Hadoop集群的配置(一)
1. 实验准备
1.1 目的:
在虚拟机环境下,让同学们学会从零开始配置Hadoop-2.2集群,并尝试在真实环境下搭建集群。
1.2 主要内容:
物理机器总共4台,想配置基于物理机的Hadoop集群中包括4个节点: 1 个 Master, 3个 Salve ,节点之间局域网连接,可以相互 ping通。IP的分布如表1所示。
表1 4个节点的IP地址分配及角

Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;3个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
用到的所有文件

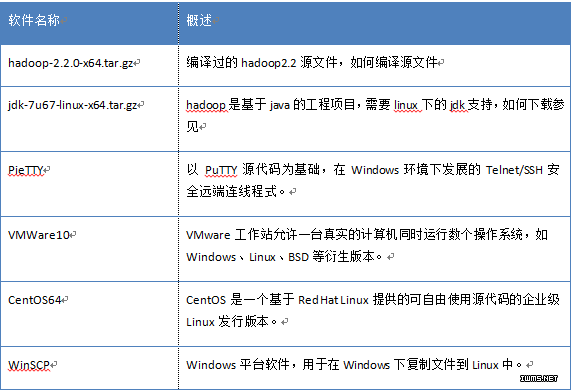
1.4 用户信息(所有节点一样)

