Taxi Trajectory Prediction竞赛冠军访谈:深度学习的"非主流"应用
出租车线路预测(Taxi Trajectory Prediction) 是Kaggle 2015 ECML PKDD 机器学习会议的两场竞赛中的第一场。一个 团队使用他们在MILA实验室开发的深度学习工具在竞赛中赢得了第一名。在这篇文章中,他们分享了许多关于这次竞赛的情况和他们获胜的方式。
想了解2015 ECML PKDD 出租车竞赛的情况,可以 点击这里 阅读关于“Blue Taxi”的文章,Blue Taxi是 Taxi Trip Time Prediction 竞赛的第三名。
来自381个团队的459位数据专家针对预测出租车乘客可能在哪下车进行竞赛
基本信息
目标任务特别简单:我们将要通过出租车的起点(GPS定位点)和一些其他的元数据信息(日期,时间,出租车号码,客户信息)来预测出租车的目的地。
所有的训练数据都是发生在2013-2014年波尔图出租车的行驶路线,涉及442辆出租车大概170万的路线信息。你可以在Kaggle的首页上找到这次竞赛的信息, 点击这里 。
在继续讲解之前,先来看看2个视频,是使用我们设计的模型对两辆出租车行驶路线的预测情况。
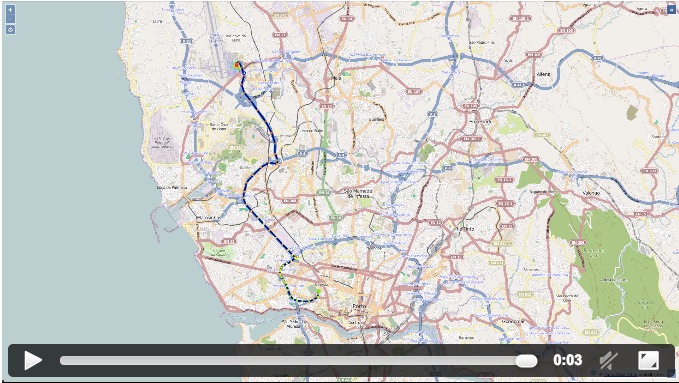

用我们最优的模型预测目的地,测试车辆按照我们预测的地点行驶。第一个视频中,我们可以很清楚的看到我们设计的模型已经学习到了机场的位置。
在数据方面你们遇到过哪些主要困难?
有好几种,例如:
- 出租侧轨迹是可变长度序列,最短的时候是0(比如当数据丢失的时候),最长的时候大概是5000GPS点(相当于20个小时的车程!)。
- 数据的特征是非常多样化的:尤其是特定的元数据是离散的(出租车号码和客户id),而其他的则是高度结构化的(日期,时间),还有GPS的轨迹是连续的坐标序列。
- 作为现实世界的数据,数据之间有诸多矛盾,比如行车时间持续多达16个小时,或者是出租车开到了伊朗:)。伊朗的坐标点肯定是由错误的GPS校准产生的。总的来说,因为不精确的GPS定位,训练轨迹将会有许多噪声。
在参加这次挑战之前你们都有什么专业背景?
我们三个是 蒙特利尔学习算法研究所 (MILA,前身是LISA)的学生,它是由Yoshua Bengio教授领导的专门从事深度神经网络研究的实验室。我们两个是实习生(Alex和Étienne),计算机科学专业,Alexandre是一年级博士生,在机器学习(ML)方面有更多的专业知识。这次竞赛中所使用到的机器学习技术、技巧和工具都是我们在MILA实验室开发的,用实验室开发的编程框架(Theano, Blocks)实现了独特的深度神经网络。
有没有什么领域知识助你们成功?
没有,我们之前没有任何关于波尔图和它那出租车的领域知识。
你们是怎么在Kaggle开始竞赛的?
对我们三个来说,这是我们第一次(庄重地)参加Kaggle的竞赛。作为MILA实验室的学生,我们更喜欢尝试一些“非主流”的深度学习(DL)技术,而不是已经成熟的深度学习技术(比如计算机视觉,NLP,语音技术)。
技术方面
你们一般化的方法是什么?
我们想设计一个全能的机器学习方法,尽可能减少手工操作,理想情况下我们希望达到无需预处理或者特征提取,无需后置处理并且不用模型组合。
我们尝试了几种方法,全部都是基于神经网络的。结果是复杂的模型表现得并没有简单模型那么出色,这是非常奇怪的。
能讲讲你们取胜的那个模型吗?
