Android性能优化典范(三)
CSDN移动将持续为您优选移动开发的精华内容,共同探讨移动开发的技术热点话题,涵盖移动应用、开发工具、移动游戏及引擎、智能硬件、物联网等方方面面。如果您想投稿、参与内容翻译工作,或寻求近匠报道,请发送邮件至tangxy#csdn.net(请把#改成@)。
Android性能优化典范 的课程最近更新到第三季了,这次一共12个短视频课程,包括的内容大致有:更高效的ArrayMap容器,使用Android系统提供的特殊容器来避免自动装箱,避免使用枚举类型,注意onLowMemory与onTrimMemory的回调,避免内存泄漏,高效的位置更新操作,重复layout操作的性能影响,以及使用Batching,Prefetching优化网络请求,压缩传输数据等等使用技巧。下面是对这些课程的总结摘要,认知有限,理解偏差的地方请多多交流指正!

1) Fun with ArrayMaps
程序内存的管理是否合理高效对应用的性能有着很大的影响,有的时候对容器的使用不当也会导致内存管理效率低下。Android为移动操作系统特意编写了一些更加高效的容器,例如SparseArray,今天要介绍的是一个新的容器,叫做 ArrayMap 。
我们经常会使用到HashMap这个容器,它非常好用,但是却很占用内存。下图演示了HashMap的简要工作原理:

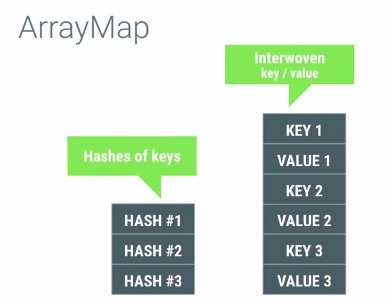
为了解决HashMap更占内存的弊端,Android提供了内存效率更高的ArrayMap。它内部使用两个数组进行工作,其中一个数组记录key hash过后的顺序列表,另外一个数组按key的顺序记录Key-Value值,如下图所示:
当你想获取某个value的时候,ArrayMap会计算输入key转换过后的hash值,然后对hash数组使用二分查找法寻找到对应的index,然后我们可以通过这个index在另外一个数组中直接访问到需要的键值对。如果在第二个数组键值对中的key和前面输入的查询key不一致,那么就认为是发生了碰撞冲突。为了解决这个问题,我们会以该key为中心点,分别上下展开,逐个去对比查找,直到找到匹配的值。如下图所示:
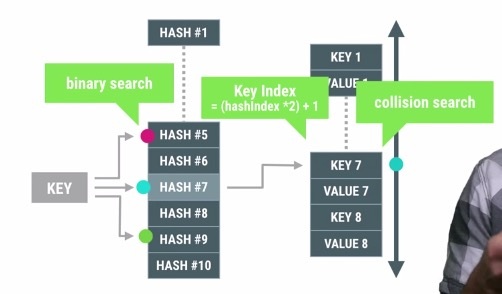
随着数组中的对象越来越多,查找访问单个对象的花费也会跟着增长,这是在内存占用与访问时间之间做权衡交换。
既然ArrayMap中的内存占用是连续不间断的,那么它是如何处理插入与删除操作的呢?请看下图所示,演示了Array的特性:
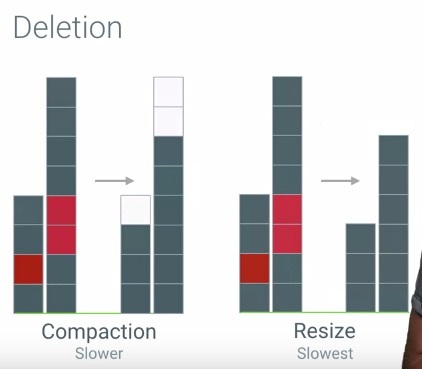
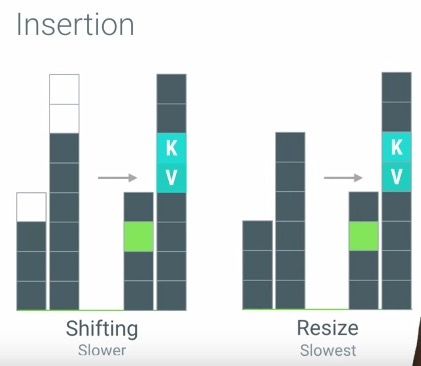
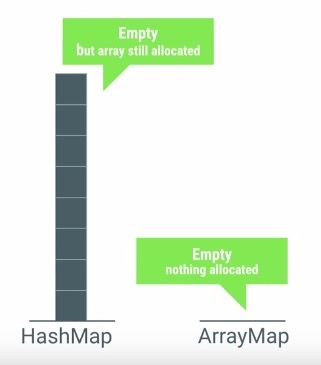
很明显,ArrayMap的插入与删除的效率是不够高的,但是如果数组的列表只是在一百这个数量级上,则完全不用担心这些插入与删除的效率问题。HashMap与ArrayMap之间的内存占用效率对比图如下:
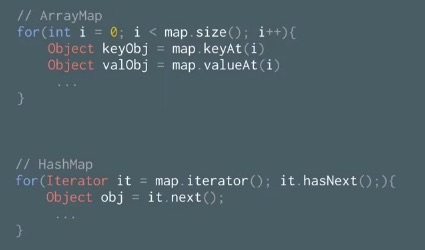
与HashMap相比,ArrayMap在循环遍历的时候也更加简单高效,如下图所示:
前面演示了很多ArrayMap的优点,但并不是所有情况下都适合使用ArrayMap,我们应该在满足下面2个条件的时候才考虑使用ArrayMap:
- 对象个数的数量级最好是千以内;
- 数据组织形式包含Map结构。
我们需要学会在特定情形下选择相对更加高效的实现方式。
2) Beware Autoboxing
有时候性能问题也可能是因为那些不起眼的小细节引起的,例如在代码中不经意的“自动装箱”。我们知道基础数据类型的大小:boolean(8 bits), int(32 bits), float(32 bits),long(64 bits),为了能够让这些基础数据类型在大多数Java容器中运作,会需要做一个autoboxing的操作,转换成Boolean,Integer,Float等对象,如下演示了循环操作的时候是否发生autoboxing行为的差异:

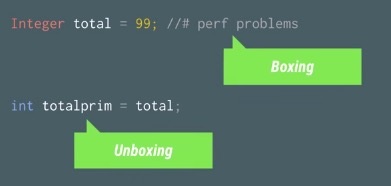
Autoboxing的行为还经常发生在类似HashMap这样的容器里面,对HashMap的增删改查操作都会发生了大量的autoboxing的行为。
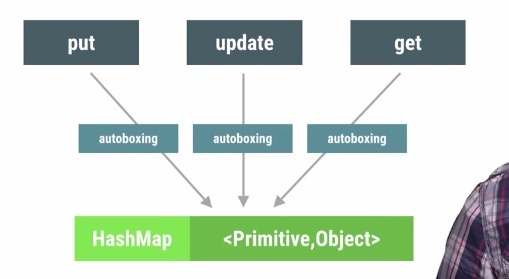
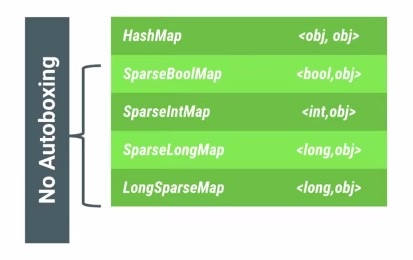
为了避免这些autoboxing带来的效率问题,Android特地提供了一些如下的Map容器用来替代HashMap,不仅避免了autoboxing,还减少了内存占用:
3) SparseArray Family Ties
为了避免HashMap的autoboxing行为,Android系统提供了SparseBoolMap,SparseIntMap,SparseLongMap,LongSparseMap等容器。关于这些容器的基本原理请参考前面的ArrayMap的介绍,另外这些容器的使用场景也和ArrayMap一致,需要满足数量级在千以内,数据组织形式需要包含Map结构。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

