沈国阳:美团推荐系统整体框架与关键工作
8月 11日晚20:30,受CSDN人工智能用户群邀请,美团推荐与个性化团队技术经理沈国阳来到CSDN在线视频分享平台,为我们深度解析美团本地生活服务推荐的工作经验,并与群友进行互动交流。沈国阳重点介绍了美团推荐系统的架构和特色,以及在排序层面的主要工作。
沈国阳表示, 对于推荐系统的效果提高,排序比候选集的贡献要大很多。美团排序的主要工作包括:模型及建模,样本采样及label处理,去除position bias,特征工程,Interleaving的使用,以及Online Learning的尝试等。
以下为分享内容文字整理:
美团推荐产品
沈国阳首先介绍了美团的几个重要的推荐产品:
- 猜你喜欢 :美团最重要的推荐产品,目标是让用户打开美团 App的时候,可以最快找到他们想要的团购服务。已经做了2年多,交易额占比从最初的0.7%提高到7~8%。
- 首页频道推荐 :若干频道是固定的,若干频道是根据用户的个人偏好推荐出来的。这个区域为美团 app带来40%以上交易额。
- 今日推荐个性化推送 :美团的个性化推送的产品,目的是在用户打开美团 App前,就把他们最感兴趣的服务推送给他们,促使用户点击及下单,从而提高用户的活跃度。
- 品类列表的个性化排序 :美团首页的那些品类频道区,点进去的列表的智能排序,也是我们进行个性化优化的重要位置。相对于搜索,这个位置用户的意图不是非常明确,个性化程度较高;但是相对于首页的猜你喜欢,这个位置用户的意图则要强一些,个性化程度稍低一些。
美团推荐系统的目标
美团推荐系统的目标,首先是要帮助用户快速找到所需。推荐系统作为美团C端平台的重要组成部分,其目标就是为消费者快速找到“高品质,低价格”的服务。判断是否实现目标,主要是看消费者看了推荐结果以后的 下单转化效果 。
另外,美团希望消费者对美团的品牌认知是“吃喝玩乐”的大平台,所以也希望推荐出来的结果包含多个品类的结果,即 推荐结果有多样性 。
目前,美团的目标还主要集中在下单转化效果,随着下单率效果的大幅度提高,今后会把重心转到多样性。
推荐系统的整体框架
沈国阳接下来介绍了美团提高推荐下单转化效果的实现路径。其推荐系统的整体框架如下:
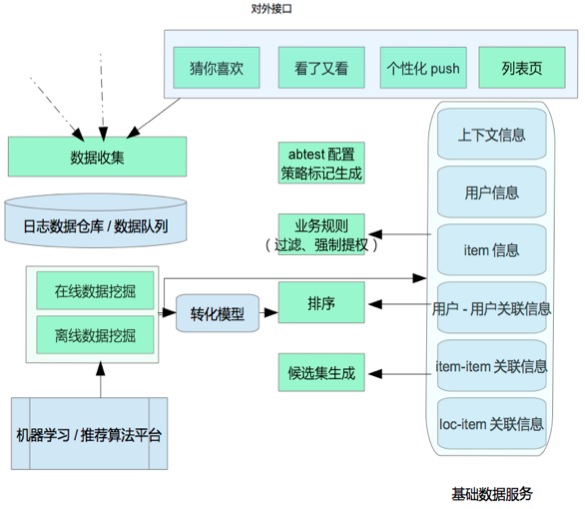
沈国阳解释说,最顶层显示的是推荐系统对外的服务接口。由于不同展位的输入输出参数差异较大,因此这一层没有做过多的抽象,每个展位有自己特定的接口形式。
接口层会调用 abtest配置模块,对接入的流量按照uuid、城市等维度进行分流量的配置。abtest对于推荐系统是很重要的基础模块,美团对这个模块的要求,是可以有友好的配置界面,灵活根据不同不同维度进行分流量配置,并且立即生效,无需重启服务。
Abtest配置模块之下,是推荐候选集的生成,排序和业务处理模块。候选集生成和排序模块,除了针对不同展位有不同逻辑以外,对同一展位的不同策略也有不同的逻辑。 abtest模块在配置流量策略的时候,可以根据需要单独配置候选集策略和排序策略。业务规则处理模块,则有统一的处理逻辑,也有每个展位独特的逻辑,而同一展位的不同策略,通常来说在这一层处理逻辑不会有区别。