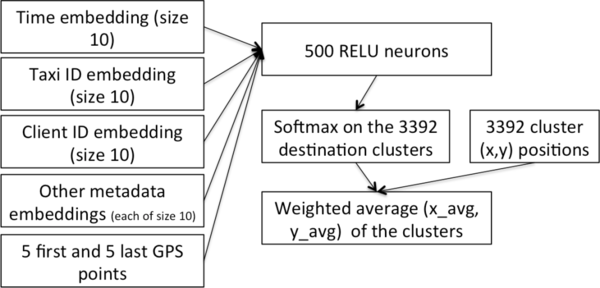
图1:我们取胜模型的架构图。我们尝试用递归神经网络替换MLP,但是表现并不是很好。更深层的网络也同样没有提升效果。
我们取胜的模型架构是基于 多层感知器 (MLP)的,感知器是一种最简单的神经网络架构。更确切地说,感知器是由一个输入层(输入大小是固定的),一个或多个隐藏层(计算输入数据)和一个输出层(输出预测结果)组成。
当然,我们需要调整一下MLP让它适用于这个任务:
- 轨迹是可变长度的,而MLP的输入是定长的。我们为此做如下修改,只用前5个和后5个轨迹数据点作为MLP的输入。结果表明,这些数据点确实是轨迹最重要的部分,而中间部分的数据点并没有这么重要。
- 考虑到元数据(时间和客户信息),我们使用了一种在自然语言模型中训练文字嵌入广泛使用的方式。我们使用这种方式(当然不是嵌入文字)学习为每条元数据值(一天中的第几刻钟,一年中的第几周,客户ID等)嵌入向量,然后将这些嵌入数据作为MLP的附属输入。
- 最开始我们尝试直接预测输出坐标(x,y),但是实际上,我们采用另外一种方式获得了显著的效果,这种方式增加了一些预处理过程。更确切地说,我们首先在所有训练轨迹的目的地上使用聚类算法得到了大概3392个热门目的地数据点。MLP的倒数第二层是一个softmax,它用来预测这3392个数据点成为出租车目的地的概率。因为这个任务是要预测单个目的地点,所以我们计算这3392个目标的平均值,然后用softmax层返回的概率作为权值。
随后我们训练模型将预测和实际地点的误差最小化。我们使用了随机梯度下降而且我们还将继续使用。
你们对数据最深刻的了解是什么?

图2:所有训练轨迹的GPS数据点的热点图。可以注意到,这里并没有印上地图,只有GPS数据点,这揭露了波尔图的公路网。
从可视化角度看,这个挑战很有意思。在竞赛的开始,我们计算出了波尔图出租车最常去的区域的热点图(图2)。正如你所看到的,我们可以很清晰的认出主干公路、机场、火车站、市中心和郊区。这些发现让我们觉得我们应该为模型提供相当于数据分布的前期数据。这让我们考虑将目的地聚类。
你们对你们的任何发现感到惊讶吗?
只是出于好奇心,我们在嵌入数据的时候使用 t-SNE ,我们可以将每条元数据转化成2维空间中的值(原始的嵌入空间有10个维度),这为我们理解每条元数据值如何影响预测提供了良好的视觉观察(如果一个人想要在数量上评估单条元数据的重要性,那么他可以只用这一个特定的元数据作为训练模型的输入)。特别地,图3和图4分别显示了嵌入每天第几刻钟和每年第几周作为附属输入的预测结果。

图3:在出租车行驶了的时间里,嵌入了每小时中的每刻钟的数据得到了以t-SNE 2D形式显示的预测结果(一天中有96刻钟,所以有96个点,每个点代表了特定的刻钟时间)。上图表明,每个刻钟数据本身都很重要。
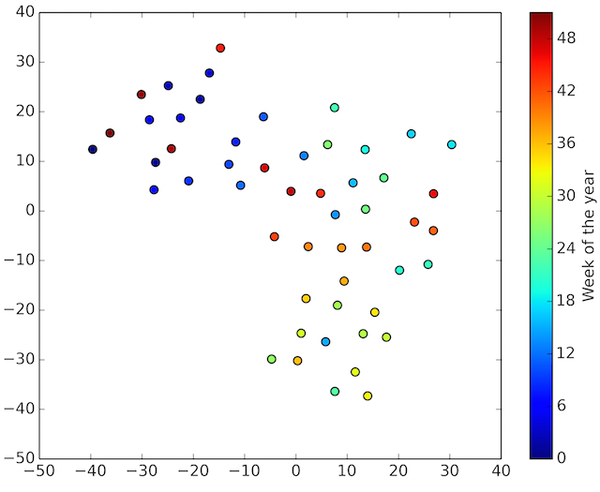
图4:在出租车行驶了的时间里,嵌入了每年中的每周数据得到了以t-SNE 2D形式显示的预测结果(一年中有52周,所以有52个点,每个点代表了特定的周)。
你们是如何处理数据的?
