与并发
能充分利用多CPU、多核环境下的硬件优势;
可以并行来缩短"Stop The World"停顿时间;
也可以并发让垃圾收集与用户程序同时进行;
分代收集,收集范围包括新生代和老年代
能独立管理整个GC堆(新生代和老年代),而不需要与其他收集器搭配;
能够采用不同方式处理不同时期的对象;
虽然保留分代概念,但Java堆的内存布局有很大差别;
将整个堆划分为多个大小相等的独立区域(Region);
新生代和老年代不再是物理隔离,它们都是一部分Region(不需要连续)的集合;
结合多种垃圾收集算法,空间整合,不产生碎片
从整体看,是基于标记-整理算法;
从局部(两个Region间)看,是基于复制算法;
这是一种类似火车算法的实现;
都不会产生内存碎片,有利于长时间运行;
可预测的停顿:低停顿的同时实现高吞吐量
G1除了追求低停顿处,还能建立可预测的停顿时间模型;
可以明确指定M毫秒时间片内,垃圾收集消耗的时间不超过N毫秒;
如:在堆大小约6GB或更大时,可预测的暂停时间可以低于0.5秒;
用来替换掉JDK1.5中的CMS收集器;
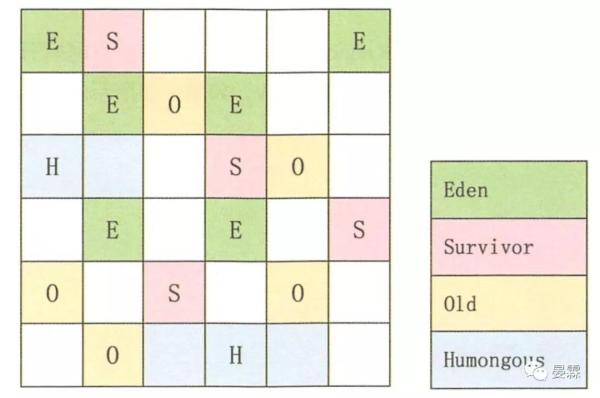
上面提到Region 概念,肯定都不会理解,让我们看一下G1的内存模型
G1将Java堆空间分割成了若干相同大小的区域,即region
Humongous是特殊的Old类型,专门放置大型对象
在JDK11中,已经将G1设为默认垃圾回收器
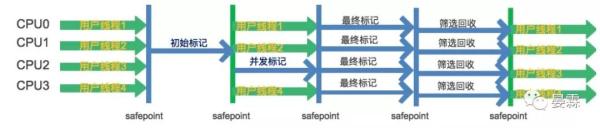
G1垃圾收集过程
初始标记
标记与GC Roots直接关联的对象,停止所有用户线程,只启动一条初始标记线程,这个过程很快。
并发标记
进行全面的可达性分析,开启一条并发标记线程与用户线程并行执行.这个过程比较长。
最终标记
标记出并发标记过程中用户线程新产生的垃圾.停止所有用户线程,并使用多条最终标记线程并行执行。
筛选回收
回收废弃的对象.此时也需要停止一切用户线程,并使用多条筛选回收线程并行执行。
题外话:我们知道目前为止JDK8是应用最广泛对版本,并且JDK9、10是一个过度版,企业应用效果不好,JDK11是一个里程碑版本,重要程度相当于现在JDK8,并且JDK11默认使用G1收集器,G1的性能在早些年就突出于CMS并且官方对性能测试结果也是这样说明的。
本文转载自微信公众号「 晏霖」,可以通过以下二维码关注。转载本文请联系 晏霖公众号。

正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