重新从接口层开始换个方向来看这个框架。在响应请求的同时,会打印一些必要的日志,记录这次请求的一些必要的上下文信息以及用户及 item相关的特征信息,以便生成训练数据。这些日志通过flume传输到HDFS上面。除了推荐系统以外的美团App其他后台服务,也会把各自的日志传递给HDFS,以方便后续进行数据挖掘。借助Hadoop、Hive、Spark等平台以及美团自己实现的一些机器学习/推荐通用算法,对原始日志进行处理,从而得到需要的 各种数据及模型:包括用户的profile信息,用户之间的相似度,item之间的相似度,后续我们将要重点介绍的地理位置与item之间的关联关系,以及转化率预估模型。
这些数据及模型在刚才介绍的候选集生成模块,排序模块,业务处理模块会被使用到。
在推荐系统的候选集生成这一块, 美团重度使用了传统的 user based,item based协同过滤算法 。这里面需要注意的是,美团 引入了时间衰减的因子,从而使新的行为起的作用大于老的行为 ,从结果来看,这确实对于效果会有提升。同时,美团尝试了不同的相似度计算方式,发现 基于llr(Log-likelihood ratio)的相似度计算比cosine相似度计算的最终效果要好一些 。在首页的猜你喜欢这个展位上,美团发现 user based算法比item based效果要好很多 。原因和user based算法更容易推荐出有一定新颖性的item有关。
美团推荐平台的重要特点
上述传统协同过滤算法,需要在用户行为较丰富的情况下才能奏效。而对于那些行为稀少的用户,需要根据平台的特点进行做好冷启动策略。沈国阳介绍美团平台的几个重要特点如下:
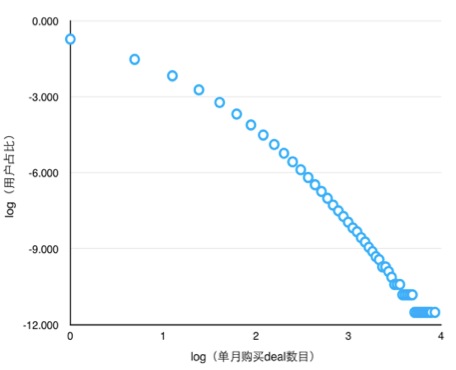
1. 冷启动用户占比高
2. 移动终端占比高
美团的移动终端用户占比和移动终端交易额,都已经超过美团整体交易额的 90%。这导致美团用户的使用场景往往是这样的,和朋友约定到哪个shopping mall逛街,逛完了再用美团看看周边有什么饭馆,决定要去哪里吃饭。或者看完一场电影,出来再上美团看看,决定去哪个酒店。
这就引出美团平台交易的另外 2个特点。
3. 持券时间短
用户从下单到消费的时间间隔。下图显示的是美团平台上不同类型交易在持券时间上的分布。从中可以看出,电影,美食这样的高频品类的持券时间都非常短, 40%的用户在一个小时以内消费。只有像摄影写真,美发这样的低频品类,持券时间会比较长。而美团平台上,美食,电影这种高频品类的交易额占比非常高。
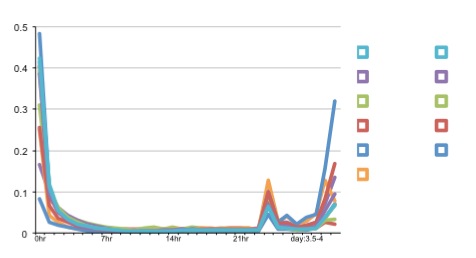
4. 持券距离近
持券距离指的是用户下单地点和消费地点之间的距离。上图纵轴表示对应城市的某个品类的所有交易订单中,持券距离最近的 top 80%的交易中的最远的持券距离。可见,大部分城市和品类,top 80%持券距离在2000米以内。
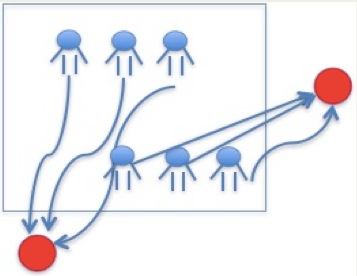
“本地人热单”策略
基于以上特点,美团在用户冷启动上,研发了“本地人热单”策略。如下图所示,就是指一定区域内的用户,浏览或者购买较多的 top items。
这里面又有一个问题,这个区域多大范围,怎么定义呢?
