使用Neo4j进行全栈Web开发
在开发一个全栈web应用时,作为整个栈的底层,你可以在多种数据库之间进行选择。作为事实的数据源,你当然希望选择一种可靠的数据库,但同时也希望它能够允许你以良好的方式进行数据建模。在本文中,我将为你介绍 Neo4j ,当你的数据模型包含大量关联数据以及关系时,它可以成为你的web应用栈的基础的一个良好选择。
Neo4j是什么?
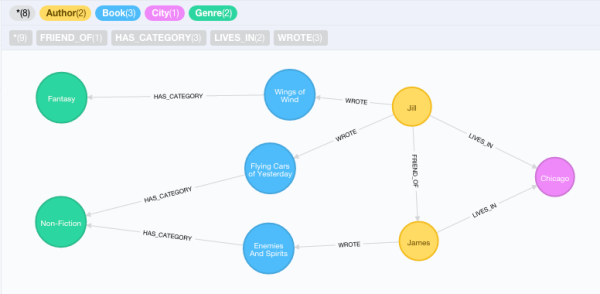
图 1. Neo4j Web 控制台
Neo4j是一个图形数据库,这也就意味着它的数据并非保存在表或集合中,而是保存为节点以及节点之间的关系。在Neo4j中,节点以及关系都能够包含保存值的属性,此外:
- 可以为节点设置零或多个 标签 (例如Author或Book)
- 每个关系都对应一种 类型 (例如WROTE或FRIEND_OF)
- 关系总是从一个节点指向另一个节点(但可以在不考虑指向性的情况下进行查询)
为什么要选择Neo4j?
在考虑为web应用选择某个数据库时,我们需要考虑对它有哪些方面的期望,其中最重要的一些条件包括:
- 它是否易于使用?
- 它是否允许你方便地回应对需求的变更?
- 它是否支持高性能查询?
- 是否能够方便地对其进行数据建模?
- 它是否支持事务?
- 它是否支持大规模应用?
- 它是否足够有趣(很遗憾的是对于数据库的这方面要求经常被忽略)?
从这几个方面来说,Neo4j是一个合适的选择。Neo4j……
- 自带一套易于学习的查询语言(名为 Cypher )
- 不使用schema,因此可以满足你的任何形式的需求
- 与关系型数据库相比,对于高度关联的数据(图形数据)的查询快速要快上许多
- 它的实体与关系结构非常自然地切合人类的直观感受
- 支持兼容ACID的事务操作
- 提供了一个高可用性模型,以支持大规模数据量的查询,支持备份、数据局部性以及冗余
- 提供了一个可视化的查询控制台,你不会对它感到厌倦的
什么时候不应使用Neo4j?
作为一个图形NoSQL数据库,Neo4j提供了大量的功能,但没有什么解决方案是完美的。在以下这些用例中,Neo4j就不是非常适合的选择:
- 记录大量基于事件的数据(例如日志条目或传感器数据)
- 对大规模分布式数据进行处理,类似于Hadoop
- 二进制数据存储
- 适合于保存在关系型数据库中的结构化数据
在上面的示例中,你看到了由Author、City、Book和Category以及它们之间的关系所组成的一个图形。如果你希望通过Cypher语句在Neo4j web控制台中列出这些数据结果,可以执行以下语句:
MATCH (city:City)<-[:LIVES_IN]-(:Author)-[:WROTE]-> (book:Book)-[:HAS_CATEGORY]->(category:Category) WHERE city.name = “Chicago” RETURN *
请注意这种ASCII风格的语法,它在括号内表示节点名称,并用箭头表示一个节点指向另一个节点的关系。Cypher通过这种方式允许你匹配某个指定的子图形模式。
当然,Neo4j的功能不仅仅在于展示漂亮的图片。如果你希望按照作者所处的地点(城市)计算书籍的分类数目,你可以通过使用相同的 MATCH 模式,返回一组不同的列,例如:
MATCH (city:City)<-[:LIVES_IN]-(:Author)-[:WROTE]-> (book:Book)-[:HAS_CATEGORY]->(category:Category) RETURN city.name, category.name, COUNT(book)
执行这条语句将返回以下结果:
| city.name | category.name | COUNT(category) |
| Chicago | Fantasy | 1 |
| Chicago | Non-Fiction | 2 |
虽然Neo4j也能够处理“大数据”,但它毕竟不是Hadoop、HBase或Cassandra,通常来说不会在Neo4j数据库中直接处理海量数据(以PB为单位)的分析。但如果你乐于提供关于某个实体及其相邻数据关系(比如你可以提供一个web页面或某个API返回其结果),那么它是一种良好的选择。无论是简单的CRUD访问,或是复杂的、深度嵌套的资源视图都能够胜任。
你应该选择哪种技术栈以配合Neo4j?
