数据库的 Consistency 与 Leaky Abstraction
最近在 学习 各大互联网公司是如何处理数据一致性的。因为之前从事的不是这个方向的工作,所以并非什么经验之谈,只是一些学习笔记。所有资料来自互联网。
Consistent => Eventual Consistent
这个是陈词滥调了。很多文章已经讲过什么是CAP,什么是BASE了。互联网业务“需要”Eventual Consistency貌似已经是共识了。Eric Bewer最近接受的一次采访,很好的总结了现状( https://medium.com/s-c-a-l-e/google-systems-guru-explains-why-containe... )
You allow things to be inconsistent and then you find ways tocompensate for mistakes, versus trying to prevent mistakes altogether.
并且举了一个金融行业的例子:ATM机与银行是联网的,当网络中断了你去ATM上取钱,ATM仍然会吐钱给你。这就说明了即便是银行也选择了availability而不是consistency。但是你取第二笔就会拒绝掉。
Eventual Consistent => Consistent
这是一个比前一个趋势有趣得多的现象。Eventual Consistent是数据层的不负责任,把hard work上推给了应用层的开发:
- 要么设计各种规则,去compensate边边角角的异常情况
- 要么在有限一致性约束下,work around一些设计(比如只有单key的一致性的数据库,要一致就得放到一个key下)
我觉得有一个不太被重视的研究方向是架构的选择与开发者的生产效率的关系:
- 数据库只给你一个k/v模型,业务的逻辑的需求多种多样,无比怀念sql啊
- 数据库只有eventual consistency,要设计各种对账逻辑去compensate,无比蛋疼啊
- 异步I/O到处都是callback,逻辑被切成了意大利面条啊
- 到处鼓吹micro service,跨服务的事务你来搞啊?
最近在hacker news上看到关于technical debt的文章,排第一位的不是bad code,而是unfit architecture(小孩子才分对错)很说明了群众的情绪 https://news.ycombinator.com/item?id=9963994
这篇文章( http://queue.acm.org/detail.cfm?ref=rss&id=2610533 )详细描述了Eventual Consistent的各种蛋疼之处:

本来评论的顺序是:
Alice: 我把戒子丢了
Alice: 欧,在楼上找到了
Bob:真为你高兴
从西海岸同步到东海岸的IDC之后,因为乱序和到达延迟,可能就变成这样了
Alice:我把戒子丢了Bob:真为你高兴
晕倒,Bob这是起啥哄呢?你不要以为这个例子是编出来的哦。目前主流的解决方案是把评论合到一个key内存储,每次跨idc同步是把一个key整体同步。评论归属于一个主idc,修改只在那个idc发生。要是评论超级长呢?一个key可以存储的数据量是有上限的哦。
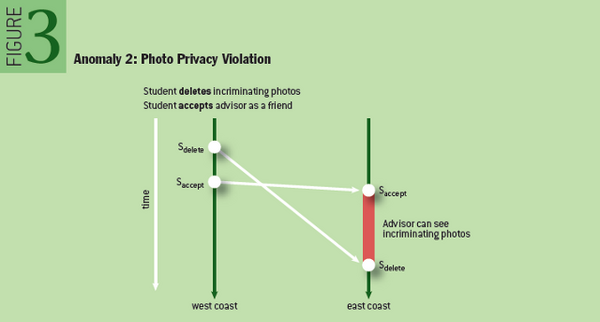
这个例子是SNS里为数不多需要强一致的场景。student和advisor是朋友,代表了一种授权。这种权限的变更如果不是立即生效的,就会导致用户隐私的泄漏。
本来的顺序:
student删除了隐私图片
student把advisor加为好友
实际的顺序:
student把advisor加为好
[期间advisor可以看到student的所有图片,包括隐私图片]
student删除了隐私图片
一种更常见的形式是先把另外一个人拉黑,然后发朋友圈。这就要求关系链的变更不能是Eventual Consistent。
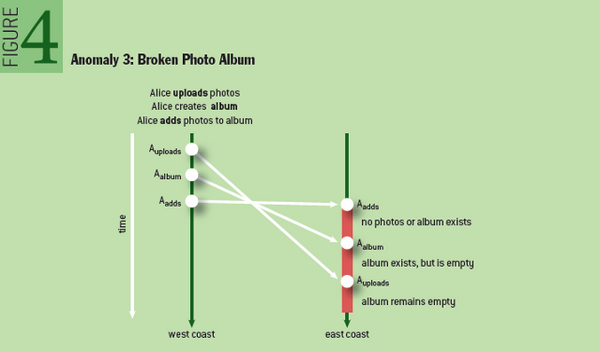
alice上传了照片
alice创建了一个专辑
alice把照片整理到专辑里
实际的顺序:
alice把照片整理到专辑里(这时既没有照片,也没有专辑)
alice创建了一个专辑
