倒排索引压缩:改进的PForDelta算法
由于倒排索引文件往往占用巨大的磁盘空间,我们自然想到对数据进行压缩。同时,引进压缩算法后,使得磁盘占用减少,操作系统在query processing过程中磁盘读取效率也能提升。另外,压缩算法不仅要考虑压缩效果,还要照顾到query processing过程的解压缩效率。
总的来说,好的索引压缩算法需要最大化两个方面:
1、减少磁盘资源占用
2、加快用户查询响应速度
其中,加快响应速度比减少磁盘占用更为重要。本文主要介绍PForDelta压缩算法,其简单易懂,能够提供可观的数据压缩,同时具备非常高的响应速度,因此广泛的运用于很多实际信息检索系统中。文章主要包含以下几个部分:
1、待压缩的倒排索引数据
2、PForDelta算法
3、改进的PForDelta算法
4、索引压缩步骤
5、索引解压步骤
待压缩的倒排索引数据
一个posting单元由<DocID、TF、Term position…>组成。对于每个DocID,其保存在硬盘中的大小取决于文件集最大文档编号的大小。这样造成编号较小的DocID分配了和编号较大的DocID(上百万)一样的存储空间,浪费了资源。由于每个posting是根据DocID顺序存储,所以不需要保存DocID,只需要保存前后两个DocID的差值,这样可以大大减小DocID储存空间,这种方式成为Delta Encoding。如下图:
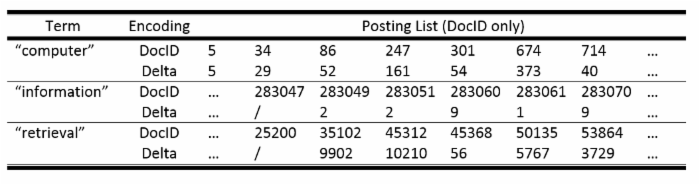
对于tf值,根据 Zipf定律 ,tf值较小的term占大多数,我们可以对这类tf值少分配一些空间保存。而tf大的term占少数,对这些tf分配多空间储存。基于上述排列特性,往往将docID和tf及其他数据分开放置,方便数据压缩。最终,整体的存储结构如下图所示:

为了方便分布式存储倒排索引文件,Data Block是硬盘中的基础存储单元。由于建立过程需要,每个term 的postinglist被拆分为多个部分保存在多个block中(如图不同颜色的block代表存储不同term的postinglist)。也就是说,每个block内部可能包含多个term的postinglist片段。
Data block的基本组成单元是数据块(chunk),每个chunk一般包含固定数量的posting,图中所示一个chunk包含128个posting,这些posting都属于同一个term。其中将DocID、tf和position分开排放,方便压缩。
这样以block为单元,以chunk为基础元素的索引存储的方式,一方面可以支持使用caching的方法缓存最常用term的postinglist,提高query响应速度。另一方面,所有压缩解压缩过程都以chunk为单位,都在chunk内部进行。当需要查找某一term的postinglist时,不需要对所有文件进行解压缩。对于不相关的chunk直接忽略,只需要对少部分block中的目标chunk进行处理,这样又从另一个方面大大缩短了query响应时间。这也是chunk机制设置的初衷。接下来,我们讨论如何对一个chunk结构进行压缩和解压缩处理。
PForDelta算法
PForDelta算法最早由Heman在2005年提出(Heman et al ICDE 2006),它允许同时对整个chunk数据(例128个数)进行压缩处理。基础思想是对于一个chunk的数列(例128个),认为其中占多数的x%数据(例90%)占用较小空间,而剩余的少数1-x%(例10%)才是导致数字存储空间过大的异常值。因此,对x%的小数据统一使用较少的b个bit存储,剩下的1-x%数据单独存储。
举个例子,假设我们有一串数列23, 41, 8, 12, 30, 68, 18, 45, 21, 9, ..。取b = 5,即认为5个bit(32)能存储数列中大部分数字,剩下的超过32的数字单独处理。从可见的队列中,超过32的数字有41, 68, 45。那么PForDelta压缩后的数据如下图所示(图中将超过32的数字称为异常值exception):

图中第一个单元(5bit)记录第一个异常值的位置,其值为“1”表示间隔1个b-bit之后是第一个异常值。第一个异常值出现在“23”之后,是“41”,其储存的位置在队列的最末端,而其在128个5bit数字中的值“3”表示间隔3个b-bit之后,是下一个异常值,即“68”,之后依次类推。异常值用32bit记录,在队列末尾从后向前排列。
上述队列就对应一个chunk(DocID),还需要另外记录b的取值和一个chunk压缩后的长度。这样就完整的对一个chunk数据进行了压缩。
但是这样算法有一个明显的不足:如果两个异常值的间隔非常大(例如超过32),我们需要加入更多的空间来记录间隔,并且还需要更多的参数来记录多出多少空间。为了避免这样的问题,出现了改进的算法NewPFD。
改进的PForDelta算法
在PForDelta算法基础上, H. Yan et.al WWW2009 提出NewPFD算法及 OptPFD算法。
