为复杂数据集开发预测分析模型
为了演示 dashDB 功能,您需要了解 Kaggle 数据挖掘比赛,以及如何使用 IBM Bluemix™ 和 dashDB 中提供的分析服务来充分参与到比赛中。即使您没有计划参加 Kaggle 比赛,也可以更深入地了解 dashDB 中的分析服务。
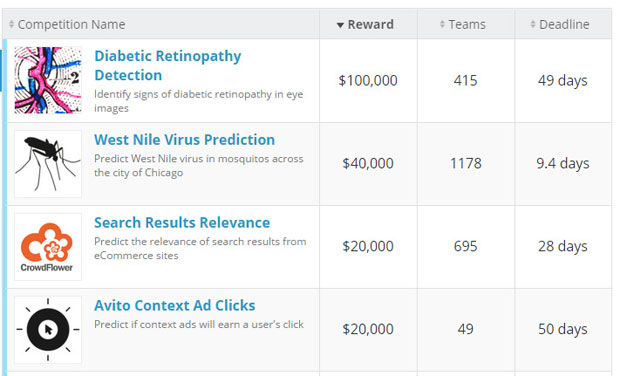
Kaggle 是一个数据科学家社区,科学家在该社区中合作解决复杂的数据科学问题。Kaggle 提供了公开的数据科学挑战,许多公司在这些挑战中提交了他们的数据。挑战(参见 图 1)发布给来自全球的统计学家和数据挖掘者,让他们比赛开发最佳的预测模型。任何人都可参与解决这些挑战,成功者将获得非常有诱惑力的奖励。
图 1. 示例 Kaggle 比赛
阅读: 进一步了解 Kaggle
构建您的应用程序需要做的准备工作
- 一个Bluemix 帐户
- 熟悉 R
阅读: 我需要学习 R 吗?
运行应用程序
获取代码
解决 Kaggle Titanic 挑战
在本教程中,我们将使用 Kaggle Titanic Challenge 。2,000 多人参加了这次比赛,该比赛是一个开始掌握数据挖掘的非常流行的用例。
本案例分析引用了 1912 年英国皇家邮轮泰坦尼克号的沉没。泰坦尼克号的灾难因为与历史上 “优先抢救妇女儿童” 的海商法有关联而出名。因为泰坦尼克号没有配备足够数量的救生艇,所以只有极少数乘客得以幸存。

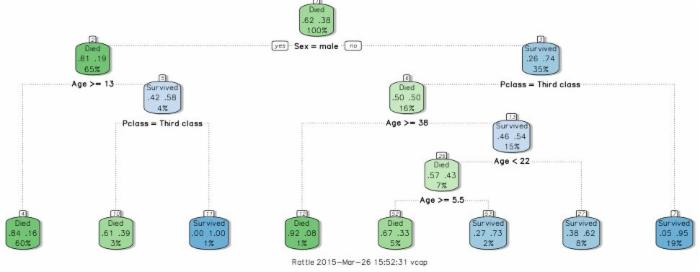
在这次挑战赛中,您需要分析哪些类型的人可能幸存。将使用一个决策树来确定泰坦尼克号的乘客是否会幸存。该决策树是根据输入参数而动态生成的。图 2 显示了将创建的一个决策树的示例。
图 2. 示例决策树
点击查看大图
关闭 [x]
图 2. 示例决策树
本教程的输出包括:
- 一个要提交给 Kaggle 挑战赛来测试您分析的准确性的平面文件
- 一个解释一些假设的 文档
- 一个 Shiny 应用程序
Kaggle 比赛需要的一些高级工具。在本教程中,我们将解释哪些工具最好以及它们为什么是最好的。
R 是 Kaggle 中使用的最流行的工具
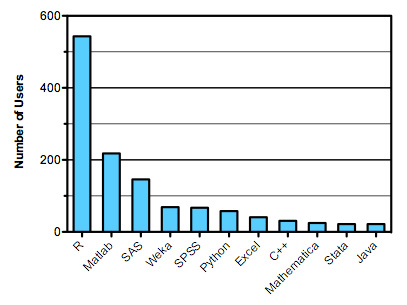
R 是 Kaggle 参赛者最常使用的工具,与随后的 Matlab 和 SAS 拉开了很大差距。图 3显示了 Kaggle 上使用的最流行工具的条形图。
图 3. 图 2:Kaggle 参赛者使用的流行工具
R 是一种用于统计计算和绘图的开源编程语言和环境。编写 R 代码的最佳 IDE 是 RStudio。
R 工具的优势源于其灵活性和广泛的功能,但众所周知,它的底层内存模型效率低下。不幸的是,由于数据集很大,许多 Kaggle 比赛都需要处理大量内存。
要在比赛中取得成功,拥有一个能在项目的不同阶段之间来回迁移并测试它们的强大基础架构非常重要。使用简单的笔记本电脑在大部分情况下已行不通。所以,要解决这些 Kaggle 比赛中的大数据挑战,可在 IBM Bluemix 分析服务中获取该基础架构。
为什么使用 dashDB?
