从优化到再优化,最长公共子串
最长公共子串(Longest Common Substring) 是一个非常经典的面试题目,在实际的程序中也有很高的实用价值,所以把该问题的解法总结在本文重。不过不单单只是写出该问题的基本解决代码而已,关键还是享受把学习算法一步步的优化,让时间和空间复杂度一步步的减少的惊喜。
概览
最长公共子串问题的基本表述为:
给定两个字符串,求出它们之间最长的相同子字符串的长度。
最直接的解法自然是找出两个字符串的所有子字符串进行比较看他们是否相同,然后取得相同最长的那个。对于一个长度为 n 的字符串,它有 n(n+1)/2 个非空子串。所以假如两个字符串的长度同为n,通过比较各个子串其算法复杂度大致为 O(n4) 。这还没有考虑字符串比较所需的时间。简单想想其实并不需要取出所有的子串,而只要考虑每个子串的开始位置就可以,这样可以把复杂度减到 O(n3) 。
但这个问题最好的解决办法是 动态规划法 ,在后边会更加详细介绍这个问题使用动态规划法的契机: 有重叠的子问题 。进而可以通过空间换时间,让复杂度优化到 O(n2) ,代价是空间复杂度从 O(1) 一下子提到了 O(n2) 。
从时间复杂度的角度讲,对于最长公共子串问题, O(n2) 已经是目前我所知最优的了,也是面试时所期望达到的。但是对于空间复杂度 O(n2) 并不算什么,毕竟算法上时间比空间更重要,但是如果可以省下一些空间那这个算法就会变得更加美好。所以进一步的可以把空间复杂度减少到 O(n) ,这是相当美好了。但有一天无意间让我发现了一个算法可以让该问题的空间复杂度减少回原来的 O(1) ,而时间上如果幸运还可以等于 O(n) 。
暴力解法 – 所得即所求
对于该问题,直观的思路就是问题要求什么就找出什么。要子串,就找子串;要相同,就比较每个字符;要最长就记录最长。所以很容易就可以想到如下的解法。
int longestCommonSubstring_n3(const string& str1, const string& str2) { size_t size1 = str1.size(); size_t size2 = str2.size(); if (size1 == 0 || size2 == 0) return 0; // the start position of substring in original string int start1 = -1; int start2 = -1; // the longest length of common substring int longest = 0; // record how many comparisons the solution did; // it can be used to know which algorithm is better int comparisons = 0; for (int i = 0; i < size1; ++i) { for (int j = 0; j < size2; ++j) { // find longest length of prefix int length = 0; int m = i; int n = j; while(m < size1 && n < size2) { ++comparisons; if (str1[m] != str2[n]) break; ++length; ++m; ++n; } if (longest < length) { longest = length; start1 = i; start2 = j; } } } #ifdef IDER_DEBUG cout<< "(first, second, comparisions) = (" << start1 << ", " << start2 << ", " << comparisons << ")" << endl; #endif return longest; }
该解法的思路就如前所说,以字符串中的每个字符作为子串的端点,判定以此为开始的子串的相同字符最长能达到的长度。其实从表层上想,这个算法的复杂度应该只有 O(n2) 因为该算法把每个字符都成对相互比较一遍,但关键问题在于比较两个字符串的效率并非是 O(1) ,这也导致了实际的时间复杂度应该是满足 Ω(n2) 和 O(n3) 。
动态规划法 – 空间换时间
有了一个解决问题的方法是一件很不错的事情了,但是拿着上边的解法回答面试题肯定不会得到许可,面试官还是会问有没有更好的解法呢?不过上述解法虽然不是最优的,但是依然可以从中找到一个改进的线索。不难发现在子串比较中有很多次重复的比较。
比如再比较以 i 和 j 分别为起始点字符串时,有可能会进行 i+1 和 j+1 以及 i+2 和 j+2 位置的字符的比较;而在比较 i+1 和 j+1 分别为起始点字符串时,这些字符又会被比较一次了。也就是说该问题有非常相似的子问题,而子问题之间又有重叠,这就给动态规划法的应该提供了契机。
暴力解法是从字符串开端开始找寻,现在换个思维考虑以字符结尾的子串来利用动态规划法。
假设两个字符串分别为s和t, s[i] 和 t[j] 分别表示其第 i 和第 j 个字符(字符顺序从 0 开始),再令 L[i, j] 表示以 s[i] 和 s[j] 为结尾的相同子串的最大长度。应该不难递推出 L[i, j] 和 L[i+1,j+1] 之间的关系,因为两者其实只差 s[i+1] 和 t[j+1] 这一对字符。若 s[i+1] 和 t[j+1] 不同,那么 L[i+1, j+1] 自然应该是 0 ,因为任何以它们为结尾的子串都不可能完全相同;而如果 s[i+1] 和 t[j+1] 相同,那么就只要在以 s[i] 和 t[j] 结尾的最长相同子串之后分别添上这两个字符即可,这样就可以让长度增加一位。合并上述两种情况,也就得到 L[i+1,j+1]=(s[i]==t[j]?L[i,j]+1:0) 这样的关系。
最后就是要小心的就是临界位置:如若两个字符串中任何一个是空串,那么最长公共子串的长度只能是 0 ;当 i 为 0 时, L[0,j] 应该是等于 L[-1,j-1] 再加上 s[0] 和 t[j] 提供的值,但 L[-1,j-1] 本是无效,但可以视 s[-1] 是空字符也就变成了前面一种临界情况,这样就可知 L[-1,j-1]==0 ,所以 L[0,j]=(s[0]==t[j]?1:0) 。对于 j 为 0 也是一样的,同样可得 L[i,0]=(s[i]==t[0]?1:0) 。