2.搭建虚拟集群环境
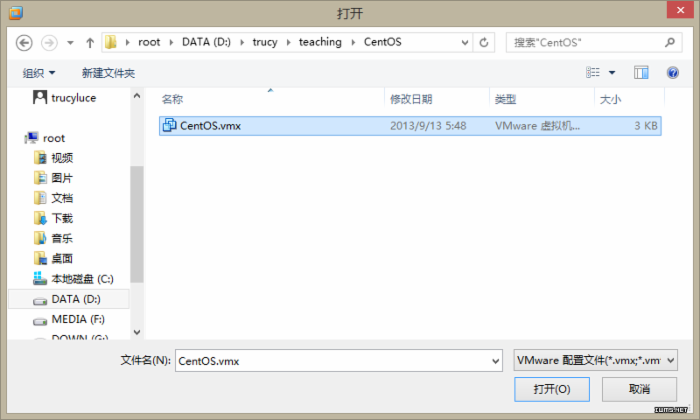
安装完VMWare10后,解压CentOS到指定文件夹下,打开VMWare10,点击菜单栏“文件”-->“打开”,选择CentOS文件,如图。
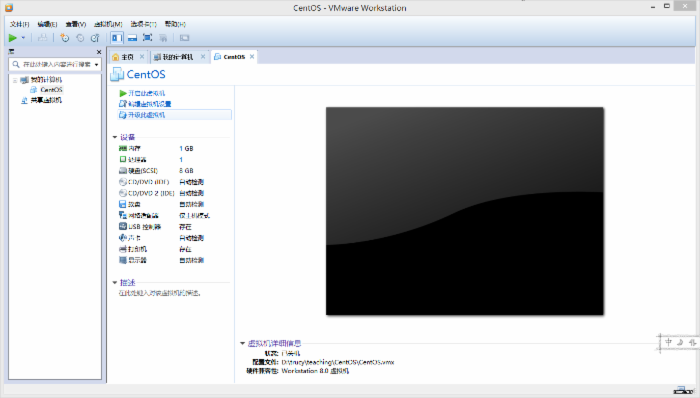
右击CentOS选择属性,弹出设置窗口。里面是虚拟系统的主要硬件参数信息,读者可以根据自己机器性能配置,这里选默认。
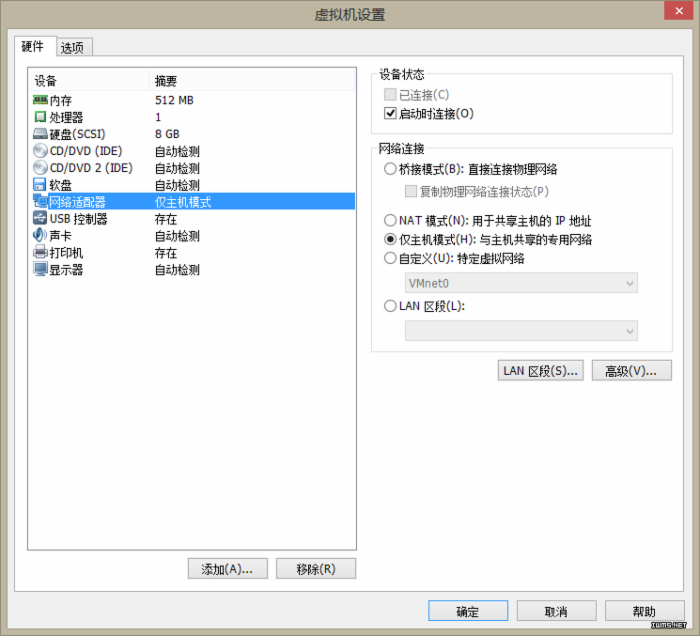
2.1三种连接方式
VMWare 提供了三种工作模式,它们是bridged(桥接模式)、NAT(网络地址转换模式)和host-only(主机模式)。要想在网络 管理和维护中合理应用它们,就应该先了解一下这三种工作模式。主机上安装VMware Workstation或VMware Server的时候,默认会安装3块虚拟网卡,这3块虚拟网卡的名称分别为VMnet0、VMnet1、VMnet8,其中VMnet0的网络属性为“物 理网卡”,VMnet1与VMnet8的网络属性为“虚拟网卡”。 在默认情况下, VMnet1 虚拟网卡的定义是“ 仅主机虚拟网络” ,VMnet8 虚拟网卡的定义是“NAT 网络” ,同时,主机物理网卡被定义为“ 桥接网络” ,主机物理网卡也可以称为VMnet0 。
大家在安装完虚拟机后,默认安装了两个虚拟网卡,VMnet1和 VMnet8。其中VMnet1是hostonly网卡,用于host方式连接网络的。VMnet8是NAT网卡,用 于NAT方式连接网络的。它们的IP地址默认是的,如果要用虚拟机做实验的话,最好将VMnet1到VMnet8的IP地址改掉。习惯上把 VMware虚拟网卡使用的网段“固定”,即设置为静态ip。使用如下原则: VMnet1 对应的网段是192.168.10.0 ,VMnet8 对应的网段是 192.168.80.0 。
1.bridged( 桥接模式 )
在这种模式下,VMWare虚拟出来的操作系统就像是局域网中的一台独立的主机,它可以访问网内任何一台机器。在桥接模式下,需要手工为虚拟系 统配置IP地址、子网掩码,而且还要和宿主机器处于同一网段,这样虚拟系统才能和宿主机器进行通信。同时,由于这个虚拟系统是局域网中的一个独立的主机系 统,那么就可以手工配置它的TCP/IP配置信息,以实现通过局域网的网关或路由器访问互联网。使用桥接模式的虚拟系统和宿主机器的关系,就像连接在同一 个Hub上的两台电脑。想让它们相互通讯,你就需要为虚拟系统配置IP地址和子网掩码,否则就无法通信。如果想利用VMWare在局域网内新建一个虚拟服 务器,为局域网用户提供网络服务,就应该选择桥接模式。使用这种方式很简单,前提是要得到1个以上的地址。对于想进行种种网络实验的朋友不太适合,因为无 法对虚拟机的网络进行控制,它直接就出去了。
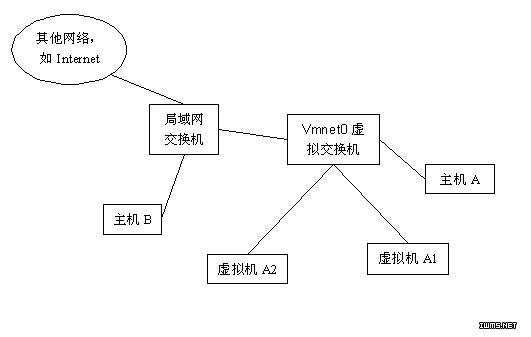
使用桥接方式,A,A1,A2,B可互访。
2.host-only( 仅主机模式 )
在某些特殊的网络调试环境中,要求将真实环境和虚拟环境隔离开,这时你就可采用host-only模式。在host-only模式中,所有的虚 拟系统是可以相互通信的,但虚拟系统和真实的网络是被隔离开的。提示:在host-only模式下,虚拟系统和宿主机器系统是可以相互通信的,相当于这两 台机器通过双绞线互连。在host-only模式下,虚拟系统的TCP/IP配置信息(如IP地址、网关地址、DNS服务器等),都可以由 VMnet1(host-only)虚拟网络的DHCP服务器来动态分配。如果想利用VMWare创建一个与网内其他机器相隔离的虚拟系统,进行某些特殊 的网络调试工作,可以选择host-only模式。

