Hadoop的Server及其线程模型分析
早期的一篇文章,针对Hadoop 2.6.0.这里发一下.
一、Listener
Listener线程,当Server处于运行状态时,其负责监听来自客户端的连接,并使用Select模式处理Accept事件。
同时,它开启了一个空闲连接(Idle Connection)处理例程,如果有过期的空闲连接,就关闭。这个例程通过一个计时器来实现。
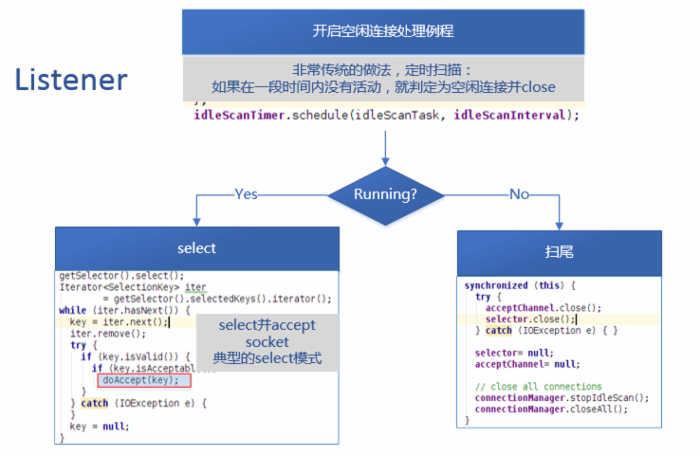
当select操作调用时,它可能会阻塞,这给了其它线程执行的机会。当有accept事件发生,它就会被唤醒以处理全部的事件,处理事件是进行一个doAccept的调用。
doAccept:
void doAccept(SelectionKey key) throws InterruptedException, IOException, OutOfMemoryError { ServerSocketChannel server = (ServerSocketChannel) key.channel(); SocketChannel channel; while ((channel = server.accept()) != null) { channel.configureBlocking(false); channel.socket().setTcpNoDelay(tcpNoDelay); channel.socket().setKeepAlive(true); Reader reader = getReader(); Connection c = connectionManager.register(channel); key.attach(c); // so closeCurrentConnection can get the object reader.addConnection(c); } } 由于多个连接可能同时发起申请,所以这里采用了while循环处理。
这里最关键的是设置了新建立的socket为非阻塞,这一点是基于性能的考虑,非阻塞的方式尽可能的读取socket接收缓冲区中的数据,这一点保证了将来会调用这个socket进行接收的Reader和进行发送的Responder线程不会因为发送和接收而阻塞,如果整个通讯过程都比较繁忙,那么Reader和Responder线程的就可以尽量不阻塞在I/O上,这样可以显著减少线程上下文切换的次数,提高cpu的利用率。
最后,获取了一个Reader,将此连接加入Reader的缓冲队列,同时让连接管理器监视并管理这个连接的生存期。
获取Reader的方式如下:
//最简单的负载均衡 Reader getReader() { currentReader = (currentReader + 1) % readers.length; return readers[currentReader]; }二、Reader
当一个新建立的连接被加入Reader的缓冲队列pendingConnections之后,Reader也被唤醒,以处理此连接上的数据接收。
public void addConnection(Connection conn) throws InterruptedException { pendingConnections.put(conn); readSelector.wakeup(); }Server中配置了多个Reader线程,显然是为了提高并发服务连接的能力。
下面是Reader的主要逻辑:
while(true) { ... //取出一个连接,可能阻塞 Connection conn = pendingConnections.take(); //向select注册一个读事件 conn.channel.register(readSelector, SelectionKey.OP_READ, conn); ... //进行select,可能阻塞 readSelector.select(); ... //依次读取数据 for(keys){ doRead(key); } ... } 当Server还在运行时,Reader线程尽可能多地处理缓冲队列中的连接,注册每一个连接的READ事件,采用select模式来获取连接上有数据接收的通知。当有数据需要接收时,它尽最大可能读取select返回的连接上的数据,以防止Listener线程因为没有运行时间而发生饥饿(starving)。
如果Listener线程饥饿,造成的结果是并发能力急剧下降,来自客户端的新连接请求超时或无法建立。
注意在从缓冲队列中获取连接时,Reader可能会发生阻塞,因为它采用了LinkedBlockingQueue类中的take方法,这个方法在队列为空时会阻塞,这样Reader线程得以阻塞,以给其它线程执行的时间。
Reader线程的唤醒时机有两个:
- Listener建立了新连接,并将此连接加入1个Reader的缓冲队列;
- select调用返回。
在Reader的doRead调用中,其主要调用了readAndProcess方法,此方法循环处理数据,接收数据包的头部、上下文头部和真正的数据。这个过程中值得一提的是下面的这个channelRead方法:
private int channelRead(ReadableByteChannel channel, ByteBuffer buffer) throws IOException { int count = (buffer.remaining() <= NIO_BUFFER_LIMIT) ? channel.read(buffer) : channelIO(channel, null, buffer); if (count > 0) { rpcMetrics.incrReceivedBytes(count); } return count; } channelRead会判断数据接收数组buffer中的剩余未读数据,如果大于一个临界值NIO_BUFFER_LIMIT,就采取分片的技巧来多次地读,以防止jdk对large buffer采取变为direct buffer的优化。
这一点,也许是考虑到direct buffer在建立时会有一些开销,同时在jdk1.6之前direct buffer不会被GC回收,因为它们分配在JVM的堆外的内存空间中。
到底这样优化的效果如何,没有测试,也就略过。也许是为了减少GC的负担。
在Reader读取到一个完整的RpcRequest包之后,会调用processOneRpc方法,此调用将进入业务逻辑环节。这个方法,会从接受到的数据包中,反序列化出RpcRequest的头部和数据,依此构造一个RpcRequest对象,设置客户端需要的跟踪信息(trace info),然后构造一个Call对象,如下图所示:

此后,在Handler处理时,就以Call为单位,这是一个包含了与连接相关信息的封装对象。
有了Call对象后,将其加入Server的callQueue队列,以供Handler处理。因为采用了 put 方法,所以当callQueue满时(Handler忙),Reader会发生阻塞,如下所示:
callQueue.put(call); // queue the call; maybe blocked here三、Handler
Handler就是根据rpc请求中的方法(Call)及参数,来调用相应的业务逻辑接口来处理请求。
一个Server中有多个Handler,对应多个业务接口,本篇不讨论具体业务逻辑。
handler的逻辑基本如下(略去异常和其它次要信息):