所有主流的编程语言都通过HTTP API的方式支持Neo4j,或者采用基本的HTTP类库,或是通过某些原生的类库提供更高层的抽象。此外,由于Neo4j是以Java语言编写的,因此所有包含JVM接口的语言都能够充分利用Neo4j中的高性能API。
Neo4j本身也提供了一个“技术栈”,它允许你选择不同的访问方式,包括简单访问乃至原生性能等等。它提供的特性包括:
- 通过一个HTTP API执行Cypher查询,并获取JSON格式的结果
- 一种“非托管扩展”机制,允许你为Neo4j数据库编写自己的终结点
- 通过一个高层Java API指定节点与关系的遍历
- 通过一个低层的批量加载API处理海量初始数据的获取
- 通过一个核心Java API直接访问节点与关系,以获得最大的性能
一个应用程序示例
最近我正好有机会将一个项目扩展为基于Neo4j的应用程序。该应用程序(可以访问 graphgist.neo4j.com 查看)是关于GraphGist的一个门户网站。GraphGist是一种通过交互式地渲染(在你的浏览器中)生成的文档,它基于一个简单的文本文件(AsciiDoctor),其中用文字描述以及图片描述了整个数据模型、架构以及用例查询,可以在线执行它们,并使它们保持可视化。它非常类似一个 iPython notebook或是一张交互式的白纸。GraphGist也允许读者在浏览器中编写自己定义的查询,以查看整个数据集。
Neo4j的原作者Neo Technology希望为GraphGist提供一个由社区创建的展示项目。当然,后端技术选用了Neo4j,而整个技术栈的其余部分,我的选择是:
- Node.js 配合 Express.js ,其中引入了neo4j包
- Angular.js
- Swagger UI
所有代码都已开源,可以在 GitHub 上任意浏览。
从概念上讲,GraphGist门户网站是一个简单的应用,它提供了一个GraphGist列表,允许用户查看每个GraphGist的详细内容。数据领域是由Gist、Keyword/Domain/Use Case(作为Gist分类)以及Person(作为Gist的作者)所组成的:

现在你已经熟悉这个模型了,在继续深入学习之前,我想为你快速地介绍一下Cypher这门查询语言。举例来说,如果我们需要返回所有的Gist和它们的关键字,可以通过以下语句实现:
MATCH (gist:Gist)-[:HAS_KEYWORD]->(keyword:Keyword) RETURN gist.title, keyword.name
这段语句将返回一张表,其中的每一行是由每个Gist和Keyword的组合构成的,正如同SQL join的行为一样。现在我们更深入一步,假设我们想要找到某个人所编写的Gist对应的所有Domain,我们可以执行下面这条查询语句:
MATCH (person:Person)-[:WRITER_OF]->(gist:Gist)-[:HAS_DOMAIN]->(domain:Domain) WHERE person.name = “John Doe” RETURN domain.name, COUNT(gist)
该语句将返回另一个结果表,其中的每一行包含Domain的名称,以及这个Person对于这一Domain所编写的全部Gist的数量。这里无需使用 GROUP BY 语句,因为当我们使用例如COUNT()这样的聚合函数时,Neo4j会自动在 RETURN 语句中对其它列进行分组操作。
现在你对Cypher已经有一点感觉了吧?那么让我们来看一个来自实际应用中的查询。在创建这个门户时,如果能够通过某种方式,只需对数据库进行一次请求就能够返回我们所需的所有数据,并且以一种我们需要的格式进行结构组织,那将十分有用。
让我们开始创建这个用于门户的API(可以在 GitHub 上找到)的查询吧。首先,我们需要按照Gist的title属性进行匹配,并匹配所有相关的Gist节点:
// Match Gists based on title MATCH (gist:Gist) WHERE gist.title =~ {search_query} // Optionally match Gists with the same keyword // and pass on these related Gists with the // most common keywords first OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(related_gist) 这里有几个要注意的地方。首先, WHERE 语句是通过一个正则表达式(即=~操作符)和一个参数对title属性进行匹配的。参数(Parameter)是Neo4j的一项特性,它能够将查询与其所代表的数据进行分离。使用参数能够让Neo4j对查询和查询计划进行缓存,这也意味着你无需担心遭遇查询注入攻击。其次,我们在这里使用了一个 OPTIONAL MATCH 语句,它表示我们希望始终返回原始的Gist,即使它并没有相关的Gist。
现在让我们对之前的查询进行扩展,将 RETURN 语句替换为 WITH 语句:
MATCH (gist:Gist) WHERE gist.title =~ {search_query} OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(related_gist) WITH gist, related_gist, COUNT(DISTINCT keyword.name) AS keyword_count ORDER BY keyword_count DESC RETURN gist, COLLECT(DISTINCT {related: { id: related_gist.id, title: related_gist.title, poster_image: related_gist.poster_image, url: related_gist.url }, weight: keyword_count }) AS related 在 RETURN 语句中的COLLECT()作用是将由Gist和相关Gist所组成的节点转换为一个结果集,让其中每一行Gist只出现一次,并对应一个相关Gist的节点数组。在COLLECT()语句中,我们在相关Gist中仅指定了所需的部分数据,以减小整个响应的大小。