使用Host方式,A,A1,A2可以互访,但A1,A2不能访问B,也不能被B访问。
3.NAT( 网络地址转换模式 )
使用NAT模式,就是让虚拟系统借助NAT(网络地址转换)功能,通过宿主机器所在的网络来访问公网。也就是说,使用NAT模式可以实现在虚拟系统中安全的访问互联网。 NAT 模式下虚拟系统的TCP/IP 配置信息是由VMnet8 (NAT )虚拟网络的DHCP 服务器提供的,无法进行手工修改,因此虚拟系统也就无法和本局域网中的其他真实主机进行通讯。 采 用NAT模式最大的优势是虚拟系统接入互联网非常简单,你不需要进行任何其他的配置,只需要宿主机器能访问互联网即可。如果想利用VMWare安装一个新 的虚拟系统,在虚拟系统中不用进行任何手工配置就能直接访问互联网,建议采用NAT模式。提示:以上所提到的NAT模式下的VMnet8虚拟网 络,host-only模式下的VMnet1虚拟网络,以及bridged模式下的VMnet0虚拟网络,都是由VMWare虚拟机自动配置而生成的,不 需要用户自行设置。VMnet8和VMnet1提供DHCP服务,VMnet0虚拟网络则不提供。

使用NAT方式,A1,A2可以访问B,但B不可以访问A1,A2。但A,A1,A2可以互访。
全局网络拓扑图:

思考:真实部署要根据网络环境的不同而配置不同的连接方式,那么请思考,在6601机房搭建真实集群对应哪种连接方式?
2.2 host-only连接步骤
在学习VMWare虚拟网络时,我们建议选择host-only方式。第一,如果你的电脑是笔记本,从A移到B网络环境发生变化后,只有host-only方式不受影响,其他方式必须重新设置虚拟交换机配置。第二,将真实环境和虚拟环境隔离开,保证了虚拟环境的安全。
按绿色箭头启动虚拟机,角色选择other,输入root角色名,这里的密码是hadoop,具体密码由CentOS安装时设置,而我们使用的是安装好的。
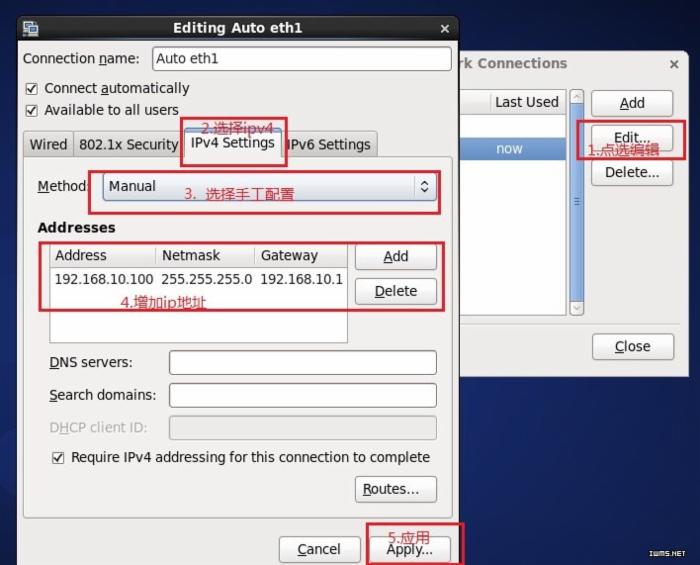
由于选择的是host-only连接方式,VMnet1必须打开,然后设置ipv4。
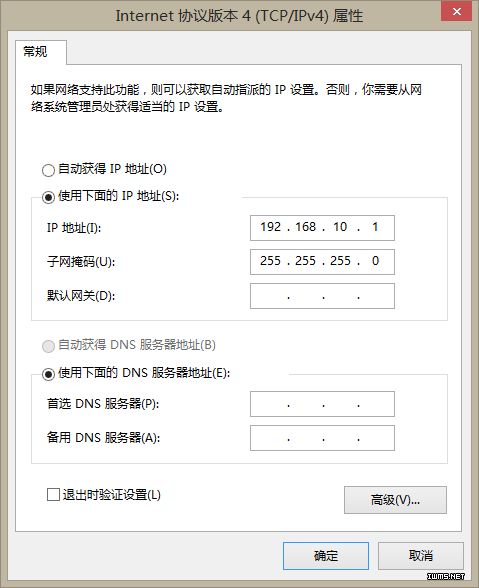
由于host-only方式不能连接外网,所以DNS不需配置,其他方式想要访问外网必须配置。
在Linux桌面环境中右击电脑图标,选中“EditConnection”进行如下配置:
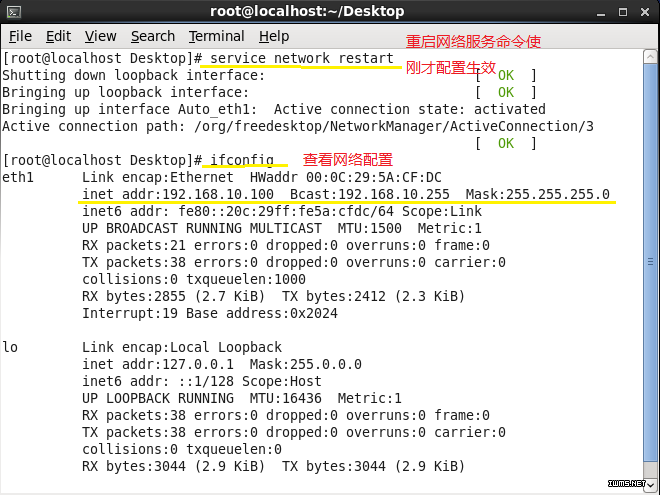
打开终端,查看配置情况。
检查与Windows主机的通信情况。
1.Windows-->Linux

2.Linux-->Winodws

思考:访问外部主机失败,分析为什么?
2.3 使用PieTTY连接Linux
填写连接目的的IP地址,端口是SSH模式的访问端口22,点击open,输入角色和密码登录。
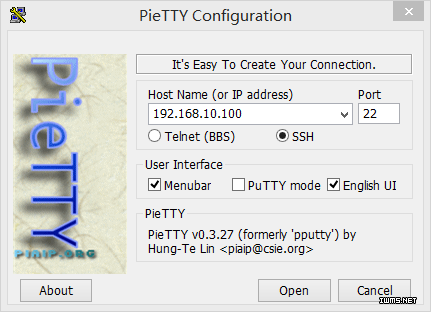
提示“潜在安全缺口”由于首次使用PieTTy登陆Linux [微软用户1] 虚拟机,PieTTY缓存里面并没有该Linux虚拟机的rsa2公钥信息,因此会提示是否信任次机器,我们选择是。
其他常用登录工具还有putty,XShell等,PieTTY相比之下操作简单功能丰富。
2.3 新建用户
使用root登陆后,创建Hadoop用户,在hadoopGroup组里。
1.创建hadoopGroup组
添加用户时,可以将用户添加到现有的用户组,或者创建一个新的用户组。可以在/etc/group文件中看到所有的用户组信息。默认的用户组通常用来管理系统用户,不建议将普通用户添加到这些用户组。使用groupadd命令创建用户组的语法为:
groupadd [-g gid [-o]] [-r] [-f] groupname
每个选项的含义如下:

如果不指定选项,系统将使用默认值。创建一个 hadoopGroup用户组:
$ groupadd hadoopGroup
2. 添加Hadoop用户
添加用户可以使用useradd命令,语法为:
useradd -d homedir -g groupname -m -s shell -u userid accountname
每个选项的含义如下:
 指定用户主目录/home/hadoop用户组hadoopGroup。
指定用户主目录/home/hadoop用户组hadoopGroup。

用户被创建后,可以使用passwd命令来设置密码,如:
$ passwd hadoop
Changing password for user hadoop.
New Linux password:******
Retype new UNIX password:******
passwd: all authentication tokens updated successfully.
2.4 安装jdkhadoop
1.使用winscp传输文件
在root用户下,执行命令rm -rf /usr/local/*
删除目录下所有内容(当前内容无用)使用winscp把jdk文件从windows复制到/usr/local目录下。点击新建一个会话。
输入用户和密码:


2.解压文件
解压命令tar -zvxf jdk-7u67-linux-x64.tar.gz到当前目录。

更改文件名为jdk1.7。

同样,解压命令tar -zvxf jdk-7u67-linux-x64.tar.gz到当前目录,并通过命令
mv hadoop-2.2.0 /home/hadoop/hadoop2.2 移动到Hadoop用户的主目录下。

3.目录规划
Hadoop程序存放目录为/home/hadoop/hadoop2.2,相关的数据目录,包括日志、存储等指定为/home/hadoop/hadoop2.2。将程序和数据目录分开,可以更加方便的进行配置的同步。
具体目录的准备与配置如下所示:
l 在每个节点上创建程序存储目录/home/hadoop/hadoop2.2,用来存放Hadoop程序文件。
l 在每个节点上创建数据存储目录/home/hadoop/hadoop2.2/hdfs,用来存放集群数据。
l 在主节点node上创建目录/home/hadoop/hadoop2.2/hdfs/name,用来存放文件系统元数据。
l 在每个从节点上创建目录/home/hadoop/hadoop2.2/hdfs/data,用来存放真正的数据。
l 所有节点上的日志目录为/home/hadoop/hadoop2.2/logs。
l 所有节点上的临时目录为/home/hadoop/hadoop2.2/tmp。
执行命令mkdir -p /home/hadoop/hadoop2.2/hdfs,为还没有的目录创建,后面以此类推。
给hadoopGroup组赋予权限,凡是属于hadoopGroup组的用户都有权利使用hadoop2.2,方便多用户操作。首先,把Hadoop2.2加入到hadoopGroup组:
chgrp -R hadoopGroup hadoop2.2
给这个组赋予权限:
chmod -R g=rwx hadoop2.2
4.导入JDK环境变量
执行cd /etc命令后执行vi profile,在行末尾添加:
export JAVA_HOME=/usr/local/jdk1.7
export CLASSPATH=.: J A V A H O M E / l i b / t o o l s . j a r : JAVA_HOME/lib/dt.jar
export PATH=.: J A V A H O M E / b i n : PATH
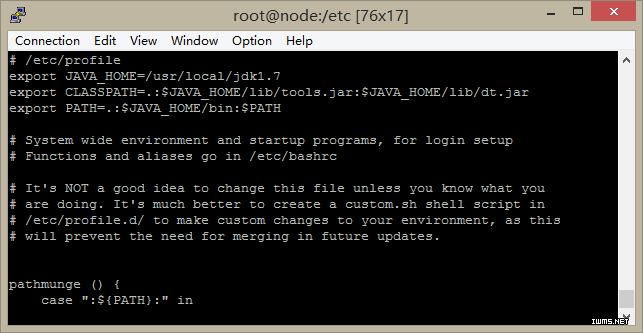 执行source profile,使其配置立即生效。
执行source profile,使其配置立即生效。
执行java –version查看是否安装成功。