public void run() { SERVER.set(Server.this); ByteArrayOutputStream buf = new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE); while (running) { try { final Call call = callQueue.take(); // pop the queue; maybe blocked here CurCall.set(call); try { if (call.connection.user == null) { value = call(call.rpcKind, call.connection.protocolName, call.rpcRequest, call.timestamp); } else { value = call.connection.user.doAs(...); } } catch (Throwable e) { //略 ... } CurCall.set(null); synchronized (call.connection.responseQueue) { responder.doRespond(call); } } 可见,Handler从callQueue中取出一个Call,然后调用这个Server.call方法,最后调用Responder的doResponde方法将结果发送给客户端。
Server.call方法:
public Writable call(RPC.RpcKind rpcKind, String protocol, Writable rpcRequest, long receiveTime) throws Exception { return getRpcInvoker(rpcKind).call(this, protocol, rpcRequest, receiveTime); }四、Responder
一个Server只有1个Responder线程。
此线程不断进行如下几个重要调用以和Handler协调并发送数据:
//这个wait是同步作用,具体见下面分析 waitPending(); ... //开始select,或许会阻塞 writeSelector.select(PURGE_INTERVAL); ... //如果selectKeys有数据,就依次异步发送数据 for(selectorKeys){ doAsyncWrite(key); } ... //当到达丢弃时间,会从selectedKeys构造calls,并依次丢弃 for(Call call : calls) { doPurge(call, now); }当Handler调用doRespond方法后,handler处理的结果被加入responseQueue的队尾,而不是立即发送回客户端:
void doRespond(Call call) throws IOException { synchronized (call.connection.responseQueue) { call.connection.responseQueue.addLast(call); if (call.connection.responseQueue.size() == 1) { //注意这里isHandler = true,表示可能会向select注册写事件以在Responder主循环中通过select处理数据发送 processResponse(call.connection.responseQueue, true); } } } 上面的synchronized 可以看出,responseQueue是争用资源,相应的:
Handler是生产者,将结果加入队列;Responder是消费者,从队列中取出结果并发送。
processResponse将启动Responder进行发送,首先从responseQueue中以非阻塞方式取出一个call,然后以非阻塞方式尽力发送call.rpcResponse,如果发送完毕,则返回。
当还有剩余数据未发送,将call插入队列的第一个位置,由于isHandler参数,在来自Handler的调用中传入为true,所以会唤醒writeSelector,并注册一个写事件,其中incPending()方法,是为了在向selector注册写事件时,阻塞Responder线程,后面有分析。
call.connection.responseQueue.addFirst(call); if (inHandler) { // set the serve time when the response has to be sent later call.timestamp = Time.now(); incPending(); try { // Wakeup the thread blocked on select, only then can the call // to channel.register() complete. writeSelector.wakeup(); channel.register(writeSelector, SelectionKey.OP_WRITE, call); } catch (ClosedChannelException e) { //Its ok. channel might be closed else where. done = true; } finally { decPending(); } } 再回到Responder的主循环,看看如果向select注册了写事件会发生什么:
//执行这句时,如果Handler调用的responder.doResonde()正在向select注册写事件,这里就会阻塞 //目的很显然,是为了下句的select能获取数据并立即返回,这就减少了阻塞发生的次数 waitPending(); // If a channel is being registered, wait. //这里用超时阻塞来select,是为了能够在没有数据发送时,定期唤醒,以处理长期未得到处理的Call writeSelector.select(PURGE_INTERVAL); Iterator<SelectionKey> iter = writeSelector.selectedKeys().iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); iter.remove(); try { if (key.isValid() && key.isWritable()) { //异步发送 doAsyncWrite(key); } } catch (IOException e) { LOG.info(Thread.currentThread().getName() + ": doAsyncWrite threw exception " + e); } } 重点内容都做了注释,不再赘述。可以看出,既考虑同步,又考虑性能,这是值得学习的地方。
五、总结
本篇着重分析了hadoop的rpc调用中server部分,可以看出,这是一个精良的设计,考虑的很细。
-
关于同步:
Listener生产,Reader消费;Reader生产,Handler消费,Handler生产,Responder消费。
所以它们之间必须同步.在具体的hadoop实现中,既有利用BlockingQueue的put&take操作实现阻塞,以达到同步目的,也对争用资源使用synchronized来实现同步。
-
关于缓冲:
其中几个缓冲队列也值得关注.Server的并发请求会特别多,而Handler在执行call进行业务逻辑时,肯定会慢下来,所以必须建立请求和处理之间的缓冲。
另外,处理和发送之间也同样会出现速率不匹配的现象,同样需要缓冲。
-
关于线程模型:
Listener单线程,Reader多线程,Handler多线程,Responder单线程,为什么会这样设计?
