Airbnb欺诈预测机器学习模型设计:准确率和召回率的故事
【编者按】 Airbnb 网站 基于允许 任何人将闲置的房屋进行长期或短期出租构建商业模式 , 来自房客或房东的欺诈风险是必须解决的问题。 Airbnb 信任和安全小组通过构建机器学习模型进行欺诈预测,本文介绍了其设计思想。假想模型是 预测某些虚拟人物是否为“反面人物”,基本步骤:构建模型预期,构建训练集和测试集,特征学习,模型性能评估。其中特征转换倾向于采用条件概率编码(CP-coding),评估度量是准确率(Precision)和召回率(Recall),通常偏向于高召回率。
以下为全文内容:
在Airbnb网站上,我们专注于创造一个这样的地方:一个人可以属于任何地方。部分归属感来自于我们用户之间的信任,同时认识到他们的安全是我们最关心的。
虽然我们绝大多数的社区是由友好和可靠的房东和房客组成,但仍然有一小部分用户,他们试图从我们的网站中(非法)获利。这些都是非常罕见的,尽管如此,信任和安全小组还是因此而产生。
信任和安全小组主要是解决任何可能会发生在我们平台的欺诈行为。我们最主要目的是试图保护我们的用户和公司免于不同类型的风险。例如:退款风险——一个绝大多数电子商务企业都熟悉的风险问题。为了减少此类欺诈行为,信任和安全小组的数据科学家构建了不同种类的机器学习模型,用来帮助识别不同类型的风险。想要获得我们模型背后更多的体系结构信息,请参考以前的文章 机器学习风险系统的设计 。
在这篇文章中,我对机器学习的模型建立给了一个简短的思维过程概述。当然,每个模型都有所不同,但希望它能够给读者在关于机器学习中我们如何使用数据来帮助保护我们的用户以及如何改善模型的不同处理方法上带来一个全新的认识。在这篇文章中,我们假设想要构建一个这样的模型:预测某些虚构的角色是否是反面人物。
试图预测的是什么?
在模型建立中最基本的问题就是明确你想要用这个模型来预测什么。我知道这个听起来似乎很愚蠢,但很多时候,通过这个问题可以引发出其它更深层的问题。
即使是一个看似简单的角色分类模型,随着我们逐步深入地思考,也可以提出许多更深层的问题。例如,我们想要怎样来给这个模型评分:仅仅是给当前新介绍的角色还是给所有角色?如果是前者,我们想要评分的角色和人物介绍中的角色评分相差多远?如果是后者,我们又该多长时间给这些角色评分呢?
第一个想法可能是根据人物介绍中给每个角色的评分来建立模型。然而,这种模型,我们可能不能随着时间的推移动态地追踪人物的评分。此外,我们可能会因为在介绍时的一些“好”的特征而忽略了潜在的反面人物。
相反,我们还可以建立这样一个模型,只要他/她出现在情节里面就评分一次。这将让我们在每个时间段都会有人物评分并检测出任何异常情况。但是,考虑到在每个角色单独出现的情况下可能没有任何的角色类别发展,所以这可能也不是最实际的方法。
深思熟虑之后,我们决定把模型设计成介于这两种想法之间的模型。例如,建立这样一种模型,在每次有意义的事情发生的时候对角色进行评分,比如结交新盟友,龙族领地占领等等。在这种方式下,我们仍然可以随着时间的变化来跟踪人物的评分,同时,对没有最新进展的角色也不会多加评分。

如何模拟得分?
因为我们的目的是分析每个时期的得分,所以我们的训练集要能反映出某段时间某个角色的类别行为,最后的训练数据集类似于下图:
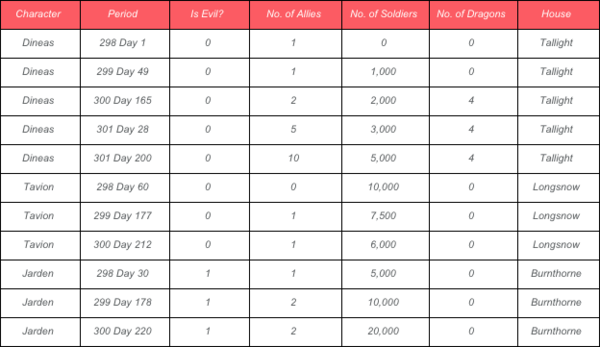
与每个角色相关的时间不一定是连续的,因为我们关心的是那些有着重要事件发展的时间。
在这个实例当中,Jarden在3个不同的场合有着重要的角色发展并且在一段时间内持续扩充他的军队。相比之下,Dineas 在5个不同的场合有着重要的角色发展并且主管着4个龙族中心基地。
采样
在机器学习模型中,从观测数据中下采样是有必要的。采样过程本身很简单,一旦有了所需要的训练数据集,就可以在数据集上做一个基于行的采样。
然而,由于这里描述的模型是处理每个角色多个时期的样本,基于行采样可能会导致这样一种情况,即在建立模型的数据和用来验证的数据之间,场景附加的人物角色被分离开。如下表所示:

显然这并不是理想的采样,因为我们没有得到每个角色的整体描述,并且这些缺失的观测数据可能对建立一个好的模型至关重要。
出于这个原因,我们需要做 基于角色的采样 。这样做能确保在模型数据建立中包含所有场合附加的角色,或者什么都没有。

