物联网级负载的容器:下
---
【编者的话】在《 物联网级负载的容器:上 》中我们提到,为像SAMI一样的现代IoT服务提供一个稳定安全灵活的IT环境是很有挑战性的。现在我们来探索一下,如何用Mesos和Docker过渡解决这些问题。
开始,我们决定建立一个自动化的流水线,这将使一下成为可能:
- 构建有容错、自愈功能的基础设施。
- 使用现代集群管理/分布式初始化系统,确保应用程序定义副本始终都在运行。
- 使用Git作为唯一来源:所有工作配置都存放在Git中,这能降低建立一个修改管理/审计系统的难度。
- 把应用软件打包成Docker镜像,便于快速部署。
- 建立一个快速反应的协调系统。
- 把现有的基础设施接入流水线。
- 最后,组建一个持续交付平台。它能快速强大地完成工程(包括QA)进行生产部署。这是我们的使命所在,它能把我们从日常运营的开销和冗杂中解放出来,把时间精力集中在发展新的服务和改善流程上,这样,才能为组织贡献更多价值。
为了实现以上目标,我们了提出以下设计:
- 高可用性(HA)Mesos集群将能提供数据中心(DC)级别的抽象,正如典型操作系统将能提供工作站级别的抽象一样。DC是一个新型因素。
- Mesos将作为一个DC-wide资源管理器。
- 构建系统将会把应用程序打包成Docker镜像。之后这些镜像将会被push到Docker内部私有库。
- Marathon将作为DC-wide 初始系统/进程管理器。所有的长时运行作业会通过Marathon进行部署和管理。
- Chronos将作为DC-wide cron系统。所有的短时/批处理作业会通过Chronos进行调度管理。
- 所有Marathon和Chronos的作业配置都将被check到Git。基础设施中的任何改动都会被追查到。
- Git2Consul将用于同步Git仓库到Consul的KV存储,同时Consul的handler会监视KV的改动并通过REST API报告给Marathon和Chronos。
- Consul将继续作为服务注册表。用Registrator监听Docker事件和私有库的改动并报告给Consul。这些最终将被Mesos-DNS所取代。
我们现在的工作流程大致如下几步:
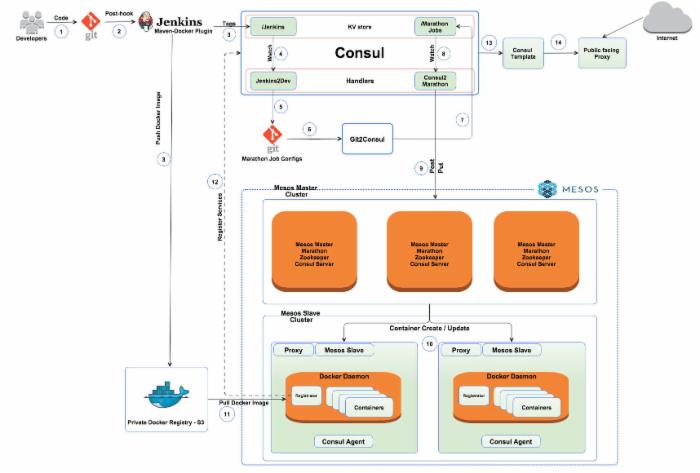
- 当开发者提交时,Git Post-Receive Hook 会开启Jenkins build。
- Jenkins接着使用maven-dockr插件进行创建、标记和push Docker镜像到Docker私有库中。它也会在Consul的KV中更新镜像标记。
- Consul Handler监视KV的更改并更新包含Marathon作业配置的Git repo。
- Git2Consul获取这些更改并将repo同步到Consul的另一个KV。
- 另一个Handler监视这个KV,将作业配置发送给Marathon。如果该服务尚未注册,创建新服务。否则更新该服务。
- Marathon作为集群管理者和分布式初始化系统。它用API调用Docker daemon来启动容器。
- Registrator(一个小型服务)监听Docker事件,更新Consul的服务目录。
- 服务注册表的任何改动都能被Consul-Template捕捉到,这将刷新所有配置(主要是HAProxy)并重新加载相关服务。
如上所述,无需人工干预,应用程序会自动创建、打包和部署到各种环境中。如果你认真理一遍就会发现整个审计线是这样的:每一步都被记录在了Git上。这点非常重要,特别是你的团队规模很大、堆栈复杂且有许多活动部分的时候。另外,如果每天进行各种版本服务的工程中的每个人都能做到这一点,你就能懂得为何部署中每一步的记录是如此重要了。
有了Mesos,我们就能更高效地运行基础设施,控制云计算指出在预算范围内。我们能够实现更高的资源利用率,而由于资源隔离,我们能够将多种服务(在Docker容器中运行)装在同一台主机上,建立真正意义上的多租户部署,借助Cassandra and Kafka之类后端,其中的应用程序可以实现共存。
回望我们已经实现的
尘埃落定,从成立到实现生产,我们总共才花了三个月的时间。没错,我们动作就是快!但不论从管理还是技术角度上来说,前进的道路上必将迎来新的挑战和阻碍。
新用户需要了解很多Mesos/Docker世界的很多新概念和细微差别。而摆脱对应用、主机和数据中心的传统思维方式不是件容易的事情。这需要一些内驱力来使不同的群体接受新概念。
从技术角度来说,尽管已有巨大的工作量,容器的生态环境仍不成熟。因此,我们在设计系统时要考虑这个因素,保证流水线的组织部分可以更改。更重要的是,你要将基础设施设计成模块化的,这样你才能更加方便地根据需求进行工具和技术的更换。
结论
有了上文中我提到的新流水线,我们可以更快的提交代码,更易于扩展,实现多租户,确保最佳的资源利用率。我们能在一些预生产堆栈里的繁重工作负载中实现将近80%的资源利用率。真难以置信,因为行业标准中的数据中心资源利用率只有8%左右!
举个例子,这里是高工作负载下我们预生产堆栈中的一个Mesos集群资源利用率情况:
curl http://10.20.0.201:5050/metrics/snapshot
{
..
"master//cpus_total":247,"master//cpus_used":192,
"master//mem_total":583573,"master//mem_used":415378,
..
}
总之,SAMI团队对新模式的转变感到非常振奋。但它涉及到大量的研究,学习和努力的工作只把我们带到这个层次。如果你们之中有人想要深入研究,一定要记住,新系统需要的改变与你之前做过的东西相差很大。我们对目达成的结果已经感到非常开心了,相信这些变化能把我们指引到对的方向!
Containers for IoT-Scale Workloads: Part 2 (翻译:马远征)
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

