HDFS-Hadoop 分布式文件系统
HDFS-Hadoop分布式文件系统
什么是分布式文件系统
数据量越来越多,已经超出了一个操作系统的管辖范围,需要分配到更多的操作系统管理的磁盘中,因此需要一种文件系统来管理多台机器上的文件,这就是分布式文件系统。分布式文件系统是一种允许文件通过网络在多台主机上共享的文件系统,可以让多台机器上的用户分享文件和存储空间。
HDFS概念
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的可用。
HDFS架构
NameNode和DataNode
NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。同是接收用户的请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间。
以上这些文件都是保存的Linux文件系统中。
DataNode提供真实数据的存储服务。文件块(block):最基本的存储单位,在Hadoop2中HDFS的默认大小是128M,不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
HDFS架构图如下:
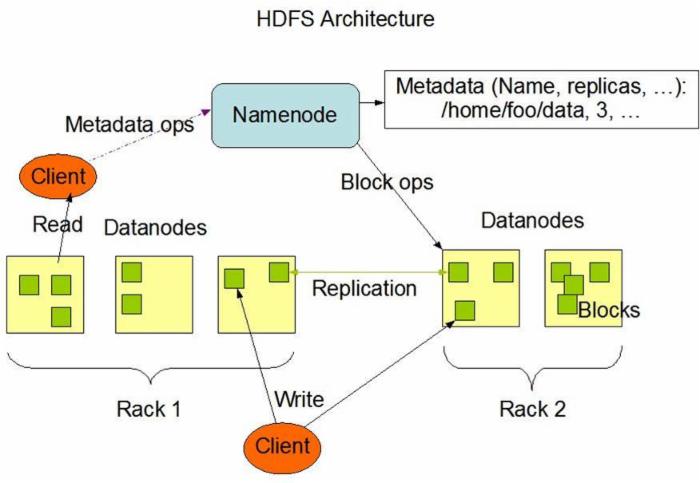
首先客户端(client)和namenode进行通讯,获取一些元数据信息,然后namenode查询相应的元数据信息返回给客户端(注意:元数据信息保存在内存和磁盘中各有一份,即安全又快速);
然后客户端开始读取数据,注意在读取时依次读取,不会同时读取(会采用数据就近原则);
同时namanode会给dataname一些信息,datanode会进行数据的水平复制。
元数据存储细节
元数据的存储格式如下:
NameNode(FileName,replicas,block-ids,id2host...)
举例:
/test/a.log,3,{blk_1,blk_2},[{blk_1:[h0,h1,h3]},{blk_2:[h0,h2,h4]}]
说明:
a.log存放了3个副本,文件被切分成了三块,分别是:blk_1,blk_2,第一块存放在h0,h1,h3三台机器上,第二块存放在h0,h2,h4上。
HDFS Shell常用命令
调用文件系统(FS)Shell命令应使用 bin/hadoop fs 的形式。
所有的FS shell命令使用URI路径作为参数。
URI格式是scheme://authority/path。HDFS的scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
将路径指定文件的内容输出到指定文件中;
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录;
hadoop fs -get /user/hadoop/file localfile
复制文件到本地文件系统;
hadoop fs -put localfile /user/hadoop/hadoopfile
从本地文件系统中复制单个或多个源路径到目标文件系统。
使用Java接口操作HDFS
新建Java项目之后要添加相应的jar,和HDFS相关的jar文件在/share/hadoop/common和/share/hadoop/common/lib和/share/hadoop/hdfs,如果使用maven不需要一个个导入。
由于Hadoop是由Java写的,通过Java API可以调用所有Hadoop文件系统的交互操作。FileSystem类来提供文件系统的操作。
使用FileSystem以标准输出来下载HDFS中的文件,代码如下:
FileSystem fs = FileSystem.get(new URI("hdfs://longlong01:9000"), new Configuration());//指定namenode
InputStream in = fs.open(new Path("/hellohdfs.txt"));//hdfs上的文件
FileOutputStream out = new FileOutputStream(new File("/root/myfile"));//打印到root下面的myfile
IOUtils.copyBytes(in, out, 4096, true);//将in中的内容复制到out中
读取本地文件上传到hdfs中,代码如下:
FSDataOutputStream out = fs.create(new Path(“/words.txt”));
FileInputStream in = new FileInputStream(new File("c:/w.txt"));//读取本地系统的文件
FSDataOutputStream out = fs.create(new Path("/words.txt"));
IOUtils.copyBytes(in, out, 2048, true);
```
如果上传不成功,显示没有权限,可以使用
```java
fs = FileSystem.get(new URI("hdfs://longlong01:9000"), new Configuration(),"root");
将当前用户伪装成root用户,可以解决没有权限的问题。
删除hdfs中的一个文件:
boolean flag = fs.delete(new Path("/hellohdfs.txt"), true);
在hdfs中新建一个文件:
boolean flag = fs.mkdirs(new Path("/root/hellohdfs"));
RPC-远程过程调用协议
RPC指的是Remote Procedure Call,远程过程调用协议,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
RPC采用客户机/服务器模式。请求程序就是一个客户机,服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端。进程保持休眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息。最后,客户端调用进程接受答复信息,获得进程结果,然后调用继续执行。
Hadoop整个体系结果就是构建在RPC之上的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

