刀尖上的乾坤大挪移 :RapidsDB技术大起底
大数据和互联网时代,正冲击每一个行业,技术的日新月异,令人目不暇接,但是从整个行业来看,基于Hadoop的批量大数据处理方式,以及基于内存数据库和内存计算的实时处理和分析,已经慢慢成熟,并且成为了事实上的标准。随着内存闪存造价的不断下降和技术的不断成熟,基于MPP海量并行技术的内存数据仓库,不再是遥不可及的传说,并成为了我们身边触手可及的应用。使用标准的PC服务器,我们就能够在企业中随意搭建这么一套内存MPP的数据仓库,并结合业务对身边的大数据作出实时的决策。
本篇文章来自柏睿数据CTO刘睿民先生,作为国产软件在高端基础技术上吃螃蟹的人,刘睿民将会介绍柏睿数据公司出品的重要产品— MPP内存数据仓库Rapids DB的重要特性,以及实现过程中的一些技术细节。
RapidsDB 进入关键应用系统
早在2014年,公司成立尚短,产品尚在研发阶段的时候,作为国产的一款内存数据库,RapidsDB就已经引起了国内主要运营商和一些对数据查询处理速度有高要求的企业的关注,并提出了试用申请。
2014年12月,随着RapidsDB V1.0版本推出,作为一款海量数据高速处理引擎,RapidsDB正式进入联通实际项目,作为客户用户搜索的一个重要数据处理平台投入使用,紧密耦合了当下的Hadoop技术,每日为上亿级别的数据提供处理支持。这意味着RapidsDB已经有能力满足海量数据的处理要求,同时也能够支持复杂、高可靠的企业级应用。
RapidsDB 组件
RapidsDB产品设计之初就是一个完全并行的,基于分布式内存的分析型数据仓库。理论上来说,它是可以运行在一系列不同的新一代存储介质之上,使用最接近人类思维的SQL语句来操纵及查询分布在并行节点上的千亿级别数据。
RapidsDB的一个简单的示意如图1所示,用户只需要专注于SQL语句的编写,复杂的分布式内存处理及查询优化,则交由系统底层来自动处理。

图1 RapidsDB示意
存储在各个节点内存中的分布式数据,被统一地管理和访问,用户将查询语句提交给RapidsDB的分布式查询引擎DQS,DQS(Distributed Query System)又由DQC和DQE几个组件来共同组成。
以下我对组成RapidsDB的几个部件进行一个简要的说明。
数据存储(Data Store)
The Data Store是一种分布式内存数据存储系统,我们往往把需要查询的数据存储在节点对应的内存当中,Data Store由Storage Engine进行管理。并且通过DQS的接口进行查询和简单的事务处理。
分布式查询系统(DQS)
分布式查询系统为用户提供了查询内存数据的SQL接口。用户不需要知道知道数据存储在哪一个节点当中,DQS保存了数据存储相关的元数据,通过解析用户的查询语句,DQS能够直接和存储的数据进行交互。
DQS连接器
DQS支持与底层存储的引擎接口插件技术,也可以叫做DQS连接器。连接器被部署在每一个节点的存储引擎当中,利用本地存储引擎的能力,将用户查询语句直接在该节点进行处理。在未来,连接器还将提供相应的SDK,允许第三方开发的连接器访问他们自己选择的存储引擎。
分布式查询协调器(Distributed Query Coordinator)
DQC接收用户提交的指令并进行处理。用户可以通过命令行界面(CLI)提交查询,或通过RapidsDB的编程API提交查询。DQC将解析查询语句,然后建立一个并行查询计划,同时将该查询计划交给分布在每一个节点的执行者(DQEs)执行。DQC将吸收所有DQEs的结果,其中可能包括额外的处理如聚集或排序,然后将结果返回给调用者。
分布式查询执行器Distributed Query Executor (DQE)
分布式查询执行器(DQE)负责响应在每一个Data Store中的数据子集。通常在每个有存储引擎实例运行的节点中,都会有一个DQE系统。DQE负责执行查询计划,DQE将使用相关DQS连接器在查询计划与相关的存储引擎进行通信。并且返回查询结果给用户。
配置管理(Configuration Management)
RapidsDB使用ZooKeeper作为集群配置管理工具。
RapidsDB 功能介绍
RapidsDB虽然主要的诉求是一款面向分析的分布式内存数据仓库,其实它本身具有OLTP和OLAP双引擎,能够满足简单的事务处理和ACID操作,同时又有最大可能性能满足时下大数据所面临的超大规模数据库跨节点的大表关联应用,并且在提供实用功能的同时,可以通过实时添加节点数及内存大小,来实现性能的横向扩展。
数据分布方式
整体而言,RapidsDB使用Shared Nothing结构:整个数据库的数据分散到集群的多台机器上。RapidsDB的数据分布策略是基于哈希的,存储在RapidsDB中的每一张表,对数据的主键哈希取模后的结果,对应于数据存储的节点。相较于BigTable基于主键的连续范围分段的方法,哈希方法的好处是数据分散均匀,没有动态数据调整的烦恼。但也有很多缺点,采用这种方法后,集群的规模是事先确定好的。另外,数据哈希被分散后,数据的连续性被打乱了,在这个数据结构上做范围查询需要动用服务这张表的所有机器。