美团的目标是,使这个区域足够细,同时又能够使这个区域内的用户行为统计有一定的统计意义。目前使用的是商圈,平均覆盖范围在十几平方公里。
给用户进行推荐时,主要根据用户的实时商圈进行推荐该商圈的本地人热单。但是,由于技术原因或者其他原因,用户的实时位置并不总是能够获取到,或者用户的实时商圈,可推荐的 item数量太少。这时候,需要采用其他的替代方案。美团在用户地理位置方面进行了大量挖掘工作。例如,用户周末/平时常去商圈,用户的周末/平时常消费商圈,用户的工作地/居住地附近商圈等,用这些商圈信息,可以根据具体情况,丰富推荐的item。
不同时间段的用户需求是不一样的,因此每个时间段的本地人热单应该是变化的。然而划分太细的时间段,数据量往往又太稀疏,因此通过把其他时段的数据根据时间相似度加权统计进来,效果又会有进一步的提高。
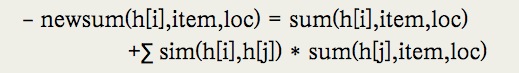
美团排序的主要工作
沈国阳还分享了美团排序经验。他表示,对于推荐系统的效果提高,排序比候选集的贡献要大很多。美团在排序方面所做的主要工作如下:
1. 模型及建模
目前美团的推荐系统的排序模型主要是 Additive Groves模型,另外也在探索FTRL这样的在线学习模型。AG模型是一种决策树类型的模型,属于非线性模型。这种非线性模型的特点,是一定程度上能够自动进行特征组合的工作,不需要人工进行大量这类工作。
建模方法和传统的 ctr预估建模方法一样,是point wise的模型。每一个item对一个用户的每次展示可以作为一个样本,这个item是否被点击或者是否被下单作为标记。美团会为这些样本抽取一些item特征,用户特征,上下文特征,item与用户的交叉特征。
2. 样本采样及 label处理
由于我们的最终目标是提高 item的下单转化效果,所以我们需要重点采用用户下单行为作为标记。但是如果只用下单行为,又会导致数据较为稀疏,有很大比例的用户很长时间内是没有下单行为的。所以我们还需要使用点击行为作为标记。而对点击行为和下单行为对于训练目标的价值是不一样的,对它们需要做不同的处理。美团尝试了2种方式,在参数取得比较合适的情况下,二者的结果效果都很好。一种方式是提高下单样本的采样比例,比如相对点击样本提高30倍。一种方式是提高标记值。比如下单行为的标记值为30,点击行为的标记值为1。
3. 去除 position bias
item在展示列表中的位置,对 item的点击概率和下单概率是有非常大影响的,排名越靠前的item,越容易被点击和下单,这就是position bias的含义。在抽取特征和训练模型的时候,就需要很好去除这种position bias。我们在两个地方做这种处理:一个是在计算item的历史ctr和历史cvr的时候,首先要计算出每个位置的历史平均点击率ctr_p,和历史平均下单率cvr_p,然后在计算item的每次点击和下单的时候,都根据这个item被展示的位置,计算为ctr_0/ctr_p及cvr_0/ctr_p;一个是在产生训练样本的时候,把展示位置作为特征放在样本里面,并且在使用模型的时候,把展示位置特征统一置为0。
4. 特征工程
特征工程是排序模型的最重要工作,排序带来的效果提升,大部分是由特征工程带来的。但是提起这部分工作,又会比较枯燥,就是不断地去接触和理解业务数据,试图从中挖掘出和用户转化相关的特征。美团使用的主要特征包括:
- 上下文特征 :如时间,地理位置(商圈),天气,温度等。
- item特征 :如团购服务的价格,销量,用户评分。这部分特征用得很多,但是过多公开容易引起作弊,所以不详细介绍。
- 用户特征 :用户的属性特征,如年龄,性别,婚育状态,品类偏好,价格偏好等。
5. Interleaving的使用
美团进行策略效果对比所使用的方法是 abtest。abtest的好处是能够对多个策略的效果差异给出定量的评估,但是也存在一些问题,比如,如果两个策略的效果差异较小,abtest容易给出波动较大的结果,需要较长时间(一般是一周)才能判断结果,会导致效果迭代速度较慢。为了解决这个问题,美团采用interleaving效果评估方式作为补充。Interleaving方式的好处是所需流量较小,灵敏度较高,一般24小时之内可以给出结论,但是它只能给定性结论而不能给定量结论。 Interleaving的基本思想是把两个策略的结果混合在一起,通过统计分析用户选择哪个策略的概率更大。 具体列表混合的实现方式有多种。下面介绍比较简单使用的一种,叫Balanced方式。

两种参与对比的策略的列表如图所示,为 A列表及B列表。A列表的顺序为a,bcdgh,B列表的顺序为beafgh。Balanced合并方式的A first方式如下:A列表的a,B列表b,A列表的b重复了,顺延到B列表的e,如此循环下去。
采用这种列表混合方式的效果评估方式如下 :

统计所有用户对这个列表的下单情况。用户点击的 item在A列表排序靠前,则wins(A)++,用户点击的item在B列表排序靠前,则wins(B)++,中间情况则ites(A,B)++。德尔塔ab为正表示A策略优于B策略。
例如, wins(A)=40%, wins(B)=30%,tie=30% ,计算结果为5%,意味着 A策略比B策略的效果好。
6. Online Learning 的尝试
美团还尝试引入 Online Learning。沈国阳表示,互联网上的机器学习和传统机器学习存在很重要的区别:互联网上的机器学习面对的是活生生的用户,而用户群体的行为是受很多因素的影响不断变化的,季节因素,天气因素,空气质量,社会潮流,甚至一档电视节目,都会对用户的行为产生很大的影响,比如前段时间的奔跑吧兄弟,引发了撕名牌的热潮。为了能够更快捕捉用户行为模式的变化,非常有必要引入Online Learning。
美团 online learning的工作正在进展中,效果还不够稳定。沈国阳预告说,美团将会在9月中旬举行的美团第二届技术沙龙活动中着重介绍其Online Learning算法。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