NewPFD算法
由于PForDelta算法最大的问题是如果异常值间隔太大会造成b-bit放不下。NewPFD的思路是:128个数最多需要7个bit就能保存,如果能将第二部分中保存异常值的32bit进行压缩,省出7bit的空间用于保存这个异常值的位置,问题就迎刃而解了。同时更自然想到,如果异常值位置信息保存在队列后方的32bit中,那么队列第一部分原用于记录异常值间隔的对应部分空间就空余出来了,可以利用这部分做进一步改进。
因此,NewPFD的算法是,假设128个数中,取b=5bit,即32作为阈值。数列中低于32的数字正常存放,数列中大于32的数字,例如41 (101001) 将其低5位(b-bit)放在第一部分,将其剩下的高位(overflow)存放在队列末端。我们依然以PForDelta中的例子作为说明,一个128位数列23, 41, 8, 12, 30, 68, 18, 45, 21, 9, ..。经过NewPFD算法压缩后的形式如下图所示:
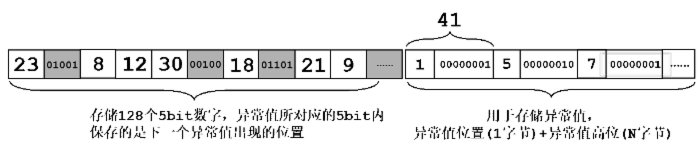
NewPFD算法压缩后的数据依然包括两部分,第一部分128个b-bit数列,省去了第一个异常值位置单元;第二部分异常值部分包含异常值的位置和异常值的高位数字。例如,对于异常值“41”其2进制码为101001,那么低5位01001保存在数据块第一部分。在第二部分中,先保存位置信息(“41”的位置是“1”,表示原数列第2个),再以字节为单位保存高位“1”即“0000 0001”,这样反而只需要附加2个字节(一个保存位置,一个保存高位)就可以储存原本需要4个字节保存的异常值。而对于高位字节,还可以继续使用压缩算法进行压缩,本文不再继续讨论。
除了数据列,NewPFD算法还需要另外保存b值和高位占的字节数(称为a值)。因为参数ab已经确定了数据块的长度,因此chunk长度值不用再单独记录。
OptPFD算法
OptPFD算法在NewPFD之上,认为每个数据压缩单元chunk应该有适应自己数据的独立a值和b值,这样虽然需要保存大量的ab值,但是毕竟数据量小不会影响太大的速度,相反,由于对不同chunk单独压缩,使压缩效果更好,反而提高了解压缩的效果。
对于b的选取,通常选择2^b可以覆盖数列中90%的数字,也就是控制异常值在10%左右,这样可以获得压缩效果和解压缩效率的最大化。
索引压缩步骤
了解了压缩算法原理,下面我们来看倒排索引文件具体如何压缩。我们采用OptPFD算法,先定义数据结构和参数:
1、定义一次压缩64个数字;每次选择其中的90%数字作为正常数字,剩余10%作为异常值;
2、建立一个结构体PForBlock,保存压缩后的数据,内部包含数据和压缩参数a、b;
3、定义一个PForDelta算法对象,主要包括两个成员函数GetAB和compress,分别表示计算压缩参数ab值以及实施具体压缩算法。其中数组bsets_[9],记录可取的b值,为了方便计算参数b。为了数据对齐,删除了一些b的取值。
4、以4字节为一个单元存放压缩数据,为了解压缩时代码更简洁高效。例如64个待压缩数字经计算后取b = 3,则4个字节32bit一共能存放10个压缩后的数字,剩余32-3*10 = 2bit高位留空。(实际编码中可任意选择编程方案)
1 #define COMPRESS_BLOCK_SIZE 64 2 #define PFOR_THRESHOLD 0.9 3 4 struct PForBlock { 5 unsigned a,b; 6 vector<unsigned> data; 7 }; 8 9 class PForCompressor { 10 public: 11 PForCompressor() { 12 bsets_[0]=1;bsets_[1]=2;bsets_[2]=3;bsets_[3]=4;bsets_[4]=5;bsets_[5]=6; 13 bsets_[6]=8;bsets_[7]=10;bsets_[8]=16; 14 } 15 PForBlock compress(const vector<unsigned> &v); 16 17 protected: 18 void getAB(const vector<unsigned> &v); 19 unsigned bsets_[9]; 20 unsigned a_, b_; 21 };
其中,getAB()和compress()函数具体代码如下:
1 void PForCompressor::getAB(const vector<unsigned> &v) { 2 vector<unsigned> u = v; 3 sort(u.begin(), u.end()); 4 unsigned threshold = u[((unsigned)(double)u.size()*PFOR_THRESHOLD - 1)]; 5 unsigned max_num = u[u.size() - 1]; 6 // Get b 7 unsigned bn = 0; 8 for (; bn < 8; ++bn) { 9 if ((threshold >> bsets_[bn]) <= 0) 10 break; 11 } 12 b_ = bsets_[bn]; 13 // Get a 14 max_num >>= b_; 15 a_ = 1; 16 for (; a_ < 4; ++a_) { 17 if ((1 << (a_ * 8)) > max_num) 18 break; 19 } 20 }
1 PForBlock PForCompressor::compress(const vector<unsigned> &v) { 2 getAB(v); 3 unsigned threshold = 1 << b_; 4 vector<unsigned> tail; 5 vector<unsigned>::iterator it; 6 PForBlock block; 7 block.a = a_; 8 block.b = b_; 9 10 //90% fit numbers and the low b-bit of exceptions are stored at the head 11 unsigned head_size = (v.size() + 32 / b_ + 1) / (32 / b_); 12 for(unsigned i = 0; i < head_size; ++i) 13 block.data.push_back(0); 14 for(unsigned i = 0; i < v.size(); ++i) { 15 unsigned low = v[i] & (threshold - 1); 16 block.data[i / (32 / b_)] |= low << i % (32 / b_) * b_; 17 if(v[i] >= threshold) { 18 tail.push_back(i); 19 unsigned high = v[i] >> b_; 20 for(unsigned l = 0; l < a_; ++l) { 21 tail.push_back((high >> (l * 8)) & 255); 22 } 23 } 24 } 25 26 // high-bit of exceptions are stored at the end using a-bytes each. 27 unsigned temp = 0; 28 unsigned i; 29 for(i = 0; i < tail.size(); ++i) { 30 temp |= tail[i] << (i * 8 % 32); 31 if(i % 4 == 3) { 32 block.data.push_back(temp); 33 temp = 0; 34 } 35 } 36 if(i % 4 != 0) 37 block.data.push_back(temp); 38 39 return block; 40 }
索引解压步骤
1、解压前已经知道压缩数据的参数a和b(由程序或配置文件另外保存),先对压缩数据的第一部分解压,以压缩64个数字为例,则将64个b-bit从压缩数据中第一部分提取出来;
2、之后再对第二部分解压,由于已经知道异常值在数列中的索引位置(1字节)和异常值的高位bit(a字节),将异常值的高位比特加入其第一部分的低位比特中,就完成了解压过程。
3、由于压缩算法按照4字节为一个单元进行存储压缩数据,而不同的参数b值对应不同的存放方案,因此最高效的解压缩编程是每种压缩方案单独编写一个解压缩程序。
先来看解压缩对象定义
1 class PForDecompressor { 2 public: 3 PForDecompressor(); 4 void Decompress(unsigned a,unsigned b,unsigned item_num,unsigned *data,unsigned data_length,unsigned* res); 5 6 private: 7 typedef void(PForDecompressor::*step1Funs)(); 8 typedef void(PForDecompressor::*step2Funs)(unsigned); 9 step1Funs step1_[17]; 10 step2Funs step2_[5]; 11 12 unsigned item_num_; 13 unsigned data_length_; 14 unsigned* data_; 15 unsigned* res_; 16 17 void step3(); 18 void step1B1(); 19 void step1B2(); 20 void step1B3(); 21 void step1B4(); 22 void step1B5(); 23 void step1B6(); 24 void step1B8(); 25 void step1B10(); 26 void step1B16(); 27 void step1Ex(); 28 29 void step2A1(unsigned b); 30 void step2A2(unsigned b); 31 void step2A3(unsigned b); 32 void step2A4(unsigned b); 33 };
