百度深度学习的图像识别进展
本文是百度文章《基于深度学习的图像识别进展:百度的若干实践》的摘要,其中个人观点仅供参考。
1 深度学习三大优势
在百度的实践中,我们认识到深度学习主要在以下三个方面具有巨大优势:
1.1 深度学习特别适合处理大数据
从统计和计算的角度看,深度学习特别适合处理大数据。
它集中体现了当前机器学习算法的三个大趋势:
1)用较为复杂的模型降低模型偏差(model bias),
2)用大数据提升统计估计的准确度,
3)用可扩展(scalable) 的梯度下降算法求解大规模优化问题。
【视觉机器人:这个大数据是除了数量上的大,我觉得还有更重要的是维度的大,很多算法本身是无法处理高纬度数据的,例如Kernel学习机相关的算法,虽然理论上是先将数据向高维空间映射,然后在高维空间进行线性的求解,实际上在处理的时候还是回到原空间处理。传统的BP算法针对高维的数据也是效果不佳。
CNN等为什么对图像领域更加有效,因为其不但关注了全局特征,更是利用了图像识别领域非常重要的局部特征,应该是将局部特征抽取的算法融入到了神经网络中。图像本身的局部数据存在关联性,而这种局部关联性的特征是其他算法无法提取的。所以我认为深度学习很重要的是对全局和局部特征的综合把握】
1.2 深度学习不是一个黑箱系统。
1:用卷积处理图像中的二维空间结构,
2:用递归神经网络(Recurrent Neural Network, RNN) 处理自然语言等数据中的时序结构
【视觉机器人:递推更加符合人的认知行为,我觉得更有实用价值,递推算法可以广泛的应用于时间序列数据中,大到国家宏观经济数据,小到股市的每分钟交易,以及工业企业中所有的传感变量。但是是否是深度学习的用武之地,我觉得更主要的是看数据维度是否够大,以及是否在数据中存在关联的局部特征。】
1.3 深度学习几乎是唯一的端到端机器学习系统
传统机器学习往往被分解为几个不连贯的数据预处理步骤,比如人工抽取特征,这些步骤并非一致地优化某个整体的目标函数。
【视觉机器人:在我看来深度学习本身就是一套系统一个架构,而不是一个单一的算法,有时候不能用深度学习和其他单一算法例如SVM算法比较,深度学习本身也是有抽取特征的网络部分】
经验1:丰富的图像扰动是我们将关于图像的先验知识用于深度学习输入端的有效手段
经验2:结构化损失函数是我们将模型化知识用于深度学习输出端的有效方式
经验3:参数的稀疏化、图像的多分辨率通道、多任务的联合学习是我们将关于问题的认知和理解注入到深度学习模型结构中的有效方式。
前面所述深度学习的三大优势,在最近图像识别的进展中体现得淋漓精致:
1)模型结构越来越复杂, 训练数据规模也不断增加;
2)各种关于数据结构的先验知识被体现到新的模型结构中;
3)端到端学习让我们越来越摒弃基于人工规则的中间步骤。
【视觉机器人:个人认为先验知识对于做产品很重要,所以要做好某方面的产品,必须成为这个领域的专家】
2 基于深度学习的图像分类和物体检测算法
在物体检测方面,如图2 所示,目前主流的算法大都采用扫描窗或是候选窗方法。扫描窗方法能够在相邻窗口之间共享特征,可以快速地扫描较大面积的图像;候选窗方法能够高效地在图像候选区域内进行识别,更为灵活地处理物体长宽比的变化,从而获得较高的交并比覆盖率。

近几年,深度学习在图像识别中的发展主要有以下几个趋势:
1)模型层次不断加深