最后的算法代码如下:
int longestCommonSubstring_n2_n2(const string& str1, const string& str2) { size_t size1 = str1.size(); size_t size2 = str2.size(); if (size1 == 0 || size2 == 0) return 0; vector<vector<int> > table(size1, vector<int>(size2, 0)); // the start position of substring in original string int start1 = -1; int start2 = -1; // the longest length of common substring int longest = 0; // record how many comparisons the solution did; // it can be used to know which algorithm is better int comparisons = 0; for (int j = 0; j < size2; ++j) { ++comparisons; table[0][j] = (str1[0] == str2[j] ? 1 :0); } for (int i = 1; i < size1; ++i) { ++comparisons; table[i][0] = (str1[i] == str2[0] ? 1 :0); for (int j = 1; j < size2; ++j) { ++comparisons; if (str1[i] == str2[j]) { table[i][j] = table[i-1][j-1]+1; } } } for (int i = 0; i < size1; ++i) { for (int j = 0; j < size2; ++j) { if (longest < table[i][j]) { longest = table[i][j]; start1 = i-longest+1; start2 = j-longest+1; } } } #ifdef IDER_DEBUG cout<< "(first, second, comparisions) = (" << start1 << ", " << start2 << ", " << comparisons << ")" << endl; #endif return longest; }
算法开辟了一个矩阵内存来存储值来保留计算值,从而避免了重复计算,于是运算的时间复杂度也就降至了 O(n2) 。
动态规划法优化 – 能省一点是一点
仔细回顾之前的代码,其实可以做一些合并让代码变得更加简洁,比如最后一个求最长的嵌套for循环其实可以合并到之前计算整个表的 for 循环之中,每计算完 L[i,j] 就检查它是的值是不是更长。当合并代码之后,就会发现内部循环的过程重其实只用到了整个表的相邻两行而已,对于其它已经计算好的行之后就再也不会用到,而未计算的行曽之前也不会用到,因此考虑只用两行来存储计算值可能就足够。
于是新的经过再次优化的算法就有了:
int longestCommonSubstring_n2_2n(const string& str1, const string& str2) { size_t size1 = str1.size(); size_t size2 = str2.size(); if (size1 == 0 || size2 == 0) return 0; vector<vector<int> > table(2, vector<int>(size2, 0)); // the start position of substring in original string int start1 = -1; int start2 = -1; // the longest length of common substring int longest = 0; // record how many comparisons the solution did; // it can be used to know which algorithm is better int comparisons = 0; for (int j = 0; j < size2; ++j) { ++comparisons; if (str1[0] == str2[j]) { table[0][j] = 1; if (longest == 0) { longest = 1; start1 = 0; start2 = j; } } } for (int i = 1; i < size1; ++i) { ++comparisons; // with odd/even to swith working row int cur = ((i&1) == 1); //index for current working row int pre = ((i&1) == 0); //index for previous working row table[cur][0] = 0; if (str1[i] == str2[0]) { table[cur][0] = 1; if (longest == 0) { longest = 1; start1 = i; start2 = 0; } } for (int j = 1; j < size2; ++j) { ++comparisons; if (str1[i] == str2[j]) { table[cur][j] = table[pre][j-1]+1; if (longest < table[cur][j]) { longest = table[cur][j]; start1 = i-longest+1; start2 = j-longest+1; } } else { table[cur][j] = 0; } } } #ifdef IDER_DEBUG cout<< "(first, second, comparisions) = (" << start1 << ", " << start2 << ", " << comparisons << ")" << endl; #endif return longest; }