alice上传了照片
最终照片没有整理到专辑里
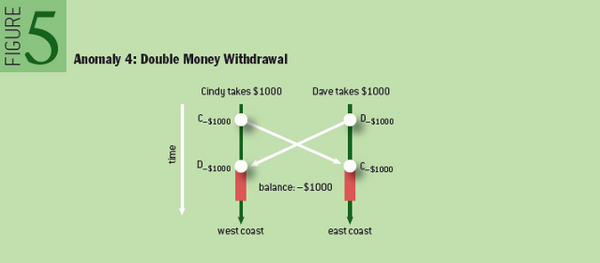
共同账户里本来有1000
cindy在idc1从共同账户里取了1000
dave同时在idc2从共同账户取了1000
两个idc的数据同步之后发现账户的余额是-1000了
Spanner
Google Spanner 在其paper里的这段话最能说明这种反思的情绪:
We believe it is better to have application programmers deal with
performance problems due to overuse of transactions as bottlenecks
arise, rather than always coding around the lack of transactions
就是你可以说一致性会导致延迟上升,可以说可用性变差,但是不能直接拿走强一致这种选项。目前已知的有这么几种数据库做到geo replicated情况下的强一致性:
- google spanner/f1
- cockroachdb
- 淘宝 oceanbase 淘宝顶级科学家阳振坤微博号@阿里正祥,发出一则消息。“从上周五开始,淘宝/天猫/聚划算在支付宝上的交易,100%都在OceanBase上了。你可能没有什么感觉。”
- 微信 quorum kv: http://www.infoq.com/cn/presentations/weixin-background-memory-archite...
Leaky Abstraction
这些数据库是银弹了吗?是不是有了这种号称全球分布的强一致数据库之后就不用考虑数据是分布的事实了呢?考虑这样一个极端情况:
我们写了一个x信。A君在深圳,B君在加拿大。A君给B君发了一条消息,就是在数据库里修改了两条记录。然后因为数据库是consistent的,内部把改动replicate到了北美,B君就可以看到消息了。
总感觉哪里有点不对。x信做为一个类似的电话公司的机构,两个用户跨大洋的通信居然不是其业务层的逻辑(比如长途费啥的),而是由底层的数据库部门来完成。这不是很奇怪的事情么?更极端的假设
我们写了一个y信,可以在地球和kepler 452b之间进行通信。A君在地球,B君在4000光年外的kepler452b上。A向B上发消息就是修改了两条数据库记录,因为数据库是consistent的,B君就收到了。
这就显然不对了。我们知道星际间的通信绝对不可能被一个consistent的假象屏蔽掉的。说到底,数据库怎么也是一个leaky abstraction
- 你可以提供一个consistent的假象,但是必须明白这背后的是至少一个跨idc的rtt的延时代价
- 你可以提供一个全球分布的假象,到头来什么用户的数据放在哪个idc是业务决定(就近访问降低延迟,另外也有法律规定)也不是数据库的决定
- 因为光速的不可超越,所以大部分不要求强一致的场景(比如关系链变更v.s.消息收发)还是要用queue的方式去做。只是这个queue一定是database的replication queue,还是业务层的event queue的区别而已。一个通信企业,其核心的跨洋通信管道是database replication queue,都不算业务逻辑,你感受一下这和当年用Database trigger写业务逻辑的区别
所以哪怕有spanner:
- 用做一种高级的容灾工具
- 偶尔在需要全局强一致的情况下,做横跨大洋的事务
- 大部分的事务是在同一个zone内的,zone间的通信仍然是业务逻辑可见的queue
- 国内的企业已经利用spanner类似的工具可以做到同城三园区强一致容灾了,跨城仍然是eventual consistent的,部分业务场景特殊work around
- google利用spanner已经可以做到北美东西南三片区强一致容灾了,猜测其真正需要跨大洋的事务用途还是很少的
最后再次强调一下
因为之前从事的不是这个方向的工作,所以并非什么经验之谈,只是一些学习笔记。所有资料来自互联网。
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

