Presto 来自Facebook的开源分布式查询引擎
PrestoDB 来自Facebook的开源分布式查询引擎
Presto是一个分布式SQL查询引擎, 它被设计为用来专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。下图中展现了简化的Presto系统架构。客户端(client)将SQL查询发送到Presto的协调员(coordinator)。协调员会进行语法检查、分析和规划查询计划。计划员(scheduler)将执行的管道组合在一起, 将任务分配给那些里数据最近的节点,然后监控执行过程。 客户端从输出段中将数据取出,这些数据是从更底层的处理段中依次取出的。

Presto的运行模型和Hive或MapReduce有着本质的区别。Hive将查询翻译成多阶段的MapReduce任务, 一个接着一个地运行。每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然而Presto引擎没有使用MapReduce。它使用了一个定制的查询和执行引擎和响应的操作符来支持SQL的语法。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的时候就会将数据从一个处理段传入到下一个处理段。这样的方式会大大的减少各种查询的端到端响应时间。
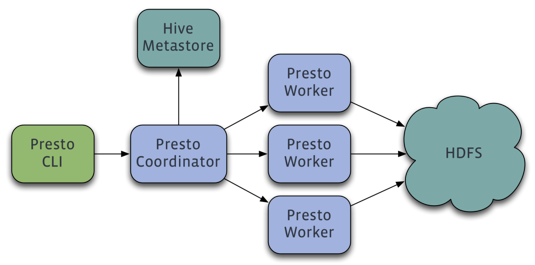
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
Presto特点:
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- 类BlinkDB的近似查询
- GC控制
扩展性是在设计Presto时的另一个要点。在项目的早期阶段, Facebook就意识到出了HDFS之外,大量数据会被存储在很多其他类型的系统中。 其中一些是像HBase一类的为人熟知的系统,另一类则是象Facebook New Feed一样的定制的后台。Presto设计了一个简单的数据存储的抽象层, 来满足在不同数据存储系统之上都可以使用SQL进行查询。存储插件(连接器,connector)只需要提供实现以下操作的接口,包括对元数据(metadata)的提取,获得数据存储的位置,获取数据本身的操作等。除了我们主要使用的Hive/HDFS后台系统之外, Facebook也开发了一些连接其他系统的Presto 连接器,包括HBase,Scribe和定制开发的系统。作为Hive和Pig(Hive和Pig都是通过MapReduce的管道流来完成HDFS数据的查询)的替代者,Presto不仅可以访问HDFS,也可以操作不同的数据源,包括:RDBMS和其他的数据源(例如:Cassandra)。目前已经被支持的RDBMS有:MySQL、SQLServer、PostgreSQL等
WebUI
1、AirPal(推荐)
AirPal是AirBnb开源的查询Presto的WebUI。 项目特性:
- 可选的用户访问控制
- SQL语法高亮
- 查询结果导出到CSV文件,或者存到Hive表中
- 可查看SQL查询的历史记录
- 可保存查询
- 根据表名搜索对应的表
- 可查看表结构,并预览前1000行数据
项目地址 https://github.com/airbnb/airpal
2、Shib
Shib是Treasure Data员工TAGOMORI开源的查询Hive、Presto、BigQuery的WebUI。
项目地址 https://github.com/tagomoris/shib
3、Hue
Hue本身是不支持查询Presto的,但是可以通过以下的方法使其支持查询Presto: https://medium.com/@ilkkaturunen/integrating-presto-with-hue-61702b244839
4、yanagishima
这是一个奇怪的英文名字,因为是一个日本人起的,来自东京的软件工程师wyukawa。项目特性:
- 安装简单(无需安装RDBMS)
- 易用,与MySQL Workbench类似
- 使用本地存储记录独立的查询历史
- 可以为查询添加标签
- 可以查看历史查询列表
- 可以Kill正在运行的查询
- 可以格式化查询语句
- 可查看表信息(列、分区)
- 查询结果保存为TSV文件
项目地址 https://github.com/wyukawa/yanagishima
其他参考链接:
- Presto 官网: http://prestodb.io/
- Presto Github 主页: https://github.com/facebook/presto
- 京东修改版(推荐): https://github.com/CHINA-JD/presto
- Presto 文档: http://prestodb-china.com/docs/current/
转载请注明: 标点符 » Presto 来自Facebook的开源分布式查询引擎
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