此外,当我们将我们的数据集切分为训练集和测试集时,通常这样的逻辑也适用。
特征设计
特征设计是机器学习不可或缺的一部分,通常情况下,在特征种类的选择上,对数据的充分理解有助于形成一个更好的模型设计思路。特征设计的实例包括特征规范化和分类特征处理。
特征规范化是标准化特征的一种方式,允许更合理的对比。如下表所示:

从上表可知,每个人物都有10,000个士兵。然而,Serion掌权长达5年,而Dineas仅仅掌权2年。通过这些人物比较绝对的士兵数量可能并不是非常有效的。但是,通过人物掌权的年份来标准化他们可能会提供更好的见解,并且产生更有预测力的特征。
在分类特征的特征设计上值得单独的写一篇博客文章,因为有很多方式可以去处理它们。特别是对于缺失值的插补,请看一看以前的博客文章—— 使用随机森林分类器处理缺失值 。
转换分类特征最常见的方法就是矢量化(也称作one-hot encoding)。然而,在处理有许多不同级别的分类特征时,使用条件概率编码(CP-coding)则更为实用。
CP-coding的基本思想就是在给定的分类级别上,计算出某个特征值发生的概率。这种方法使得我们能够将所有级别的分类特征转化为一个单一的数值型变量。

然而,这种类型转换可能会因为没有充分描述的类别而造成噪音数据。在上面的例子中,我们只有一个来自House 为 “Tallight”的观测样本。结果相应的概率就是0或1。 为了避免这种问题的发生并且降低噪声数据,通常情况下,可以通过考虑加权平均值,全局概率或者引入一个平滑的超系数来调整如何计算概率 。
那么,哪一种方法最好呢?这取决于分类特征的数量和级别。 CP-coding是个不错的选择,因为他降低了特征的维数,但是这样会牺牲掉特征与特征之间的互信息,这种方法称之为矢量化保留 。此外,我们可以整合这两种方法,即组合相似的类别特征,然后使用CP-coding处理整合的特征。
模型性能评估
当谈及到评估模型性能的时候,我们需要留意正面角色和反面角色的比例。在我们的例子模型中,数据最后的统计格式为[character*period](下表左)。 然而,模型评估应该以角色类别测量(下表右)。

结果,在模型的构建数据和模型的评估数据之间的正面人物和反面人物的比例有着明显的差异。 当评估模型准确率和召回率的时候分配合适的权重值是相当重要的 。
此外,因为我们可能会使用下采样以减少观测样本的数量,所以我们还需要调整模型占采样过程的准确率和召回率。
评估准确率和召回率
对于模型评估的两种主要的评估度量是准确率(Precision)和召回率(Recall)。在我们的例子当中,准确率是预测结果为反面角色中被正确预测为反面角色的比例。它在给定的阈值下衡量模型的准确度。另外,召回率是模型从原本为反面角色当中能够正确检测出为反面角色的比例。它在一个给定的阈值下以识别反面人物来衡量模型的综合指标。这两个变量很容易混淆,所以通过下表会更加的直观看出两者的不同。

通常将最后的数据划分为四个不同的部分:
- True Positives(TP):角色是反面人物,模型预测为反面人物;
- False Positives(FP):角色是正面人物,模型预测为反面人物;
- True Negatives(TN):角色是正面人物,模型预测为正面人物;
- False Negatives(FN):角色是反面人物,模型预测为正面人物;
准确率计算:在所有被预测为反面人物中,模型正确预测的比例,即TP /(TP + FP)。
召回率计算:在所有原本就是反面人物中,模型正确预测的比例,即TP / (TP + FN)。
通过观察可以看出,尽管准确率和召回率的分子是相同的,但分母不同。
通常在选择高准确率和高召回率之间总有一种权衡。这要取决于构建模型的最终目的,对于某些情况而言,高准确率的选择可能会优于高召回率。然而, 对于欺诈预测模型,通常要偏向于高召回率,即使会牺牲掉一些准确率 。
有许多的方式可以用来改善模型的准确度和召回率。其中包括添加更好的特征,优化决策树剪枝或者建立一个更大的森林等等。不过,鉴于讨论广泛,我打算将其单独地放在一篇文章当中。
结束语
希望这篇文章能让读者了解到什么是构建机器学习模型所需要的。遗憾的是, 没有放之四海而皆准的解决方案来构建一种好的模型,充分了解数据的上下文是关键,因为通过它我们能够从中提取出更多更好的预测特征,从而建立出更优化的模型 。
最后,虽然将角色分为正面和反面是主观的,但 类别标签的确是机器学习的一个非常重要的部分,而不好的类别标签通常会导致一个糟糕的模型 。祝建模快乐!
注: 这个模型确保每个角色都是正面角色或者是反面角色,即如果他们生来就是反面角色,那么在他们的整个生命当中都是反面角色。如果我们假设角色可以跨越类别标签作为中立人物,那么模型的设计将会完全不同。
英文原文: Designing Machine Learning Models: A Tale of Precision and Recall (译者/刘帝伟 审校/刘翔宇、朱正贵 责编/周建丁)
关于译者: 刘帝伟,中南大学软件学院在读研究生,关注机器学习、数据挖掘及生物信息领域。
【预告】 首届中国人工智能大会(CCAI 2015) 将于7月26-27日在北京友谊宾馆召开。机器学习与模式识别、大数据的机遇与挑战、人工智能与认知科学、智能机器人四个主题专家云集。人工智能产品库将同步上线,预约咨询:QQ:1192936057。欢迎关注。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

