PLT:说说Evaluation strategy
Brief
在学习方法/函数时,我们总会接触到 按值传值 和 引用传值 两个概念。像C#是按值传值,但参数列表添加了ref/out后则是引用传值,但奇怪的事出现了
namespace Foo{ class Bar{ public String Msg{get;set;} } class Program{ public static void main(String[] args){ Bar bar1 = new Bar(); bar1.Msg = "Hey, man!"; UpdateProp(bar1); Console.WriteLine(bar1.Msg); // Bye! } static void UpdateProp(Bar bar){ bar.Msg = "Bye!"; } } }
Q:UpdateProp明明是按值传值,对bar的修改怎么会影响到main中的bar1呢?
延伸Q:到底什么是按值传值、引用传值?
为了解答上述疑问,我们就需要理解求值策略了!
What is evaluation strategy?
Evaluation Strategy其实就是定义函数/方法的实参应该在何时被计算,并且以什么类型的值作为实参传入到函数/方法内部。
A programming language uses an evaluation strategy to determine when to evaluate the argument(s) of a function call (for function, also read: operation, method, or relation) and what kind of value to pass to the function.
以时间为维度,那么就有以下三种类别的求值策略:
1. Strict/Eager Evaluation,在执行函数前对实参求值(实质上是在构建函数执行上下文前)。
2. Non-strict Evaluation(Lazy Evaluation),在执行函数时才对实参求值。
3. Non-deterministic,实参求值时机飘忽。
另外注意的是,大部分编程语言采用不止一种求值策略。
Strict/Eager evaluation
现在绝大部分语言均支持这类求值策略,而我们也习以为常,因此当如Linq、Lambda Expression等延迟计算出现时我们才如此兴奋不已。
但Strict/Eager Evaluation下还包括很多具体的定义,下面我们来逐个了解。
Applicative Order (Evaluation)
Applicative Order又名leftmost innermost,中文翻译为“应用序列”,实际运算过程和Post-order树遍历算法类似,必须先计算完叶子节点再计算根节点,因此下面示例将导致在计算实参时就发生内存溢出的bug。
// function definitions function foo(){ return false || foo() } function test(a, f){ console.log(a + f) } // main thread,陷入foo函数无尽的递归调用中 test(1, foo())
Call-by-value
按值传值也就是我们接触最多的一种求值策略,实际运算过程是对实参进行克隆,然后将副本赋值到参数变量中。
function foo(val){ val = 3 } var bar = 1 foo(bar) console.log(bar) // 显示1 // 函数作用域中对实参进行赋值操作,并不会影响全局作用域的变量bar的值。
那如Brief中C#那种情况到底是啥回事呢?其实问题在于 到底要克隆哪里的“值”了,对于Bar bar = new Bar()而言,bar对应的内存空间存放的是指向 new Bar()内存空间的指针,而因此克隆的就是指针而不是 new Bar()这个对象,也就是说克隆的是实参对应的内存空间存放的“值”。假如我们将Bar定义为Struct而不是Class,则明白C#确实遵循Call-by-value策略。
namespace Foo{ struct Bar{ public String Msg{get;set;} } class Program{ public static void main(String[] args){ Bar bar1 = new Bar(); bar1.Msg = "Hey, man!"; UpdateProp(bar1); Console.WriteLine(bar1.Msg); // Hey,man! } static void UpdateProp(Bar bar){ bar.Msg = "Bye!"; } } }
稍微总结一下,Call-by-value有如下特点:
1. 若克隆的“值”为值类型则为值本身,并且在函数内的任何修改将不影响外部对应变量的值;
2. 若克隆的“值”为引用类型则为内存地址,并且在函数内的修改将影响外部对应变量的值,但赋值操作则不影响外部对应变量的值。
注意:由于第2个特点与Call-by-sharing的特点是一样的,因此虽然Java应该属于采用Call-by-sharing策略,但社区还是声称Java采用的是Call-by-value策略。
Call/Pass-by-reference
其实Call-by-reference和Call-by-value一样那么容易被人误会,以为把内存地址作为实参传递就是Call-by-reference,其实不然。关键是这个“内存地址”是实参对应的内存地址,而不是实参对应的内存中所存放的地址。C语言木有天然地支持Call-by-reference策略,但可以通过指针来模拟,反而能让我们更好地理解整个求值过程。
int i = 1; int *pI = &i; // &i会获取i对应内存空间的地址,并存放到pI对应的内存空间中 void foo(int *); void foo(int *pI){ pI = 2; // 直接操作i对应的内存空间,等同于i = 2 } int main(){ foo(pI); printf("%s", i); // 返回2 return 0; }
内存结构:
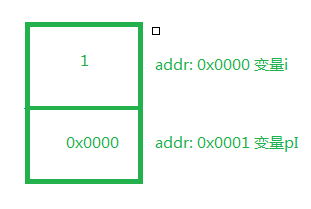
而C#可通过在形参上添加ref或out来设置采用Call-by-reference策略,Java和JavaScript就天生不支持也没有提供模拟的方式。
Call-by-sharing/object/object-sharing
采用该策略的语言暗示该语言主要基于引用类型而不是值类型。
Call by sharing implies that values in the language are based on objects rather than primitive types , i.e. that all values are " boxed ".
