【话疗Java】从位运算表达式中看JVM的栈帧设计
最近接盘了公司的分布式文件存储系统,其底层不出意外的采用FastDFS以及HBase作为存储中间件,在熟悉代码的时候,对FastDFS客户端的部分代码产生了疑惑,如果你看完没有疑惑就没必要继续往下阅读了,关掉页面左转,刷刷沸点,摸摸鱼不香吗?
如下图所示这是一个将字节数组转换为long的函数, 格式为big-endian(大端)
FastDFS的协议头中有8个字节用来标识数据包的长度,此函数就用于获取数据包的长度
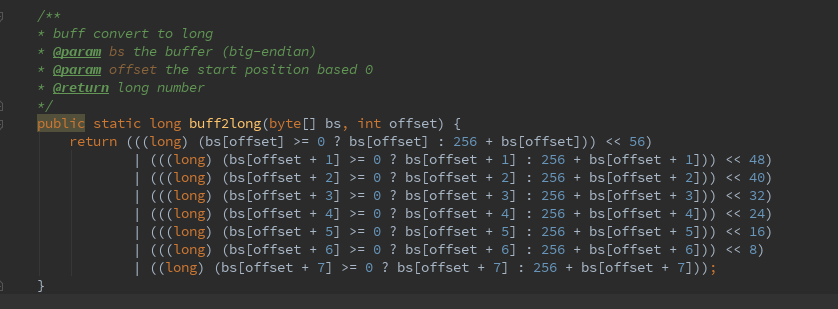
初看觉得这就是普通的移位操作没有任何疑惑,再细看发现不少问题
- 为什么对正负数区别对待
- 为什么值为负数的时候要先加上负数再移动位数呢?
要解决这个问题,先简单回顾一下二进制的知识。
0x01 二进制编码
上大学时,总觉得老师讲的很无聊,上课时候总是从书包里掏出其他技术书籍来看,我总是做在后排最靠近窗户的VIP座位,自然发现不了我在开小差,但有句话我记住了
如果以后你们以后打算继续从事这一行,你们现在欠下的技术债,总是要还的
如今,他应验了。

但凡谈及二进制,有符号数和无符号数的话题就不得不说道说道了,但是由于Java中不存在无符号数,因此重点谈一下 有符号数 的表示方法。
对于如何表示有符号数,通常有一下几种二进制编码方案
- 反码
- 原码
- 补码
反码和原码的表示方法都有一个奇怪的熟悉,那就是对于数字0有两种不同的编码方式。这两种表示方法都有一个奇怪的属性,把[00..0]都解释为+0,而-0在 在原码中表示[10..0],在反码中表示为[11...1]. 但是几乎所有的现代的机器都使用补码来表示有符号数,包括Java。
引用自《CSAPP》
anyway,反码和原码并不是讨论的重点,重点看一下补码是怎么一回事.
对于一个补码,其最高位用来表示正负,为0为正数, 为1则为负数.
一个严谨的补码定义如下
还是引自《CSAPP》

- 向量指的是二进制编码的数据,如x6指的就是二进制编码中第6位的值,x只可能取1或0
- 通过此公式我们可以将补码转为对应的十进制数
如以下例子
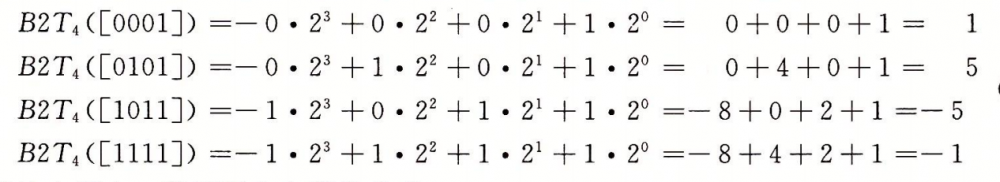
0x02 你确定byte真的只占一个字节吗?
如下代码所示, 对一个byte变量进行简单的位运算操作并将其值赋值给另一个byte变量时,编译器会提示 从int转换到byte可能会有损失
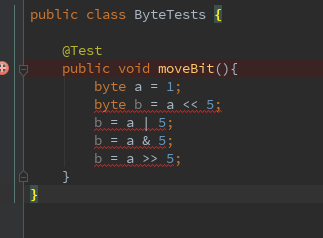

这有可能的是语法层面的限制, 又或许有其他原因呢?
