SequoiaDB的Apache Spark连接器
为什么选择Spark?
SequoiaDB是一款NoSQL数据库,其可以在不同的物理节点之间对数据进行复制,并且允许用户指定使用哪一个数据备份。SequoiaDB允许在同一集群同时运行数据分析和数据操作负载,并且保证最小的I/O和CPU使用率。
Apache Spark和SequoiaDB的联合解决方案,使得用户可以搭建一个在同一个物理集群中支持多种类型负载(如,SQL语句和流处理)的统一平台。
Spark-SequoiaDB Connector,让SequoiaDB与Spark完美结合
Spark-SequoiaDB Connector是Spark的数据源,可以让用户能够使用SparkSQL对SequoiaDB的数据库集合中的数据进行读写。连接器用于SequoiaDB与Spark的集成,将无模式的存储模型、动态索引以及Spark集群的优势有机的结合起来。
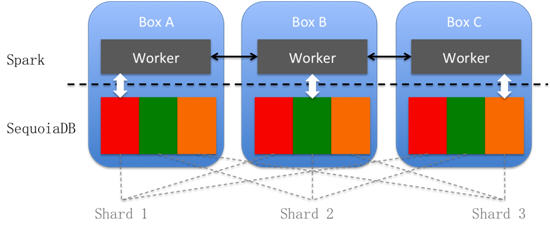
Spark与SequoiaDB可以在同一个物理环境中安装,也可以安装在不同的集群中。Spark-SequoiaDB Connector将查询的条件下压至SequoiaDB,获取符合查询条件的记录。这一优化使得对操作型数据源的分析无需在SequoiaDB和Spark之间再使用ETL。
以下是部分示例代码,有关如何在Spark-SequoiaDB 连接器中使用SparkSQL:
scala> sqlContext.sql("CREATE temporary table org_department ( deptno string, deptname string, mgrno string, admrdept string, location string ) using com.sequoiadb.spark OPTIONS ( host 'host-60-0-16-2:50000', collectionspace 'org', collection 'department', username 'sdb_reader', password 'sdb_reader_pwd')")res2: org.apache.spark.sql.DataFrame = []
scala> sqlContext.sql("CREATE temporary table org_employee ( empno int, firstnme string, midinit string, lastname string, workdept string, phoneno string, hiredate date, job string, edlevel int, sex string, birthdate date, salary int, bonus int, comm int ) using com.sequoiadb.spark OPTIONS ( host 'host-60-0-16-2:50000', collectionspace 'org', collection 'employee', username 'sdb_reader', password 'sdb_reader_pwd')")res3: org.apache.spark.sql.DataFrame = []
scala> sqlContext.sql("select * from org_department a, org_employee b where a.deptno='D11'").collect().take(3).foreach(println)
[D11,MANUFACTURING SYSTEMS,000060,D01,null,10,CHRISTINE,I,HAAS,A00,3978,null,PRES ,18,F,null,152750,1000,4220]
[D11,MANUFACTURING SYSTEMS,000060,D01,null,20,MICHAEL,L,THOMPSON,B01,3476,null,MANAGER ,18,M,null,94250,800,3300]
[D11,MANUFACTURING SYSTEMS,000060,D01,null,30,SALLY,A,KWAN,C01,4738,null,MANAGER ,20,F,null,98250,800,3060]
…
案例1:交易历史存储系统
Spark+SequoiaDB的联合解决方案帮助企业从数据中发现和获取更多价值。我们也举一些金融行业应用的例子,某银行使用了SequoiaDB+Spark的方案作为其新的交易历史信息存储系统。
在过去的数十年中,大部分银行都一直使用大型机作为其核心的银行业务系统支持。大型机的技术局限性使得超过一年之前的历史交易数据就需要从大型机上移出而转存在其他的磁盘(磁带)中进行保存。
然而,如今,因为移动互联网和网上银行的兴起,银行用户对于服务的要求大大的超过了从前,这也带来了更多的需求。为了让客户更好的体验银行的服务,让产品服务更有竞争力,各大银行也开始推出让客户能快速的查询历史记录(包括1年以前的历史记录)等多项改进的服务。
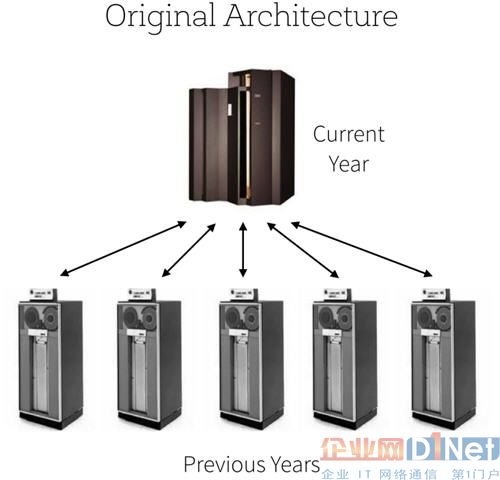
传统的存储系统架构
通过使用SequoiaDB,该银行在数据库的50个物理节点,使用近1PB的空间,存储了所有用户长达15年的历史数据。这一新系统让用户可以轻松的获取其所有的交易历史,无论展现在移动客户端或者网页端。
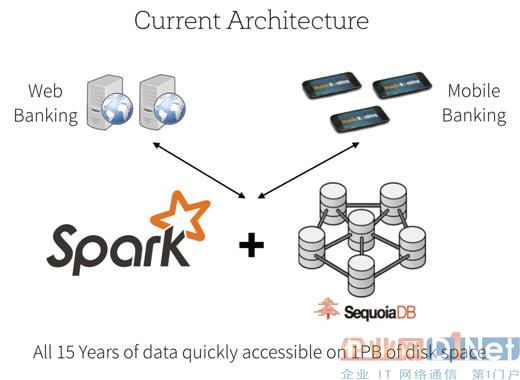
现行新存储架构
案例2:Spark+SequoiaDB 的产品精准推荐系统在之前的案例中,我们已经将所有的用户历史交易数据都存储在了数据库当中,基于这些历史交易信息,我们也可以通过对这些数据的分析,对每个用户的交易行为进行预测,对用户进行分类和建模,最终根据分析的结果向每个用户推荐最适合的理财产品。
当用户模型系统通过分析所有的历史数据和日志,计算出需要推荐的产品时,这些用户特征也会作为这个用户的一个标签写入这个用户的信息中。这些新加入的用户标签,可以帮助前台的员工和产品推荐系统快速的分辨出每个顾客的兴趣和消费倾向。部署了这套系统后,该行的金融产品的推荐成功率提升了10倍以上。
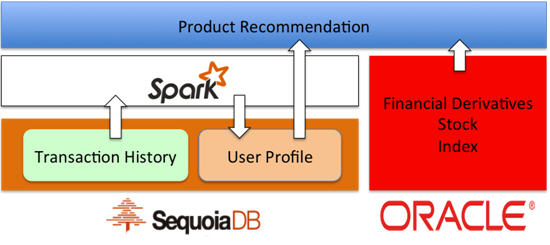
系统架构图
未来与Spark结合的计划
在实际合作中,我们发现我们很多的金融行业用户都有兴趣使用流处理(反洗钱和高频交易),也有很大兴趣在于交互式SQL处理(政府的监管系统)。我们计划进一步对SequoiaDB的Spark组件增加功能和提升稳定性,比如使得SparkSQL能支持标准的SQL2003。
作者:SequoiaDB联合创始人和CTO王涛先生。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