明显Java和受Java影响甚深的JavaScript就是采用这种策略的。
该策略特点和Call-by-value的个特点一致。
Call-by-copy-restore(copy in copy out, call-by-value-result, call-by-value-return)
暂时我还没接触到哪种语言采用了Call-by-copy-restore这种求值策略,它的运算过程主要分为两步:
1. 如Call-by-value的特点1那样,对实参进行拷贝操作,然后将副本传递到函数体内。重点是,即使实参为引用类型,也对引用所指向的对象进行拷贝,而不是仅拷贝指针而已。
效果:在函数体内对实参的任何操作(PutValue和Assignment)均不影响外部对应的变量。
2. 当退出函数执行上下文后,将实参值赋值到外部对应的变量。
/*** pseudo code ***/ var a = {} function foo(a){ a.name = 'fsjohnhuang' console.log('within foo:' + a.name) // 线程挂起1000ms var sd = +new Date() while(+new Date - sd < 1000); } // 异步执行foo var promise = foo.async(a) while(+new Date - sd < 100); // 未退出foo的执行上下文时,访问a.name,返回undefined console.log(a.name) if (promise.done){ // 退出foo的执行上下文时,返回a.name,返回'fsjohnhuang' console.log(a.name) }
Partial evaluation
即是部分实参在进入函数执行上下文前将不参与求值操作。示例如下:
var freeVar = {type: 'freeVar'} function getName(){ return freeVar } function print(msg, fn){ console.log(msg + fn()) } // 调用print时getName将不会被马上求值 print('Hi,', getName)
可以看到上述print函数调用时不会马上对getName实参求值,但会马上对'Hi,'进行求值操作。而需要注意的地方是,由于getName是延迟计算,若函数体内存在自由变量(如freeVar),那么后续的每次计算结果均有可能不同(也就是side effect)。
Non-strict evaluation(lazy-evaluation/calculation)
Non-strict Evaluation是指在执行函数体的过程中,需要用到该实参才进行运算的策略。还记得逻辑运算符(||,&&)的短路运算(short-circuit evaluation)吗?这个就是延迟计算其中一个实例。
下面我们一起来了解4种延迟计算策略吧!
Normal Order (Evaluation)
Normal Order又名leftmost outermost,中文翻译为“正常序列”,一般通过与Applicative Order作对比来理解效果较好。还记得Applicative Order可能会引起内存溢出的问题吗?那是因为Applicative Order会不断地对AST中层数最深的可规约表达式节点优先求值的缘故,而Normal Order则采用计算完AST中层数最浅的可规约表达式节点即可。
/ function definitions function foo(){ return false || foo() } function test(a, f){ console.log(a + f) } // main thread, 显示 "1false" test(1, foo())
Call-by-name
这种延迟计算策略十分容易明白,计算过程就是在执行函数体时,遇到需计算实参表达式时才执行运算。注意点:
1. 每次在执行实参表达式时均会执行运算;
2. 若实参的运算过程为计算密集型或阻塞性操作时,则会阻塞函数体后续命令的执行。(这时会可通过 Thunk 對Call-by-name进行优化)
Call-by-need
其实就是Call-by-name + Memoized,就是第一计算实参表达式时,在返回计算结果的同时内部自动保存该结果,当下次执行实参表达式计算时直接返回首次计算的结果。注意点:
1. 该策略仅适用于pure function的实参,存在free variable则会导致无法确保每次的求值结果都一样。
Call-by-macro-expansion
在Clojure中使用macro时则就是采用Call-by-macro-expansion策略,会执行expansion阶段對函数体内的实参表达式替换为macro所定义的表达式,然后在进行运算。
Non-deterministic strategies
另外由于实参的运算时机具有不确定性,因此下面的策略不能归入Strict和Non-strict求值策略中。
Call-by-future
这是一个并发求值策略,就是将求值操作委托给future,并由后续的promise去完成求值操作,然后调用者则通过future获取求值结果。注意点:
1. 求值操作可能发生在future刚创建时,也有可能调用future获取结果时才求值。
Conclusion
上述是查阅各资料后,對几类求值策略的理解,若有纰漏请大家指正,谢谢!
尊重原创,转载请注明来自: http://www.cnblogs.com/fsjohnhuang/p/4700102.html 肥仔John^_^
Thanks
https://en.wikipedia.org/wiki/Evaluation_strategy
http://stackoverflow.com/questions/8848402/whats-the-difference-between-call-by-reference-and-copy-restore
https://en.wikipedia.org/wiki/Thunk#Call_by_name
http://blog.csdn.net/institute/article/details/23750307
http://www.cnblogs.com/leowanta/articles/2958581.html
http://blog.csdn.net/sk__________________/article/details/12848597
http://dmitrysoshnikov.com/ecmascript/chapter-8-evaluation-strategy/
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

