SequoiaDB(巨杉数据库)成为国内首家Spark认证数据库
近日,Spark的官方博客中刊登了其全球战略合作伙伴SequoiaDB发布的 技术博客 ,介绍SequoiaDB对于Spark的整合以及SequoiaDB+Spark的解决方案。目前,SequoiaDB也成为了 Spark官方认证 的全球合作伙伴和授权的Spark提供商之一,全球目前只有14家企业获得了该认证,其中包括了IBM、Oracle、SAP和华为这些行业巨头,SequoiaDB也是国内唯一获得该认证的数据库。
Spark 是新一代的大数据分析处理架构
如今业界最具代表性的大数据技术为Hadoop,也是目前大部分的大数据分析处理所使用的架构之一。Hadoop并不能适用于所有场景,尤其是在海量数据并对实时交互性需求较高的企业,因为其使用的MapReduce架构,需要将每次临时计算得出的结果写回磁盘,下次需要的时候需要再次从磁盘读取。这种方式会造成数据运算的效率较低。
Spark则使用内存计算的结构,在计算性能上相比Hadoop有了巨大的提高。同时相比于如今Hadoop复杂繁琐的生态系统, Spark框架为批处理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),机器学习(MLlib),图计算(GraphX)提供一个统一的数据处理平台,使用更方便统一。目前,Spark也成为了Apache的顶级Project,属于Apache力捧的云计算、大数据架构,也是目前世界上最大的开源项目之一。
现在,越来越多的企业也开始使用Spark架构,Spark极有可能成为替代Hadoop的下一代云计算、大数据核心技术。
SequoiaDB 是 Spark 底层数据源首选
SequoiaDB是一款文档型的分布式NoSQL数据库,其也是国内第一款完全自主研发、并且敢于开源的NoSQL数据库产品。SequoiaDB JSON对象式的存储结构,带来灵活的数据结构;分布式的架构,使得存储容量可以动态调整;高可用和读写分离则可以使得数据读写和离线数据分析分离,提升使用的效率;原生的Spark-SequoiaDB Connector 连接器让Spark与SequoiaDB完美对接。
以上这些特性都让SequoiaDB可以成为Spark数据源的首选。

“SequoiaDB 是一款 NoSQL 数据库,其可以在不同的物理节点之间对数据进行复制,并且允许用户指定使用哪一个数据备份。 SequoiaDB 允许在同一集群同时运行数据分析和数据操作负载,并且保证最小的 I/O 和 CPU 使用率。 ”
“Spark-SequoiaDB Connector 是 Spark 的数据源,可以让用户能够使用 SparkSQL 对 SequoiaDB 的数据库集合中的数据进行读写。连接器用于 SequoiaDB 与 Spark 的集成,将无模式的存储模型、动态索引以及 Spark 集群的优势有机的结合起来。 ”—— 引自《 Spark 官方 Blog 》
SequoiaDB+Spark 打造一体化大数据平台
“Apache Spark 和 SequoiaDB 的联合解决方案,使得用户可以搭建一个在同一个物理集群中支持多种类型负载(如, SQL 语句和流处理)的统一平台。 ”
SequoiaDB+Spark的一体化大数据平台,通过SequoiaDB与Spark架构的结合,实现了从数据的底层存储,到数据的处理分析,最终实现数据展现的一体化平台。平台打通了数据从存储到最终展现的全过程,不仅大大降低了用户部署、使用的成本,简化了整个系统的操作和维护,同时更通过平台的一体化整合,大大减少了因为不同的产品、架构之间对接、通信等操作造成的系统效率和数据安全性降低。此外,Spark的SparkSQL解析引擎,结合非结构化存储的SequoiaDB,帮助现有的SQL语句比较熟悉的用户,能在基本不修改业务操作的情况下,顺利的对接上SequoiaDB+Spark平台。
目前,一体化的大数据平台,已经在各个行业的大数据应用中开始普及。我们也举一个系统的例子来做说明。
SequoiaDB+Spark 实战案例:产品精准推荐系统
这一系统,使用分布式的SequoiaDB,将所有用户的交易信息、操作信息进行了存储。这一存储的量级就已经达到了近PB级别。
之后,基于这些历史交易信息,平台就可以通过对这些数据的分析,对每个用户的交易行为进行预测,对用户进行分类和建模,最终根据分析的结果向每个用户推荐最适合的理财产品。
当用户模型系统通过分析所有的历史数据和日志,计算出需要推荐的产品时,这些用户特征也会作为这个用户的一个标签写入这个用户的信息中。这些新加入的用户标签,可以帮助前台的员工和产品推荐系统快速的分辨出每个顾客的兴趣和消费倾向。
部署了这套系统后,该金融产品的推荐成功率提升了10倍以上。
系统架构图
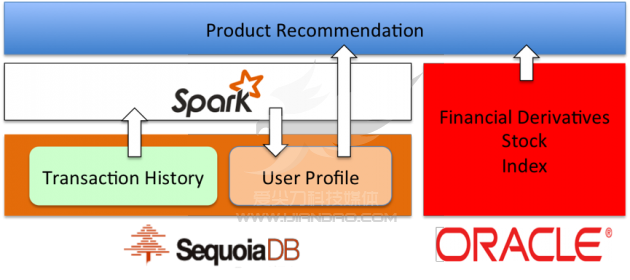
结束语
Spark将是大数据、云计算未来将会占据主流的计算架构之一。如今,国内唯一一款开源NoSQL数据库与Spark进行深度结合,不仅体现出国内大数据技术和产品已经具备与国际顶尖产品齐头并进的能力,也体现出了Spark这一新兴的大数据技术对于中国这一市场的重视,在产品发展初期就选择与中国的厂商进行全面的合作。此外,通过Spark这一技术在国内得到了较多的应用,可以看到中国目前企业对于大数据技术相比于其他方面,开放度和接受度更高,更愿意接收更新的技术,这对于国内的大数据技术、产品也是好消息。
Databricks 原文链接:
https://databricks.com/blog/2015/08/03/guest-blog-sequoiadb-connector-for-apache-spark.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