IBM dashDB 是云上的一个强大的数据仓库解决方案,它提供了强大的分析功能。
IBM dashDB 不仅提供了数据存储空间,还全面集成了 R。这种集成具有强大的威力,因为它提供了一个完全嵌入在 Web 浏览器中的完整 R Studio 实例,是最佳的 R IDE。IBM dashDB 利用您最喜欢的工具以最佳方式解决所有分析挑战。
在尝试解决 Kaggle 比赛挑战时,需要提供合适的位置来存储数据,还需要拥有合适的软件来分析它。IBM dashDB 为二者提供了解决方案。这些解决方案都包含在云中,而且为了提供最佳性能而进行了优化,以便您可以将精力集中在算法上,而不是处理基础架构。
阅读: 进一步了解 dashDB 技术
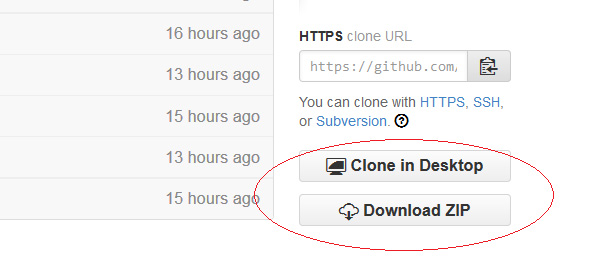
第 1 步. 从 Github 复制存储库
单击上面的 获取代码 按钮从 Github 导出源代码。单击 Download ZIP 获取整个项目。
第 2 步. 在 Bluemix 上创建一个 dashDB 实例
- 登录您的 Bluemix 帐户 (或 注册一个免费试用帐户 )。
- 转到仪表板并下滚到 Services 。
- 单击 Add a service or API 。
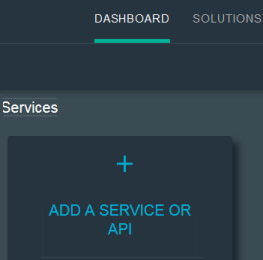
- 单击 Big Data 类别或使用 Catalog 选项卡顶部的搜索框找到 dashDB 服务。

点击查看大图
关闭 [x]
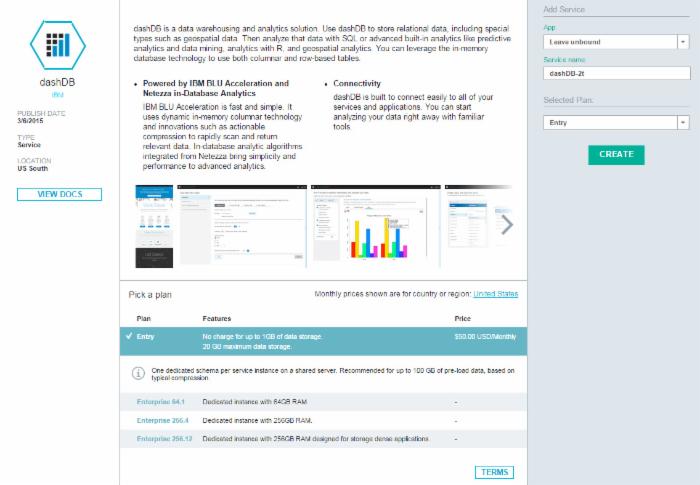
- 单击 dashDB
。然后完成以下字段:
- 在 App 字段中,选择 Leave unbound 。
- 保留 Service Name 字段的默认值。
- 在 Selected Plan 字段中,选择 Entry 。如果需要,可以在未来更新它。
- 单击 Create 。
点击查看大图
关闭 [x]
几秒之后,您的 Bluemix 仪表板中将会有一个 dashDB 实例。
第 3 步. 将数据加载到 dashDB 中
在大多数 Kaggle 比赛中,您都会获得两个数据集:
- 一个包含正确或预期的输出的培训数据集。这个数据集被用来培训您的模型的数据集。
- 一个用于测试您模型的预测能力和健全性的测试数据集。