1、压缩时设定参数b的取值可以是1、2、3、4、5、6、8、10、16,解压时分别对应step1Bx()函数。这个9个函数以函数指针的形式,以b的数值作为索引,保存在一个具有17个元素的数组里。为了方便检测b的合法性,非法的b取值也设置在了数组中,由step1Ex表示。当step1Ex被调用时,会返回一个异常。
2、压缩时参数a的取值可能是1~4,解压时分别对应step2Ax(),解压第二部分时,需要用到参数b,因此将其作为函数入参。和解压第一部分一样,也将这4个函数以函数指针的形式保存在数组里,方便读取。
所以,根据算法初始化的要求,自然可以得出类构造函数定义:

1 PForDecompressor::PForDecompressor() { 2 step1_[0]=&PForDecompressor::step1Ex; 3 step1_[1]=&PForDecompressor::step1B1; 4 step1_[2]=&PForDecompressor::step1B2; 5 step1_[3]=&PForDecompressor::step1B3; 6 step1_[4]=&PForDecompressor::step1B4; 7 step1_[5]=&PForDecompressor::step1B5; 8 step1_[6]=&PForDecompressor::step1B6; 9 step1_[7]=&PForDecompressor::step1Ex; 10 step1_[8]=&PForDecompressor::step1B8; 11 step1_[9]=&PForDecompressor::step1Ex; 12 step1_[10]=&PForDecompressor::step1B10; 13 step1_[11]=&PForDecompressor::step1Ex; 14 step1_[12]=&PForDecompressor::step1Ex; 15 step1_[13]=&PForDecompressor::step1Ex; 16 step1_[14]=&PForDecompressor::step1Ex; 17 step1_[15]=&PForDecompressor::step1Ex; 18 step1_[16]=&PForDecompressor::step1B16; 19 step2_[1]=&PForDecompressor::step2A1; 20 step2_[2]=&PForDecompressor::step2A2; 21 step2_[3]=&PForDecompressor::step2A3; 22 step2_[4]=&PForDecompressor::step2A4; 23 }View Code
获得压缩数据后,正式开始解压缩,调用Decompress成员函数:
1 void PForDecompressor::Decompress(unsigned a,unsigned b,unsigned item_num,unsigned *data,unsigned data_length,unsigned* res) { 2 item_num_ = item_num; 3 data_length_ = data_length; 4 data_ = data; 5 res_= res; 6 (this->*step1_[b])(); 7 (this->*step2_[a])(b); 8 }
由于已经写好解压第一部分和解压第二部分的函数,因此Decompress函数代码非常简单,只需要将b和a作为索引值分别传入数组中,调用对应的函数进行第一部分和第二部分的解压。
我们以b = 3 和 a = 1为例,简单看解压步骤,其他参数类似。
以b=3解压缩第一部分:
1 void PForDecompressor::step1B3() 2 { 3 unsigned l = (item_num_ + 9) / 10; 4 unsigned i, block; 5 unsigned *con = res_; 6 for(i = 0; i < l; ++i) 7 { 8 block = *(data_++); 9 data_length_--; 10 con[0] = block & 7; 11 con[1] = (block>>3) & 7; 12 con[2] = (block>>6) & 7; 13 con[3] = (block>>9) & 7; 14 con[4] = (block>>12) & 7; 15 con[5] = (block>>15) & 7; 16 con[6] = (block>>18) & 7; 17 con[7] = (block>>21) & 7; 18 con[8] = (block>>24) & 7; 19 con[9] = (block>>27) & 7; 20 con += 10; 21 } 22 }
第一部分数据,包含原始数据的正常值和异常数据的低b-bit值,它们都以b-bit存放,共64个。
当b=3时,也就是4个字节32bit可以存放10个b-bit。
因此程序中,data_表示原始待解压缩的数据流,l表示压缩数据第一部分的长度,res_/con 是4字节为单位的数组,用来存放解压缩后的数据,block每次取出data_的4个字节来完成解压缩过程;
1、因为32个bit存放10个数据,可以容易计算出l值,注意防止除法向下取整造成结果错误;
2、每次取出4字节数据放在block中;
3、从低位到高位,依次取出block中的bit,每次3个,将其存放入res_中;
第一部分解压缩完毕,来看a = 1时的第二部分:
1 void PForDecompressor::step2A1(unsigned b) 2 { 3 unsigned block; 4 while(data_length_ > 0) 5 { 6 block = *(data_++); 7 data_length_--; 8 res_[block & 255] += ((block >> 8) & 255) << b; 9 res_[(block >> 16) & 255] += ((block >> 24)) << b; 10 } 11 }
由于当a = 1时,一个异常值占2个字节(一个字节索引,一个字节存放高位bit),那么一个4字节单元可以存放2个异常值。
1、解压缩的过程非常简单,每次取出原始数据流的4个字节,其中包含两个异常值。
2、第一个字节是第一个异常值在原数列中的索引,第二个字节是它的高bit,将高bit左移b位,加入到第一部分已经解压出的对应位置中;
3、对于第三个字节和第四个字节也是同理。
当a = 2时,一个异常值占3个字节(一个字节索引,二个字节存放高位bit),一个4字节不能完全包含完整的异常值,因此每次需要取出12个字节,从而对4个异常值进行解压缩。
其余参数取值对应的代码:
step1B1
step1B2
step1B4
1 void PForDecompressor::step1B5() 2 { 3 unsigned l=(item_num_+5)/6; 4 unsigned i,block; 5 unsigned *con=res_; 6 for(i=0;i<l;i++) 7 { 8 block=*(data_++); 9 data_length_--; 10 con[0] = block & 31; 11 con[1] = (block>>5) & 31; 12 con[2] = (block>>10) & 31; 13 con[3] = (block>>15) & 31; 14 con[4] = (block>>20) & 31; 15 con[5] = (block>>25) & 31; 16 con+=6; 17 } 18 }step1B5
1 void PForDecompressor::step1B6() 2 { 3 unsigned l=(item_num_+4)/5; 4 unsigned i,block; 5 unsigned *con=res_; 6 for(i=0;i<l;i++) 7 { 8 block=*(data_++); 9 data_length_--; 10 con[0] = block & 63; 11 con[1] = (block>>6) & 63; 12 con[2] = (block>>12) & 63; 13 con[3] = (block>>18) & 63; 14 con[4] = (block>>24) & 63; 15 con+=5; 16 } 17 }step1B6
1 void PForDecompressor::step1B8() 2 { 3 unsigned l=(item_num_+3)/4; 4 unsigned i,block; 5 unsigned *con=res_; 6 for(i=0;i<l;i++) 7 { 8 block=*(data_++); 9 data_length_--; 10 con[0] = block & 255; 11 con[1] = (block>>8) & 255; 12 con[2] = (block>>16) & 255; 13 con[3] = (block>>24) & 255; 14 con+=4; 15 } 16 }step1B8