毕竟鲁迅说过,最终所有问题都会追溯到底层设计。
既然鲁迅发话了,就让我们来瞅一眼位运算在字节码层面是如何实现的
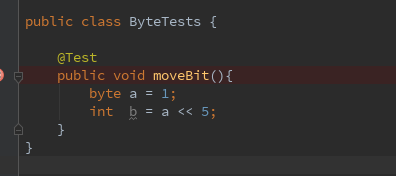
Java代码与字节码代码的对应的关系如下图所示
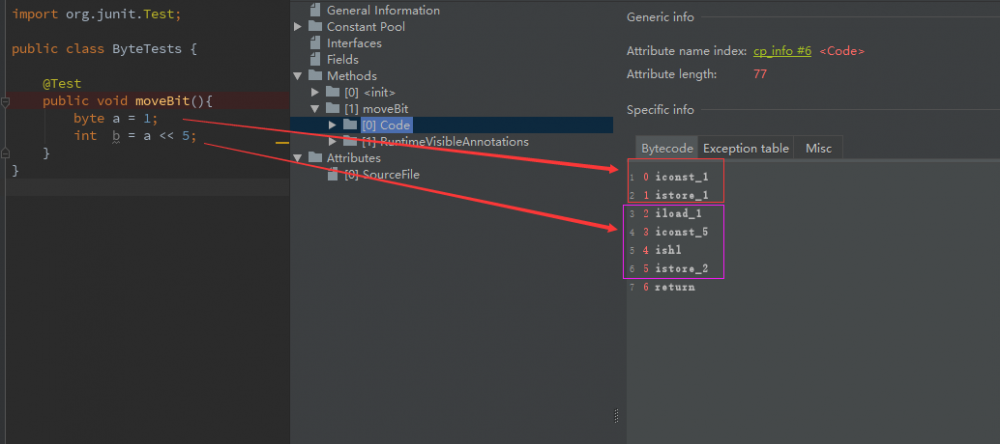
本次代码涉及到的指令不多,咱先简单介绍一下
| 字节码指令 | 作用 |
|---|---|
| iconst_1 | 将 int 值1推入操作数栈 |
| iconst_5 | 将 int 值5推入操作数栈 |
| istore_1 | 对操作数栈执行出栈操作,将返回的值赋值本地给变量表的第一个元素,此值必须是int |
| iload_1 | 将本地变量表的第一个元素推入操作数栈,此时该值位于操作数栈顶 |
| ishl | 从操作数栈中出战两个元素val1, val2,将val1左移val2位,val1和val2类型必须为int,并将结果入栈(保存到栈顶) |
| istore_2 | 对操作数栈执行出栈操作,将返回的值赋值本地给变量表的第二个元素,此值必须是int |
操作数栈和本地变量表是啥玩意咱先暂且不论(下文再谈),但根据字节码指令来分析的话,不难得出结论,你以为你用的是byte实际上在JVM的视角来说你用的是int.
这也就是意味 byte a =-5 的实际上的二进制补码是 11111111111111111111111111111011 ,我们的目的是将 111111011 左移N位让其回到原来的位置. 此时,如果不对负数进行处理的情况下将byte数组还原为long则必然会遇到与原数据不一致的情况,对于此种情况只需要将其与0xFF进行与运算即可获取到原数据
11111111 11111111 11111111 11111011 & 00000000 00000000 00000000 11111111 = 00000000 00000000 00000000 11111011 复制代码
经过如此操作再对其进行移位操作就可以将数据正确的还原到原本的位置,皆大欢喜.
上文中 256+bs[offset] 实际上等效于 bs[offset] & 0xFF
为什么会等效呢? 如果你熟悉二进制加法其实很简单,在此咱们先简单回顾一下二进制加法的规则
- 1 + 0 = 1+ 0 = 0
- 0 + 0 = 0
- 1 + 1 = 10
而
256=00000000 00000000 00000001 00000000
+
bs[offset]=11111111 11111111 11111111 11111011
即可得到 000000000000000000000000 11111011 等效于 bs[offset] & 0xFF
那么为什么此处要用加法来实现这种操作呢?
呃...也许是个人喜好吧,又或者加法效率比较高?有不同看法欢迎在评论区指出哈
0x03 字节码是如何执行的
前面铺垫了这么多,终于该回归标题了,否则就成了标题党.
我们知道JVM以方法作为最基本的执行单位,栈帧(StackFrame)则是支撑虚拟机进行方法调用和方法执行的数据结构。栈帧存储了方法的本地变量表、操作数栈、动态连接和方法返回信息等数据。在编译的时候就已经确定了需要多深的操作数栈以及多大的本地变量表。本地变量表中存放着方法执行期间所用到变量.