训练数据包括:完成轨迹,而测试数据集只包含局部轨迹。这意味着GPS数据序列在输入到网络之前需要剪枝。理想的解决办法是去掉所有在不同时间的轨迹信息。这样会有1亿条训练实例,对它们进行shuffle操作,我们就可以更好地发挥随机梯度下降的性能,但是这样做的代价可能太大了。所以我们随机地循环遍历170万条训练实例,然后动态地随机去掉100条数据。
你们使用什么工具?
我们使用在MILA实验室开发的库文件,也就是 Theano (一个类似numpy的库文件,用来加速GPU处理)和 Blocks (可以说是建立在Theano之上的一个近现代深度学习框架)。我们非常感谢它们的开发者们。
我们的源码和运行说明可以在我们的github上下载, 点击这里 。
在这次竞赛中你们是怎么安排时间的?
正如前面所说,我们的实现方法只做了很少的特征提取工作。我们在通过数据可视化理解数据上花了少量时间,我们大多数时间都在思考如何设计神经网络架构并且如何使用Blocks去实现它们。
用你们的方法训练数据和预测各需要多少时间?
我们的模型是使用随机梯度下降训练的,意味着它需要逐个考虑数据集中的每条数据——或者更确切地说,每批200条训练数据——许多次。比如,在一次迭代中,遍历所有的数据所花的时间取决于模型的复杂度。用我们最好的模型,在GTX 680上做一次迭代需要几个小时,训练它则要半天。
你们还尝试过哪些模型?
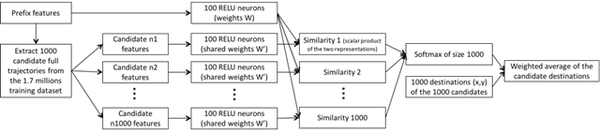
图5:内存式网络。RELU层可以由递归神经网络代替。在我们的实验中,候选轨迹是随机抽取的,但是手工编码的相似度函数也可以使用。
我们尝试了更为复杂的神经网络架构,比如递归神经网络和一些与内存网络相关的架构。令人吃惊的是,将所有轨迹作为输入的递归架构并没有改进预测结果。内存网络架构(图5)是基于学习相似度函数的,相似度函数从训练数据中提取候选轨迹然后度量它们的权重。
Bios
 Alexandre de Brébisson是蒙特利尔MILA实验室的博士生,师从Pascal Vincent教授和Yoshua Bengio教授。
Alexandre de Brébisson是蒙特利尔MILA实验室的博士生,师从Pascal Vincent教授和Yoshua Bengio教授。
Étienne Simon 是ENS Cachan计算机科学专业的学生,目前是蒙特利尔MILA实验室的实习生,师从Yoshua Bengio教授。
Alex Auvolat 是ENS Paris计算机科学专业的学生,目前是蒙特利尔MILA实验室的实习生,师从Pascal Vincent教授和Yoshua Bengio教授。
英文原文: Taxi Trajectory Winners' Interview: 1st place, Team (译者/刘翔宇 审校/刘帝伟、朱正贵 责编/周建丁)
关于译者: 刘翔宇,中通软开发工程师,关注机器学习、神经网络、模式识别。
- 如果您对深度学习有更多的见解和心得希望分享,请给小编发送邮件:zhoujd@csdn.net。
- 如果您想了解更多的深度学习相关产品,请关注 CSDN人工智能产品库 。
- 更多人工智能技术分享与交流,请加入CSDN 人工智能技术交流QQ群,群号:465538150。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