可在第 1 步中下载的 Github 上的存储库中的 data 目录中找到这些数据集。
要将这些数据集加载到 dashDB 中:
- 可单击 IBM Bluemix 仪表板中的 dashDB 服务,然后单击 Launch 。
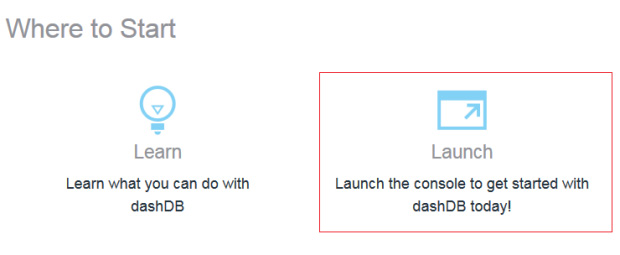
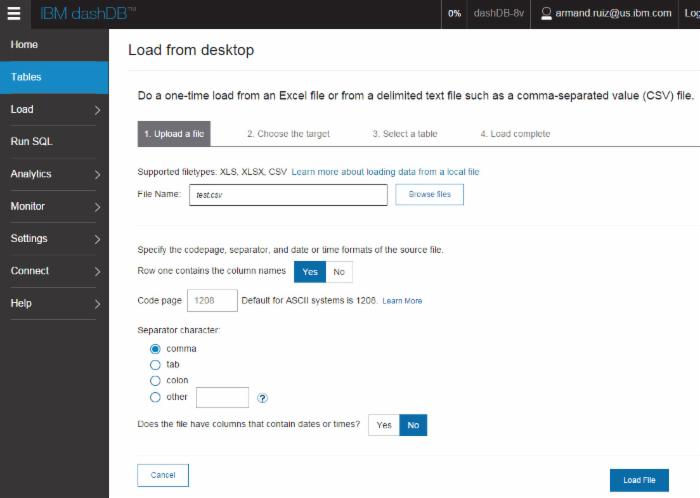
- 在打开的 IBM dashDB 管理控制台中,单击 Load your data 按钮。
- 在 File Name 字段中,单击 Browse files 找到 test.csv 文件,保留所有选项设置为默认值。单击 Load File ,然后单击 Next 。
点击查看大图
关闭 [x]
- 在 Choose the target 选项卡中,选择 Create a new table and load ,然后单击 Finish 。几秒之后,您的数据就会加载到数据库中。
- 对 train.csv 数据集重复这些步骤。
第 4 步. 在 RStudio 中打开您的项目
- 要打开 RStudio,可在主菜单中单击 Analytics ,然后单击 R Scripts 。
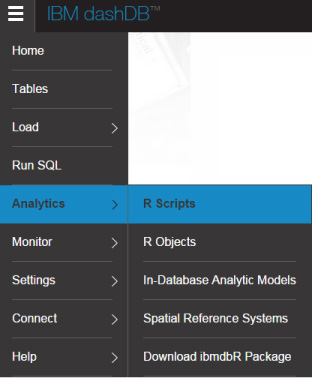
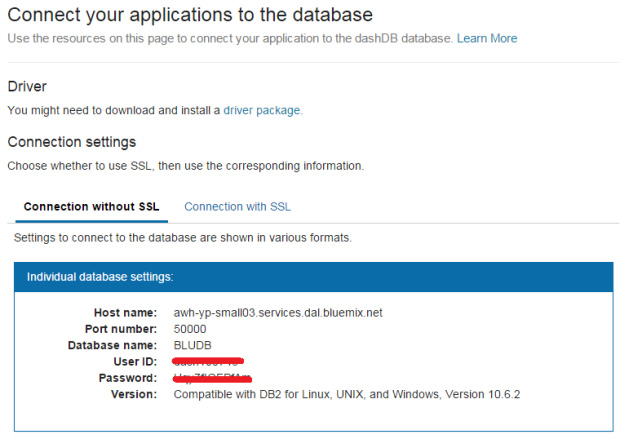
- 单击 RStudio 。这将打开一个新选项卡,您可以使用它进行登录。您的用户名和密码可以在 dashDB 管理控制台中的 Connect→Connection Settings 中找到。
登录后,您就处于嵌入到 Web 浏览器中的一个完整的 RStudio 实例中。
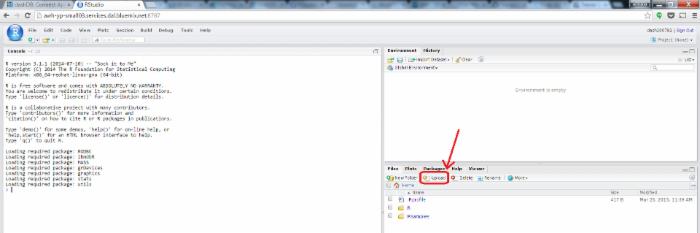
点击查看大图
关闭 [x]
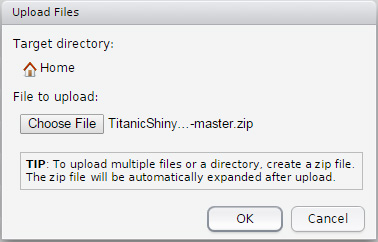
- 单击 Files 节中的 Upload ,然后选择您从 Github 下载的名为 TitanicShinyApp-master.zip 的 zip 文件。(确保您上传了压缩的文件;未压缩版本不会作为单个文件附加。)
- 在 RStudio 控制台中运行下面这条命令。每次出现弹出消息时都回答 Yes
。