5.导入Hadoop环境变量
同上面一样,修改profile。
export HADOOP_HOME=/home/hadoop/hadoop2.2
export PATH=.: H A D O O P H O M E / s b i n : HADOOP_HOME/bin: J A V A H O M E / b i n : PATH
export HADOOP_LOG_DIR=/home/hadoop/hadoop2.2/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
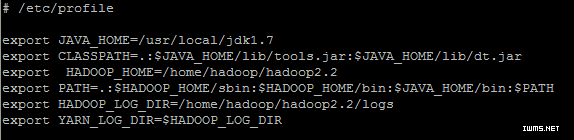
执行hadoop命令,查看有没有成功。
2.5.修改主机名
1.修改当前会话中的主机名,执行命令hostname node。
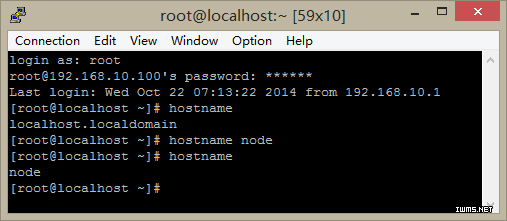
但是这种配置只对当前状态有效,一旦重新启动虚拟机,主机名未变。
2.修改配置文件中的主机名,执行命令vi /etc/sysconfig/network。
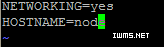
重启生效,由于第一步已经在当前会话中配置了hostname,所以不用重启。
3.绑定hostname与IP
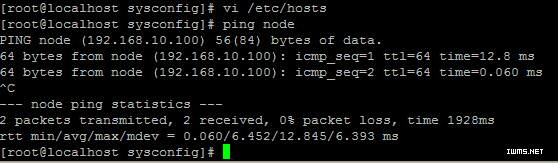
执行vi/etc/hosts,增加内容如下:
192.168.10.100 node
192.168.10.101 node1
192.168.10.102 node2
192.168.10.103 node3
Ping node,检验是否修改成功?
2.6 关闭防火墙
如果不关闭防火墙,有以下几种情况出现:
第一:hdfs的Web理页面,打不开该节点的文件浏览页面。
第二:后台运行脚本(HIVE的),会出现莫名其妙的假死状态。
第三:在删除和增加节点的时候,会让数据迁移处理时间更长,甚至不能正常完成相关操作。
第四:不管你做任何作,都是会运行不正常,而且很不顺手。
执行命令service iptables stop
验证: service iptables status

执行上面操作可以关闭防火墙,但重启后还会继续运行,所以还要关闭防火墙的自动运行。
执行命令 chkconfig iptables off
验证: chkconfig --list |grep iptables

2.7 修改hadoop2.2配置文件
Hadoop没有使用java.util.Properties管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是使用了一套独有的配置文件管理系统,并提供自己的API,即使 org.apache.hadoop.conf.Configuration处理配置信息,大家也可以通过eclipse工具分析下源码,并利用这些 api修改配置文件。
由于Hadoop集群中每个机器上面的配置基本相同,所以先在namenode上面进行配置部署,然后再复制到其他节点。
1. 配置 ~/hadoop2.2/etc/hadoop 下的hadoop-env.sh 、yarn-env.sh 、mapred-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/local/jdk1.7/)

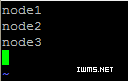
2. 配置 ~/hadoop2.2/etc/hadoop/slaves (这个文件里面保存所有slave节点)
3. 配置 ~/hadoop-2.2.0/etc/hadoop/core-site.xml
+ View Code
http://hadoop.apache.org/docs/r2.2.0/hadoop-project-dist/hadoop-common/core-default.xml
4. 配置 ~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
+ View Code
http://hadoop.apacheorg/docs/r2.2.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
5. 配置 ~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
+ View Code
http://hadoop.apache.org/docs/r2.2.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
6. 配置 ~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
+ View Code
http://hadoop.apache.org/docs/r2.2.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
未完待续.......
下节:Hadoop集群的配置(二)
尾注:本系列文档,笔者真机环境测试无误得以分享,纯属原创,若有转载,请注释出处.
http://www.cnblogs.com/baiboy
正文到此结束
- 本文标签: ip cat 安全 管理 操作系统 apache unix shell 互联网 apr 微软 参数 update Hadoop VMware grep centos 数据 list ssh 源码 eclipse tar Datanode 调试 XML java classpath node Namenode UI TCP 目录 测试 端口 DNS HDFS 配置 注释 linux 服务器 windows iptables Slaves 安装 时间 Connection root tab 网卡 集群 map API 同步 web
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