Listener采用select模式处理accept事件,一个客户端在一段时间内一般只建立有限次的连接,而且连接的建立是比较快的,所以单线程足够应付,建立后直接丢给Reader,从而自己很从容地应付新连接。
Handler多线程,业务逻辑是大头,又很大可能会牵涉I/O密集(HDFS),如果线程少,耗时过长的业务逻辑可能就会让大部分的Handler线程处于阻塞,这样轻快的业务逻辑也必须排队,可能会发生饥饿。如果Reader收集的请求队列长时间处于满的状态,整个通讯必然恶化,所以这是典型的需要降低响应时间、提升吞吐量的高并发时刻,这个时刻的上下文切换是必须的,不纠结,并发为重。
Responder是单线程,显然,Responder会比较轻松,因为虽然请求很多,但经过Reader->Handler的缓冲和Handler的处理,上一批能发送完的结果已经发送了。Responder更多的是搜集并处理那些长结果,并通过高效select模式来获取结果并发送。
这里,Handler在业务逻辑调用完毕直接调用了responder.doRespond发送,是因为这是个立即返回的调用,这个调用的耗时是很少的,所以不必让Handler因为发送而阻塞,进一步充分发挥了Handler多线程的能力,减少了线程切换的机会,强调了其多线程并发的优势,同时又为responder减负,以增强Responder单线程作战的信心。
-
关于锁对Hadoop来讲,因为同步需求,所以加锁是必不可少的。性能是需要考虑,但是从工程的角度上来看,通讯层的稳定性、代码可维护性、保持代码结构的相对简单性(其代码因历史原因已非常复杂),大部分采用了synchronized这种悲观得、重型的加锁方式,这样,可以显著减少对象之间同步的复杂性,减少错误的发生。
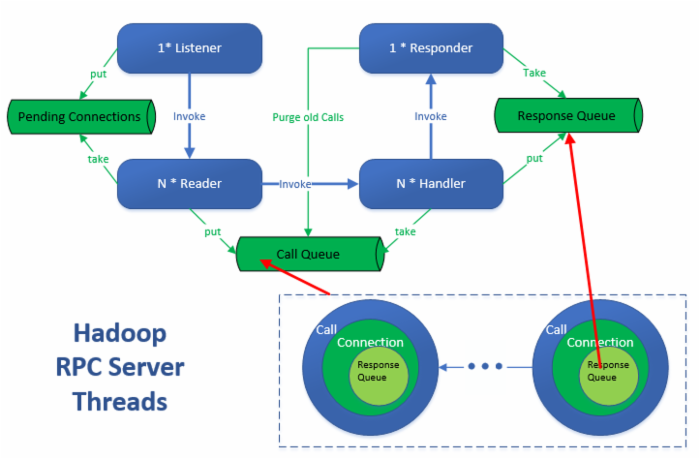
六、(补充)RpcServer 线程模型
NameNode启动过程:

线程模型
Listener 1个:
- 监听并接受来自客户端的连接.将新建连接放入pendingConnections.
- 清理空闲连接.
- 唤醒Reader.
Reader N个 : 从pendingConnections中获取连接,读取数据,从RpcRequest构造Call,并放入callQueue.
Handler N 个:
- 从callQueue获取客户端调用call,并执行.
- 调用Responder,将结果加入responseQueue的尾部.这里会调用一次发送.如果数据未发送完,注册
WRITE事件到selector.并唤醒Responder.
Responder 1个:
- 从responseQueue中按照FIFO顺序发送数据.
- 处理
selectorselect出的数据. - 扫描callQueue,并丢弃过期的Call.
终.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