source("TitanicShinyApplication-master/init.r")
此命令将您需要的一些包安装在云中的 R 实例中。这是个一次性过程;安装这些包后,不需要再执行安装。
第 5 步. 开始分析数据
IBM dashDB 提供了一个名为 ibmdbR 的 R 包,它已安装在 dashDB 中您的 RStudio 实例中。这个包将许多基本和复杂的 R 操作推入数据库中,这会消除 R 的主要内存边界,有助于在底层数据中充分利用并行处理能力。
在 R 中,使用一个数据帧来存储数据表,这就像数据的电子表格。要使用数据库中的数据创建数据帧,可运行以下命令:
library(ibmdbR) con <- idaConnect("BLUDB","","") idaInit(con) query1<-paste('select * from train') trainDF <- idaQuery(query1,as.is=F) 图 4 显示了 RStudio 中显示的数据帧。
图 4. 泰坦尼克号数据集的数据帧的屏幕截图
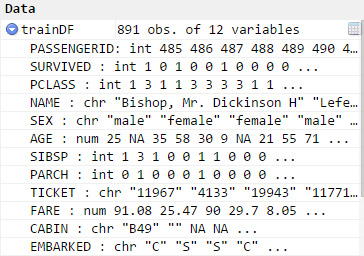
将数据加载到 RStudio 中后,可应用许多不同的技术来分析数据并开始构建预测模型。本教程的目的不是介绍支撑预测模型的数学原理。为了提交用于比赛的模型,您需要构建一个包含乘客 ID 和幸存概率预测值的 CSV 文件。“ R 入门:Kaggle 中的泰坦尼克比赛 ” 中的 R Markdown 列出了一些可使用的技术:
- 简单的假设(每个人都死了)
- 手动模式选择(Gender-Class 模型)
- 决策树
- 特征工程
- 随机森林
第 6 步. 部署一个 Shiny 应用程序
在 RStudio 中,可以使用 Shiny 框架创建一种交互式、基于 Web 的方法来可视化和共享结果。
阅读: 自学 Shiny
您可以通过各种各样的方式来运行和创建 R Shiny 应用程序。例如,可以使用下面这条命令直接从 GitHub 存储库运行应用程序:
runGitHub("TitanicShinyApplication","aruizga7")
R Shiny 应用程序的文件包含在第 4 步中上传的存储库中。随意自定义应用程序。要运行它,可执行下面这条命令:
runApp("TitanicShinyApplication-master")