以上文的moveBit方法为例,其代码如下所示,此方法有两个变量
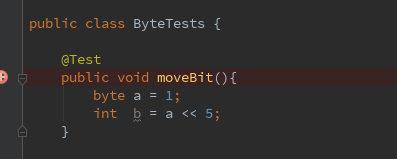
那么在执行方法调用时,其操作数栈和本地变量表如下图所示

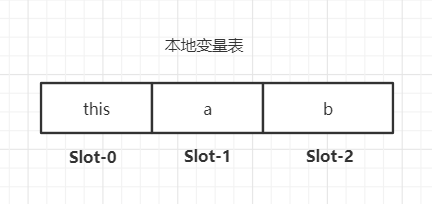
初看此图,你可能会有疑惑,为啥本地变量表里面还有this?实际上这个操作是编译器帮你做,你能在方法中使用this全赖于此.举个相反的例子,在Python的面向对象编程中,必须在方法的声明中明确传入self(this),才能通过self访问到类的数据, 不妨看看以下代码.
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
复制代码
接下来,我们跟字节码走一遍,看看JVM是如何执行字节码的
iconst_1 将常量1推入操作数栈(push),执行完后操作数栈如下所示
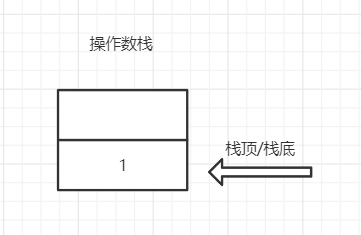
istore_1 将操作数栈顶的元素出栈,赋值给本地变量表的第一个Slot
即 本地变量表[1] = 操作数栈.pop()
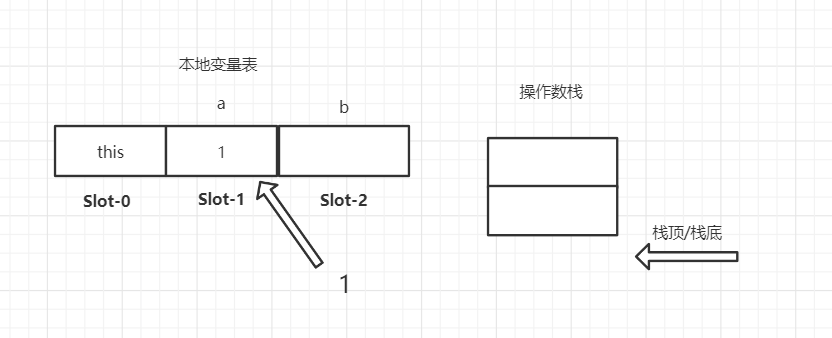
iload_1 将本地变表的第一个Slot值入栈,执行完后操作数栈如下所示
操作数栈.push(本地变量表[1])
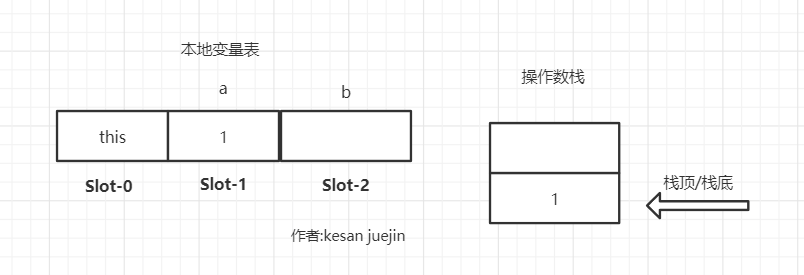
iconst_5 将常量值5推入操作数栈,执行完后操作数栈如下所示
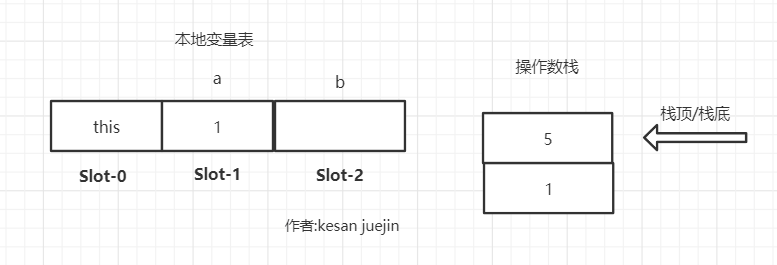
ishl 出栈两个元素执行左移位操作,将结果入栈即,执行完之后操作数栈如下所示
var1 = 操作数栈.pop(); var2 = 操作数栈.pop(); 操作数栈.push(var2 << var1); 复制代码