到2014 年,获得冠军的GoogleNet使用了59 个卷积层(另外包括16 个pool 层和2 个norm 层)。
2)模型结构日趋复杂。
3)海量的标注数据和适当的数据扰动。
结合图像数据的特点,包括平移、水平翻转、旋转、缩放等数据扰动方式被用于产生更多有效的训练数据,能够普遍提高识别模型的推广能力。
百度利用并行分布式深度学习平台(Parallel Distributed Deep Learning, PADDLE),收集建立起规模更大、更符合个人电脑和移动互联网特点的图像数据仓库。以互联网色情图片过滤为例, 我们的训练数据囊括了1.2 亿幅色情图像,分类精度达99.4%。
【视觉机器人:1.2 亿幅色情图像,我也是High了,百度云先把让屌丝在云上肆无忌惮的传播色情信息,然后又统统的清0,最后原来是开发出来这么个色情图像识别系统啊,你是不是该感谢一下那么多的卢泽尔。
知乎上有个关于百度云色情图像的识别算法的套路。http://www.zhihu.com/question/27652950
百度云是如何识别出 A 片的?“熊辰炎,PhD在读@CMU, 搜索,知识图谱,机器学习“有638的点赞】
3 基于端到端的序列学习:对传统光学字符识别框架的改造
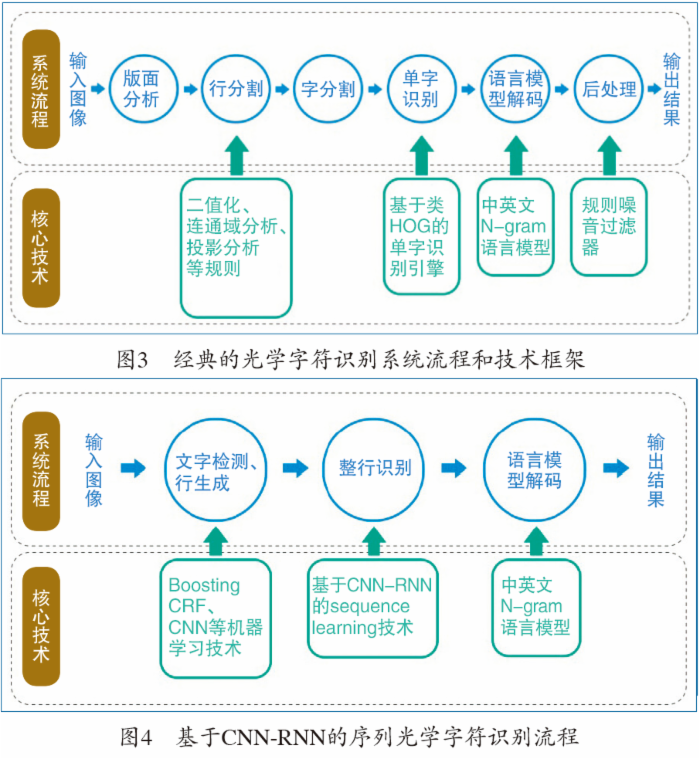
对经光学字符识别的系统流程和技术框架进行了大幅改造(见图4)。
1)在系统流程方面,引入文字检测概念,和行分割合并成新的预处理模块,任务是检测图像中包含文字的区域并生成相应文字行;
2)将字分割和单字识别合并成新的整行识别模块;
3)基于N-gram 的语言模型解码模块予以保留,但将主要依赖人工规则的版面分析和后处理模块从系统中删除。
4)此外, 由于整行文字识别是一个序列学习问题,我们有针对性地研发出基于双向长短期记忆神经网络(Bidirectional Long Short-term Memory, BLSTM) 的递归神经网络序列模型学习算法。
【视觉机器人:有关OCR识别,可以补充阅读**,里面有专门的Paper可下载】
另:百度语音技术负责人@贾磊_语音技术男,4月2日发布的微博消息:百度语音技术部成功研发出改进型长短时记忆模型(LSTM)的深度学习技术,成功上线百度语音输入法,语音识别率大幅度提升。2015年4月初安静环境中文普通话语音识别世界领先。同行竞争,此消彼涨。欢迎业界跟进,共同繁荣汉语语音识别市场。】
4 并行分布式深度学习平台
根据高维稀疏数据的特点,并行分布式深度学习平台还提出并实现了许多非常具有针对性的体系结构和算法
1)由于海量的高维数据需要规模极大的模型与之匹配, 因此模型和数据只能分布式地存储在大量的节点上
2)尽管有海量的数据,但是由于数据的稀疏性,过拟合仍然是需要时刻警惕的问题。
3) 并行分布式深度学习平台对同时需要稠密矩阵运算和稀疏矩阵运算的场景进行了优化。
5 展望未来
基于深度学习的图像识别问题可围绕如下几个重点展开:
1)增强学习
2)大规模弱标注和部分标注数据的应用
3)低层视觉和高层视觉的广泛结合
4)适合进行深度学习模型计算的硬件高速发展
【视觉机器人:个人更觉得底层视觉和高层视觉的结合是一个方向,高层视觉对底层视觉需要有一个反馈的环节,这个比较符合人的认知行为】
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