在 R Shiny 应用程序中,不需要使用 HTML、CSS 或 JavaScript 知识。可向分析中添加不同的文档,比如布局、控件、小部件和显示。我们的 Titanic 应用程序包含 4 个选项卡:
- Data Exploration :Data Exploration 选项卡始终是数据挖掘项目中的第一步。它可以帮助您熟悉数据,识别一些洞察或有趣的数据子集。在左侧菜单上,您可以为 x 和 y 轴选择不同的属性,一些复选框表示过滤数据的各个方面。
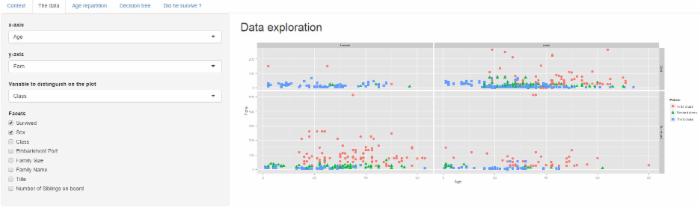
点击查看大图
关闭 [x]
- Survival by age range :在这个选项卡中,有两个图表。第一个图表是年龄范围的柱状图;可使用一个控件来选择要在图表中考虑的年龄范围数量。第二个图表显示年龄的阶级分布。

点击查看大图
关闭 [x]
- Decision tree :decision tree 选项卡使用包 rpart 来生成。使用左侧的复选框菜单,您可选择将用来构建decision tree
的变量。
该算法首先会处理根节点上的所有数据,扫描所有变量以找到最适合拆分的变量。
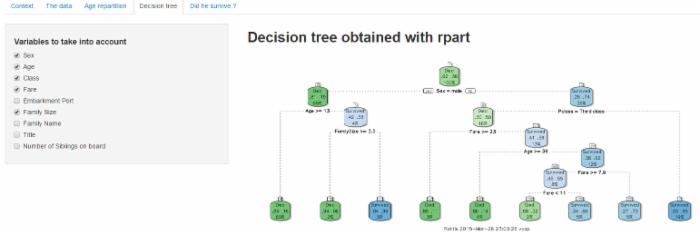
点击查看大图
关闭 [x]
- Prediction: Prediction 选项卡提供了一个可用作决策树的输入的特征菜单。决策树用来根据乘客的特征预测他或她是否会幸存。
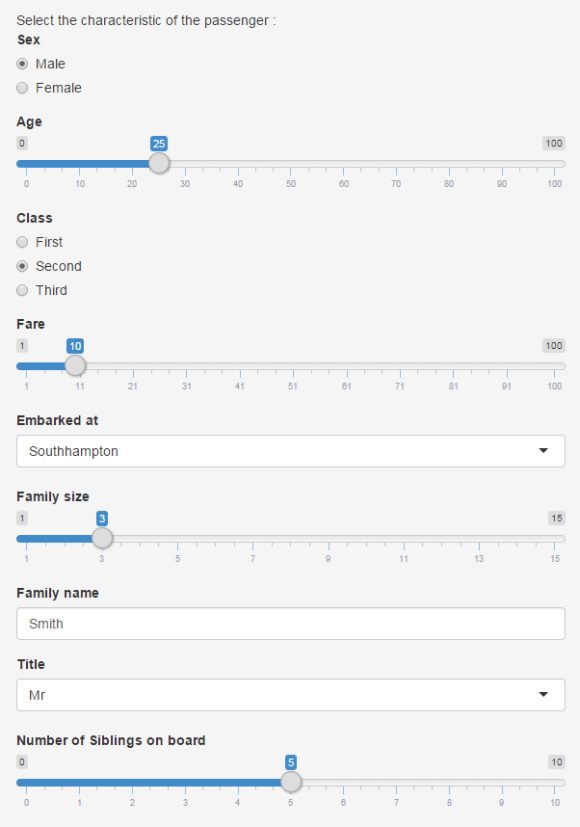
点击查看大图
关闭 [x]
结束语
在本教程中,您学习了 IBM dashDB,这个解决方案集成了云上的数据仓库和分析技术,还全面集成了 RStudio 来实现强大的分析。使用 IBM Bluemix,我们展示了如何在云上创建一个具有 R 分析功能的 dashDB 实例,为您的数据集开发一个预测模型,然后利用 R 的 Shiny 应用程序框架生成交互式、可靠的可视化展示和预测结果。最后,我们还介绍了 Kaggle 数据挖掘比赛。我们邀请您了解这次比赛,了解数据挑战,并使用这些强大的工具创建您自己的预测模型和可视化展示。
相关主题: IBM dashDB
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