1 void PForDecompressor::step1B10() 2 { 3 unsigned l=(item_num_+2)/3; 4 unsigned i,block; 5 unsigned *con=res_; 6 for(i=0;i<l;i++) 7 { 8 block=*(data_++); 9 data_length_--; 10 con[0] = block & 1023; 11 con[1] = (block>>10) & 1023; 12 con[2] = (block>>20) & 1023; 13 con+=3; 14 } 15 }step1B10
1 void PForDecompressor::step1B16() 2 { 3 unsigned l=(item_num_+1)/2; 4 unsigned i,block; 5 unsigned *con=res_; 6 for(i=0;i<l;i++) 7 { 8 block=*(data_++); 9 data_length_--; 10 con[0] = block & ((1<<16)-1); 11 con[1] = block>>16; 12 con+=2; 13 } 14 }step1B16
1 void PForDecompressor::step1Ex() 2 { 3 cerr<<"Invalid b value"<<endl; 4 }step1Ex
1 void PForDecompressor::step2A2(unsigned b) 2 { 3 unsigned block1,block2; 4 while(data_length_ > 0) 5 { 6 block1 = *(data_++); 7 data_length_--; 8 res_[block1 & 255]+=((block1>>8) & 65535)<<b; 9 if(data_length_ == 0) break; 10 block2 = *(data_++); 11 data_length_--; 12 res_[block1>>24]+=(block2 & 65535)<<b; 13 if(data_length_ == 0) break; 14 block1 = *(data_++); 15 data_length_--; 16 res_[(block2>>16) & 255]+=((block2>>24) + ((block1 & 255)<<8))<<b; 17 res_[(block1>>8) & 255]+=(block1>>16)<<b; 18 } 19 }step2A2
1 void PForDecompressor::step2A3(unsigned b) 2 { 3 unsigned block; 4 while(data_length_ > 0) 5 { 6 block= *(data_++); 7 data_length_--; 8 res_[block & 255]+=(block>>8)<<b; 9 } 10 }step2A3
1 void PForDecompressor::step2A4(unsigned b) 2 { 3 unsigned block1,block2; 4 while(true) 5 { 6 if(data_length_<=1) break; 7 block1 = *(data_++); 8 block2 = *(data_++); 9 data_length_ -= 2; 10 res_[block1 & 255]+=( (block1>>8) + ((block2 & 255)<<24) )<<b; 11 if(data_length_ == 0) break; 12 block1 = *(data_++); 13 data_length_--; 14 res_[(block2>>8) & 255]+=( (block2>>16) + ((block1 && 65535)<<16) )<<b; 15 if(data_length_ == 0) break; 16 block2 = *(data_++); 17 data_length_--; 18 res_[(block1>>16) & 255]+=( (block1>>24) + ((block2 && 16777215)<<8) )<<b; 19 if(data_length_ == 0) break; 20 block1 = *(data_++); 21 data_length_--; 22 res_[block2>>24]+=block1; 23 } 24 }step2A4
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