最后,我们将产生这样一条查询语句,这也是最后一次使用 WITH 语句了:
MATCH (gist:Gist) WHERE gist.title =~ {search_query} OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(related_gist) WITH gist, related_gist, COUNT(DISTINCT keyword.name) AS keyword_count ORDER BY keyword_count DESC WITH gist, COLLECT(DISTINCT {related: { id: related_gist.id, title: related_gist.title, poster_image: related_gist.poster_image, url: related_gist.url }, weight: keyword_count }) AS related // Optionally match domains, use cases, writers, and keywords for each Gist OPTIONAL MATCH (gist)-[:HAS_DOMAIN]->(domain:Domain) OPTIONAL MATCH (gist)-[:HAS_USECASE]->(usecase:UseCase) OPTIONAL MATCH (gist)<-[:WRITER_OF]-(writer:Person) OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword:Keyword) // Return one Gist per row with arrays of domains, use cases, writers, and keywords RETURN gist, related, COLLECT(DISTINCT domain.name) AS domains, COLLECT(DISTINCT usecase.name) AS usecases, COLLECT(DISTINCT keyword.name) AS keywords COLLECT(DISTINCT writer.name) AS writers, ORDER BY gist.title 在这个查询中,我们将选择性地匹配所有相关的Domain、Use Case、Keyword和Person节点,并且将它们全部收集起来,与我们对相关Gist的处理方式相同。现在我们的结果不再是平坦的、反正规化的,而是包含一列Gist,其中每个Gist都对应着相关Gist的数组,形成了一种“has many”的关系,并且没有任何重复数据。太酷了!
不仅如此,如果你觉得用表的形式返回数据太老土,那么Cypher也可以返回对象:
RETURN { gist: gist, domains: collect(DISTINCT domain.name) AS domains, usecases: collect(DISTINCT usecase.name) AS usecases, writers: collect(DISTINCT writer.name) AS writers, keywords: collect(DISTINCT keyword.name) AS keywords, related_gists: related } ORDER BY gist.title 通常来说,在稍具规模的web应用程序中,需要进行大量的数据库调用以返回HTTP响应所需的数据。虽然你可以并行地执行查询,但通常来说你需要首先返回某个查询的结果集,才能发送另一个数据库请求以获取相关的数据。在SQL中,你可以通过生成复杂的、开销很大的表join语句,通过一个查询从多张表中返回结果。但只要你在同一个查询中进行了多次SQL join,这个查询的复杂性将会飞快地增长。更不用说数据库仍然需要进行表或索引扫描才能够获得相应的数据了。而在Neo4j中,通过关系获取实体的方式是直接使用对应于相关节点的指针,因此服务器可以随意进行遍历。
尽管如此,这种方式也存在着诸多缺陷。虽然这种方式能够通过一个查询返回所有数据,但这个查询会相当长。我至今也没有找到一种方式能够对进行模块化以便重用。进一步考虑:我们可以在其它场合同样调用这个终结点,但让它显示相关Gist的更多信息。我们可以选择修改这个查询以返回更多的数据,但也意味着对于原始的用例来说,它返回了额外的不必要数据。
我们是幸运的,因为有这么多优秀的数据库可以选择。虽然关系型数据库对于保存结构化数据来说依然是最佳的选择,但NoSQL数据库更适合于管理半结构化数据、非结构化数据以及图形数据。如果你的数据模型中包括大量的关联数据,并且希望使用一种直观的、有趣的并且快速的数据库进行开发,那么你就应当尝试一下Neo4j。
本文由Brian Underwood撰写,而Michael Hunger也为本文作出了许多贡献。
关于作者
 Brian Underwood 是一位软件工程师,喜爱任何与数据相关的东西。作为一名 Neo4j 的Developer Advocate,以及 neo4j ruby gem 的维护者,Brian经常通过一些演讲,以及在他的博客上的文章宣传图形数据库的强大与简洁。Brian如今正与他的妻儿在全球旅行。可以在 Twitter 上找到Brian,或在 LinkedIn 上联系他。
Brian Underwood 是一位软件工程师,喜爱任何与数据相关的东西。作为一名 Neo4j 的Developer Advocate,以及 neo4j ruby gem 的维护者,Brian经常通过一些演讲,以及在他的博客上的文章宣传图形数据库的强大与简洁。Brian如今正与他的妻儿在全球旅行。可以在 Twitter 上找到Brian,或在 LinkedIn 上联系他。
查看英文原文: Full Stack Web Development Using Neo4j
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