数据事务处理
为了充分发挥多核机器的性能,而又不引入多线程执行事务的复杂性,Rapids DB的数据分片规模是按照集群核数来划分的。一台物理机器上可能运行多个Rapids DB服务器进程,每个进程对应于一个核,服务器进程之间都是通过网络进行通信。在单个进程内,只使用单线程,所有的事务执行都按顺序进行。
多个事务在多个服务器节点同时执行,Rapids DB保证如果事务之间有冲突,那么事务的执行是完全隔离的,即达到SERIALIZABLE ISOLATION。Rapids DB会事先分析好存储过程之间的关系,如果两个事务可能存在冲突,则不让这两个进程在同一个时间执行。
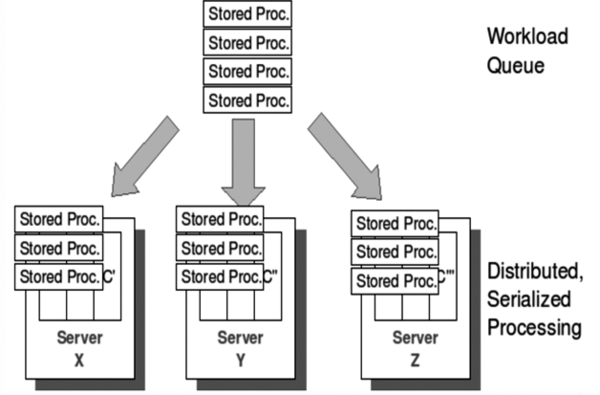
图2 Rapids DB并发处理
在Rapids DB的并发处理中,每一个事务在执行之前都要等待一个Round Trip时间,显然会增加事务执行的时延。这么做是为了确保别的节点没有发起比这个事务更早的事务,保证事务执行的顺序。在实现中,Rapids DB用了另外一种优化方法。例如A,B两个节点,分别要执行事务1和2,A节点开始执行事务1的时间是T1,如果A收到B发了事务2的执行需求,并且T2 > T1,那么A节点可以确认从B节点不会有更早的事务再发送过来,A节点就不必等Round Trip时间,可以直接执行事务1。当整个系统压力比较大时,这个优化方法效果尤其明显,事务的时延有效降低。
Rapids DB还花了很大精力在处理事务之间的逻辑关系,尽可能对事务分门别类进行处理,以期获得更好的性能。
数据安全保障
和传统数据库提供的HA解决方案不同,Rapids DB提供三种HA能力:K-safety,网络故障检测,存活结点重连(rejoin)。
K-safety(通过数据多副本方式实现数据安全)
当配置成K-safety时,Rapids DB会自动地复制数据库分区,K表示副本的个数。例如K=0时表示没有副本,所以任何一个结点的故障,都会导致整个数据库集群停止服务。当K=1时表示有1个副本,即一共2份拷贝。RapidsDB中的副本是可以读写的,而不是传统的主从复制关系。
关于数据同步问题的解决,任何发生在复制分区上的操作,都会发送给各个拷贝的结点去执行,来保证一致性。如果其中一个结点失败,那么数据库会继续发送这个操作给失败的结点。因此在这一点上Rapids DB与传统数据库有很大不同,不存在多主(multi-master)情况下的数据同步冲突问题。所以K-safety也叫做同步多主复制。
网络故障检测
当网络发生故障时,Rapids DB的结点彼此之间被物理隔离开,而认为对方已经发生故障。那么K-safety机制会使这两侧的结点继续分别提供服务。如果不及时检测到的话,这种“分离的大脑”(split brain)会导致严重的数据同步问题。因此,Rapids DB会自动检测网络故障,立即评估出哪一侧结点应该继续服务,并快照另一侧的结点数据后停掉服务。网络故障解决时,可以直接使用下面将介绍到的存活结点重连技术将结点重新加入到集群中。
存活结点重连
万一出现了离线的节点,离线了的RapidsDB结点可以通过rejoin操作重新加入到集群中。具体过程是:首先从兄弟结点获得一份数据拷贝,当追赶上兄弟结点时,此存活结点就可以回到正常状态,继续接受任务了。
数据编程接口
Rapids DB提供了主流编程语言的相应接口,可以通过客户端连接后编程,对数据库进行操作,复杂查询使用CLI方式访问。Rapids DB编程当中的事务操作,从需求来看,既需要支持复杂的事务操作,又需要快速的执行过程。由于RapidsDB主要聚焦的是分析性的复杂查询,因此对事务的控制方面,所有事务均采用自动提交,不支持手动提交事务。不允许用户使用传统的OLTP中“Begin Transaction”和“End Transaction”的语法模式,而是完全基于Java编写的存储过程。用户通过写Java存储过程完成应用程序的逻辑,作为一个先置条件将Java存储过程提交到RapidsDB。运行时,用户程序调用存储过程完成事务操作,所有事务的运行逻辑是由RapidsDB在服务器进程中完成的。这保证了事务不会被人为打断,并且服务器可以预先判断各个事务的逻辑,提高并发效率。
系统横向比较
横向比较而言,许多人会首先想到Oracle的内存数据库TimesTen。最明显的区别就是,TT不是个MPP的架构,无法横向扩展;而RapidsDB强调的不仅仅是内存中存储数据,还更加强调内存中可以执行复杂计算及复杂查询。虽然TT支持数据复制功能,但是RapidsDB是一个真正的MPP Cluster,一个表可以被Hash到每一个节点上,CPU并行计算,以此来提高硬件利用率,而TT则只是单纯通过数据复制来提高性能。
 作者: 刘睿民
作者: 刘睿民
简介: 柏睿数据科技有限公司董事长兼CTO、艾诺威讯(北京)科技有限公司首席执行官、联想中国服务总部首席技术顾问、国家信标委ISO SC32国际专家国家信标委ISO WG10 IoT物联网国际协调员。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

