特型搜索服务在线架构
什么是特型搜索
搜索返回的多条结果中,包括自自然搜索结果和特型搜索结果。
自然搜索结果是针对用户请求(query),返回互联网上相关性较高的内容。是否满足用户需求取决于互联网内容及相关性算法。
特型搜索则是针对query,线下先对内容进行挖掘、整合(线下的方式有多种,其中 知识图谱 是一个方向),线上直接返回满足用户需求的结果。比如当搜索"冰与火之歌"时,排在前面的百科、小说、影视等部分就属于特型搜索结果。
特型搜索服务模型
除了和传统搜索一样有着严格的性能要求外,特型搜索服务还有两个比较大的特点:
1. 开放:一次用户请求的结果是由多个不同的服务来完成的,而且不同的服务往往由不同的小组负责研究。
2. 收敛:如果一次请求返回了多个特型结果,需要对结果进行聚合再返回。
所以特型搜索服务模型就是在叶子节点开放、非叶子结点收敛的一种树行搜索结构:

架构实现
针对该服务模型,极端一点的做法可以让各个service自由发挥,然后通过rpc进行访问就可以了。但这样做显然是比较浪费和容易引起混乱的做法:
1. 接口标准:首先是接口问题,上游服务对下游服务进行进行聚合的时候,如果不能识别对方的返回结果,那"后来人"只能骂娘了。
2. 流量分发:下游服务虽然可以独立开发,但仍需要向上游服务申请流量,也就是流量分发的功能,这其实是可以统一处理的。
3. 服务调用:如果service之间都是通过rpc调用,当调用层次比较深的时候,在对性能要求十分严格的环境下,是不可能满足要求的。
4. 组件开发:一些通用的组件,比如日志、缓存、内存词典等,如果让每个服务都去开发,是非常浪费的。
以下对"接口标准", "流量分发", "服务调用"展开说明一下。
接口标准
接口标准是为了降低服务调用和聚合的成本。服务的接口是比较简单的,用protobuf service的描述类似:
service ServiceAPI { rpc query(message.Request) returns (message.Response); }; 其中Request表示用户的一次请求信息,对各服务都是一样的。Response稍微复杂一些,因为每个service的结果是不一样的,必须提供扩展机制。当然用protobuf是比较容易做到的:
message Response { //common fields: ... ... repeated Result = 10; }; message Result { //common fields: ... ... extensions 128 to 512; }; 当然也可以不用extensions, 而是在Result里面加入自定义Message,这样可以在Result里面看到所有的message(如果某些因素(比如历史遗留问题)要求你这么做的话),我们采用的就是后者。
流量分发
流量分发是将用户请求发送到服务的过程。要解决几个问题:
- 服务怎么知道这个请求是自己处理?还是转发再聚合?
是自己处理还是聚合其他服务,这是业务分析的时候就可以确定的,比如A服务就是要对"天气"相关的请求出结果,而B服务就是要对不同服务结果进行排序。为此,在架构上我们提供了两个基类分别满足这两种应用场景 - AtomicService 和 AggregatedService. - 如果是转发,怎么知道转发给谁?是全量转发还是部分转发?
转发其实是AggregatedService的职责,我们的转发机制也是集成在这个基类里面的。主要提供了"服务注册"和"流量分发"功能。
服务注册可以理解为是"依赖倒置"pattern的一种应用,上游服务提供注册接口,由下游服务发起注册。这样可以使新开发服务对已有服务的影响最小。你可能会问"不是要在上游服务做聚合吗"? 实际情况是很多服务其实是相对比较独立的,聚合的情况其实不会太多,也就是说一次请求很多情况只有一个AtomicService完成响应就够了。
流量分发也有不同的做法,一种做法是全量转发,由下游服务自己决定是否/如何处理。这样对下游服务来说是最好的,但是缺点是需要服务节点能承受全流量的压力。 另一种做法是在入口处先对query做一定分析,然后将服务id放入请求中,作为后续转发的一个依据。这种做法的缺陷是所有服务需要在一个地方完成query解析,也有单点带来的维护等问题。综合比较我们采用的是后者。
服务调用
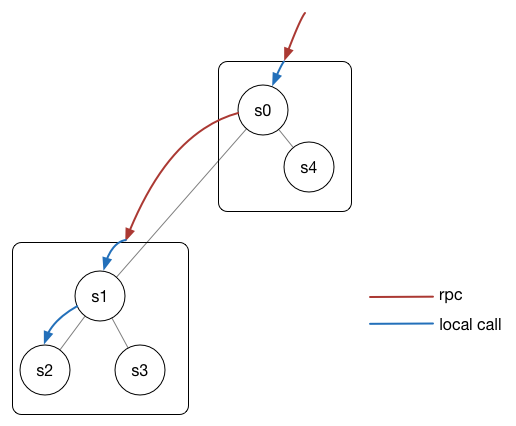
服务调用要解决的是服务加载和服务发现的问题。如果每个服务都是单独的进程,可以直接加载到rpc server中,向上注册的时候同时声明自己的server地址及端口就可以了,现成的rpc实现有 grpc 。但总有一些原因(比如性能要求、或者因为部署机制跟不上),要求service能在一个进程里面跑,同一个进程的service可以通过函数call而不是rpc调用,那将service放入一个容器(container)中,是一个不错的选择。
在我们的实现中,service是加载进一个container的,请求通过container进行转发。当向上游service注册时,需要声明自己在哪个container(这样做的一个问题是当service切换container时,需要修改上游。更好的做法可以考虑注册时只声明服务名,service和container的关系通过ZK之类的东西进行管理。我们没这样做是因为目前为止service和container的关系是稳定的)。这样container就可以发现待调用service是在container内还是外,如果是内部则通过函数call调用,外部则用rpc。
并不是任何service都可以加载到相同的container中,这对service的隔离是一个很大的限制,实际使用中我们会综合考虑服务的稳定性、开发、维护等因素。
其他
在线服务往往会对流量进行抽样然后进行小流量实验,每一个实验其实就是一个不同的service,流量分发时除了service id,可能还会考虑到抽样id,原理大致差不多。一些通用组件的开发这里先不做描述了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