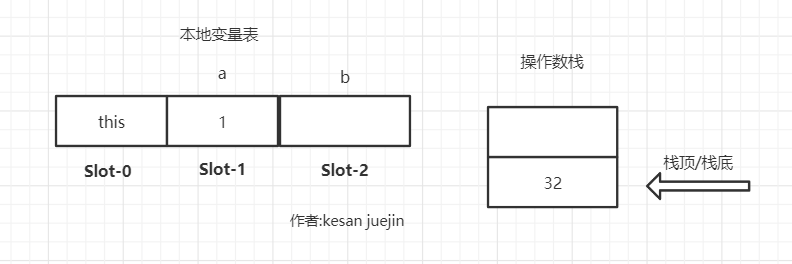
istore_2 将操作数栈顶的元素出栈,赋值给本地变量表的第二个Slot
即 本地变量表[1] = 操作数栈.pop()
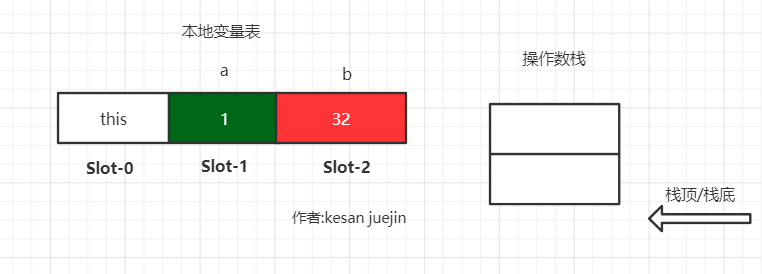
理解完操作数栈和本地变量表是如何互相搭配完成工作的之后,还有一个疑问没解决,从上面的分析可以看出本地变量表是以为Slot(槽位)作为基本分配单位的,那么问题来了本地变量表的一个Slot(槽位)占据多少空间呢?
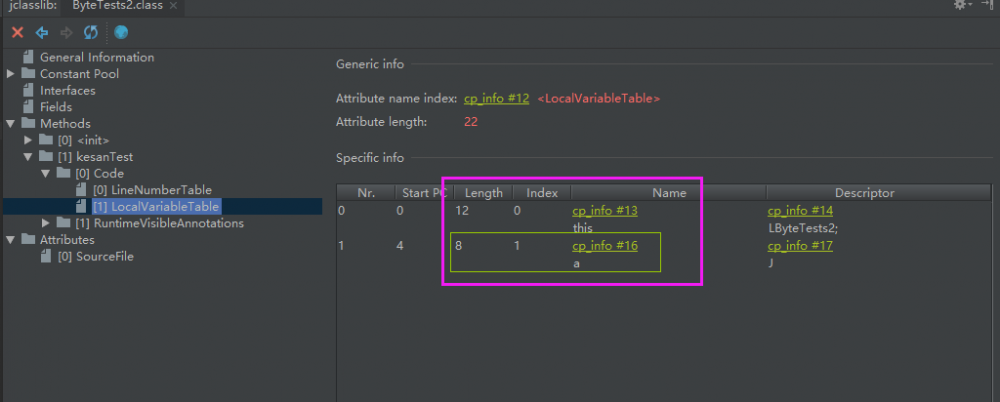
这一点虚拟机规范尚未明确,但一般来说是4字节,也就是32位,对于64位(8字节)的数据则需要连续分配两个槽位.
考虑如下代码
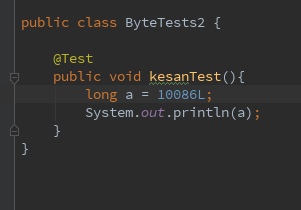
其本地变量表如下图所示
0x04 一点疑惑
就我而言,由于学习过汇编的原因,了解JVM字节码执行原理时,用标题党的话来说就是震惊,没想到还有这种操作,JVM竟然是基于栈的虚拟机执行引擎,其特点就是进行数据运算的时候要先把数据出栈,执行完之后再将结果入栈,甚反直觉.相反,寄存器的设计可以在寄存间直接进行数据运算,并将结果保存到寄存器.
但实际上性能并不低,本地变量表的设计和操作数栈都能很有效的利用CPU的高速缓存.
那有没有同汇编一样基于寄存器的执行引擎呢?
还真有,它经常作为内嵌的执行引擎引入到各大应用如Redis,Nginx,没错它就是Lua.
但了解不多,且与话题无关, 不谈.
0x05 最后
说来惭愧,自从不996之后,文章反而更新得少了,下半年一定多多分享.
公众号二维码,来聊天,当然不关注也无所谓,文章首发掘金,公众号作备份用

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