跟之前的动态规划算法代码相比,两种解法并没有实质的区别,完全相同的嵌套 for 循环,只是将检查最长的代码也并入其中,然后 table 中所拥有的行也只剩下 2 个。
此解法的一些技巧在于如何交换两个行数组作为工作数组。可以交换数组中的每个元素,异或交换一对指针。上边代码中所用的方法类似于后者,根据奇偶性来决定那行数组可以被覆盖,哪行数组有需要的缓存数据。不管怎么说,该算法都让空间复杂度从 O(n2) 减少到了 O(n) ,相当有效。
动态规划法再优化 – 能用一点就只用一点
最长公共子串问题的解法优化到之前的模样,基本是差不多了, Wikipedia 上对于这个问题给出的解法也就到上述而已。但思考角度不同,还是有意外的惊喜的。不过要保持算法的时间复杂度不增加,算法的基本思路方针还是不能变的。
下图是上述动态规划的计算过程的示例:

在填充这张表的过程中,算法是从上往下一行一行计算,然后每行是从左往右。对于每一格,要知道它左上格是什么值,这就导致需要保留一整行的数据信息。但如果只针对一格看,它需要知道的只是左上格,而它的左上格又只要知道左上格的左上格就足够了,于是就是一个对角线的路径。
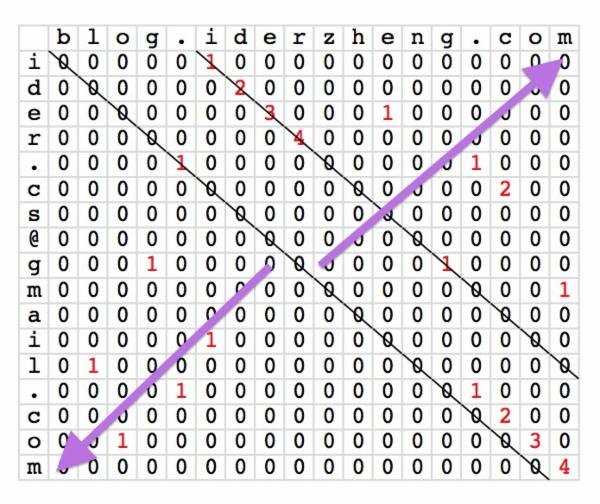
而如若按对角线为行,一行行计算的话,其实就只需要缓存下一个数据就可以将对角线上的格子填充完毕。从字符串上讲,就是偏移一个字符串的头,然后跟另一个字符串比较看在如此固定的位置下能找到最长的公共子串是多长。
解释可能有点不清,程序员可能还是从代码更能看懂算法的意思:
int longestCommonSubstring_n2_1(const string& str1, const string& str2) { size_t size1 = str1.size(); size_t size2 = str2.size(); if (size1 == 0 || size2 == 0) return 0; // the start position of substring in original string int start1 = -1; int start2 = -1; // the longest length of common substring int longest = 0; // record how many comparisons the solution did; // it can be used to know which algorithm is better int comparisons = 0; for (int i = 0; i < size1; ++i) { int m = i; int n = 0; int length = 0; while(m < size1 && n < size2) { ++comparisons; if (str1[m] != str2[n]) { length = 0; } else { ++length; if (longest < length) { longest = length; start1 = m-longest+1; start2 = n-longest+1; } } ++m; ++n; } } // shift string2 to find the longest common substring for (int j = 1; j < size2; ++j) { int m = 0; int n = j; int length = 0; while(m < size1 && n < size2) { ++comparisons; if (str1[m] != str2[n]) { length = 0; } else { ++length; if (longest < length) { longest = length; start1 = m-longest+1; start2 = n-longest+1; } } ++m; ++n; } } #ifdef IDER_DEBUG cout<< "(first, second, comparisions) = (" << start1 << ", " << start2 << ", " << comparisons << ")" << endl; #endif return longest; }
算法中两个 for 循环都嵌套着一个 while 循环,但实际时间复杂度是跟原来一致依然是 O(n2) 而不是翻倍(当然翻倍了 O 还是一样的),因为每个 for 其实都只遍历原表的一半区域而已。
看看这两个 for 实在是不欢喜,循环内的代码除了头两行对m和n的初始化值不同以外,其它代码全都一模一样。对于这种冗余的代码是程序员极为不满的,所以我们应该合并它们,一种方法就是把代码封装到方法中,在两个 for 循环里调用方法即可。不过我用来一些非常规的技巧和 C++ 的引用类型特性来合并两个 for 循环:
int longestCommonSubstring_n2_1(const string& str1, const string& str2) { size_t size1 = str1.size(); size_t size2 = str2.size(); if (size1 == 0 || size2 == 0) return 0; // the start position of substring in original string int start1 = -1; int start2 = -1; // the longest length of common substring int longest = 0; // record how many comparisons the solution did; // it can be used to know which algorithm is better int comparisons = 0; int indices[] = {0, 0}; int sizes[] = {size1, size2}; // shift strings to find the longest common substring for (int index = 0; index < 2; ++index) { indices[0] = 0; indices[1] = 0; // i is reference to the value in array int &i = indices[index]; int size = sizes[index]; // this is tricky to skip comparing strings both start with 0 for second loop i = index; for (; i < size; ++i) { int m = indices[0]; int n = indices[1]; int length = 0; // with following check to reduce some more comparisons if (size1-m <= longest || size2-n <= longest) break; while(m < size1 && n < size2) { ++comparisons; if (str1[m] != str2[n]) { length = 0; } else { ++length; if (longest < length) { longest = length; start1 = m-longest+1; start2 = n-longest+1; } } ++m; ++n; } } } #ifdef IDER_DEBUG cout<< "(first, second, comparisions) = (" << start1 << ", " << start2 << ", " << comparisons << ")" << endl; #endif return longest; }
在上述代表中,有一个语句 if (size1-m <= longest || size2-n <= longest) 会 break 循环,其中的条件其实是检查剩下子串长度是否小于或等于跟最长公共子串的长度,如果是那么剩下的可定不足以构建出更长的子串。这对于当一个字符串是另一个字符串的子串是可以减少很多的比较,这也是之前在提到:在幸运的时候运算时间复杂度可以有 O(n) 。对于这样的微小优化也可以在之前的几个算法中使用。
测试案例及结果
最后贴上一些测试随机生成的测试案例已经调用每个算法所得到的结果和运算需要的“量”。 打包的所有代码都可以在这里下载 ,欢迎测试并给出一些建议和优化方案。
YXXXXXY (7) YXYXXYYYYXXYYYYXYYXXYYXXYXYYYYYYXYXYYXYXYYYXXXXXX (49) (first, second, comparisions) = (0, 42, 537) 6 (first, second, comparisions) = (0, 42, 343) 6 (first, second, comparisions) = (0, 42, 343) 6 (first, second, comparisions) = (0, 42, 316) 6 XXYXYYYXXYXYYYYXYXYYYXYYYYYXYX (30) XYY (3) (first, second, comparisions) = (3, 0, 127) 3 (first, second, comparisions) = (3, 0, 90) 3 (first, second, comparisions) = (3, 0, 90) 3 (first, second, comparisions) = (3, 0, 12) 3 XXYXXYYYXYXYYXXYYYYYXXYXXXYXXYXYXXXXYXXYYYXYYXYXYXXXYYXXXYYXYYXYXYXYXXXXXXXXXYXXXX (82) YYYYYXYYYXYYXXXYYYXXYYXXYXXXYYYYYYYYXXYXYYYYXYXYYXYX (52) (first, second, comparisions) = (5, 41, 7911) 9 (first, second, comparisions) = (5, 41, 4264) 9 (first, second, comparisions) = (5, 41, 4264) 9 (first, second, comparisions) = (18, 20, 4183) 9 X (1) XXYYYYYYXYYXYXXXYYXXXYYYYYYXYYYXYYXXYYYYXXXYXXXXXXXYXYXYXYYYYYYYYXYXYXXX (72) (first, second, comparisions) = (0, 0, 72) 1 (first, second, comparisions) = (0, 0, 72) 1 (first, second, comparisions) = (0, 0, 72) 1 (first, second, comparisions) = (0, 0, 1) 1 (0) XYXXYYYXXXYYXXYYYYXXYYYXYYYXXXXXYYXXYXYXXXYY (44) 0 0 0 0
从见过可以看出所有方法的计算应该都是正确并且一致的,也不难看出对于经典的动态规划的两个方法需要的比较时间正式两个字符串长度的乘积。另一个问题如果不旦旦只有长度而要找出最长子串来,算法给出的答案就有可能不同,因为两个字符串中可能存在多个不同的最长公共子串。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

