一种基于Storm的可扩展即时数据处理架构思考
问题引入
使用storm可以方便的构建一种集群式的数据框架,并通过定义topo来实现业务逻辑。
但使用topo存在一个缺点, topo的处理能力来自于其启动时设置的worker数目,在很多情况下,我们需要能够根据业务压力来调整集群的处理能力,这时候单一的topo就无法解决这个问题了。
为了能够更加灵活的定义处理能力,可以考虑将原有的topo根据业务域进行拆分,做到互不干扰,灵活控制,而且为了能够更加经济的利用处理资源,可以考虑引入worker资源池的概念,达到对资源的充分利用。
但使用这种多topo架构存在一个致命问题,storm中的topo是各自独立,无法直接通信的,因此在获取某些关键资源时,可能会出现资源争抢的情况的。面对此种场景,有两种处理思路:
其一:使用zookeeper等提供的分布式锁,来实现对关键资源的控制,缺点是可靠性及效率存在问题,使用与对处理效率要求不高的场景。
其二:由第三方对关键资源进行分配,规避由topo本身对资源的争抢,这种方案引入了新的构建,提高了系统的复杂度。

处理架构
集群的优点是处理能力可扩展,但会带来数据同步、开发维护复杂度以及数据一致性等问题。
我们现在虽然已经有了很多集群处理框架及相应组件用来简化相应的开发及维护工作量,但从项目开发的实际来看,我们还是需要处理一些没有被成熟组件包含但又非常棘手的问题。
storm定义的集群可以提供方便的可扩展处理能力,在整个集群中,topo都是等价的,在storm运行环境内部,topo之间也无法交流。
回到上面的问题,通过storm,我们获得了即时的集群处理能力;通过topo,我们可以自定义业务,并方便的在节点中分发;通过worker数目的变化,可以调整其处理能力。
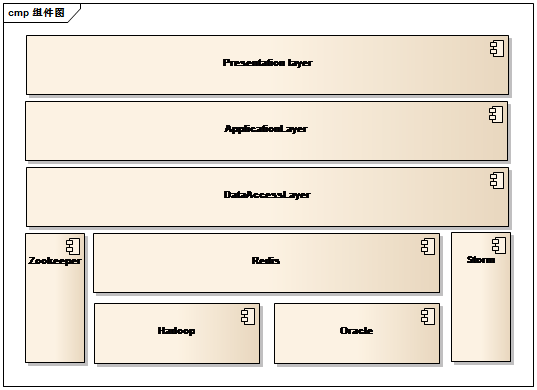
如果辅以Hadoop等大数据存储平台及Redis缓存,加以使用zookeeper构成的分布式锁,已经基本可以构建一套即时的可扩展的大数据处理平台。
组件图
多top的初始化
下面是一个基于storm的多拓扑初始化的类视图:

关键点与思考
缓存策略
因为是即时的数据处理平台,其存在对效率的要求,而数据库存储的访问通常称为瓶颈,因此在此设计了缓存,选型Redis是引起使用已经较为广泛和稳定,业界也存在较为成熟的缓存构建策略。
分布式锁
分布式锁至关重要,尤其是如果storm集群中存在多个topo的情况下,非常可能存在对关键资源的争夺。
使用zookeeper构建分布式锁已经存在较为成为的应用,但使用zookeeper构建的分布式锁必定也存在健壮性不足和锁的效率问题,需要在设计时加以考虑。
Hadoop和Oracle的协作
从使用成本和使用场景上,这两个组件就存在很大不同。
在应用时,Hadoop可以用以存储非结构化的数据,例如原始结果。由于Oracle在存储结构化数、可靠性以及易用性上的巨大优势,可以选择将最终处理结果存放于Oracle之中,利于维护和展示。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

