简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制
文章地址: http://www.cnblogs.com/likeli/p/4730709.html
好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有一些反爬取意识,所以就有了本文了。
我先说说 场景 吧:
由于工作需要,平时有一大堆数据需要在网上查询,并归档存库。某次,这种任务也给我安排了一份。观察了一网站,我的第一反应就是用爬虫取抓取。这种机械的工作何必人工呢?
由于这家网站有反爬虫的意识,做了些工作,给我的爬虫去爬取数据造成了某些麻烦。
先列举出问题所在:
- 首当其冲,验证码,该网站采用了数字加中文的简单四则运算作为验证码。
- 查询目标路径参数经过了加密,我并不能直接通过取路径加参数的方式来直接跳过某些页面。
- IP限制,该网站对访问的IP做了访问次数计数限制。经过我的测试,一个纯净IP访问该网站一小时内最多能爬取40个有效数据(这里针对我的抓取目标来说,HTTP请求次数差不多之多200次,但是若在30s内访问次数超过25次HTTP请求,那么这个IP就直接被封掉)
好吧,主要的问题就是这些,一些爬取过程中的小问题,就不列举了。园子里面一大堆的解决方案。这里我主要说的是, 验证码和IP限制 的问题。
当然,我的解决方案并不是什么高超的技巧。应该都是老路子了。
1、 验证码
原图:



这种的验证码难度在于字符粘连,字符随机旋转问题。这两种,我分别采用了 投影直方图分割 、 卡壳法 来分别切割字符和校正角度。
我首先写了一个工具来测试:
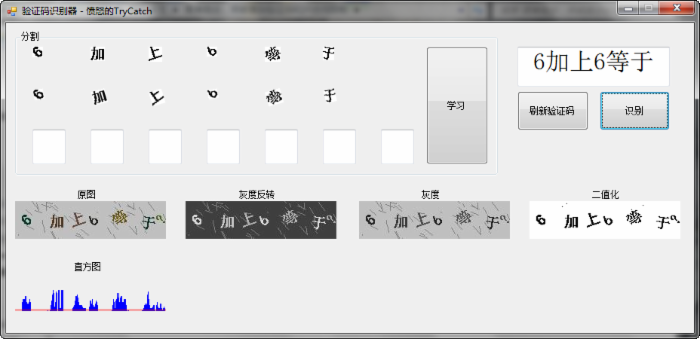
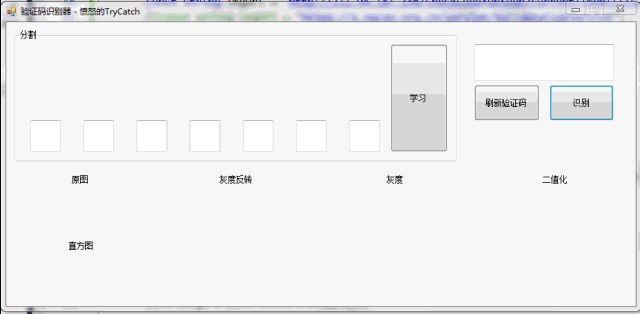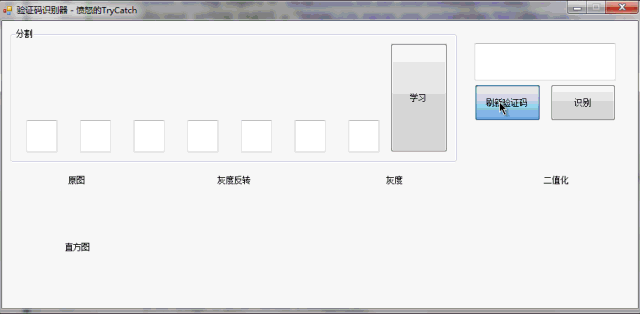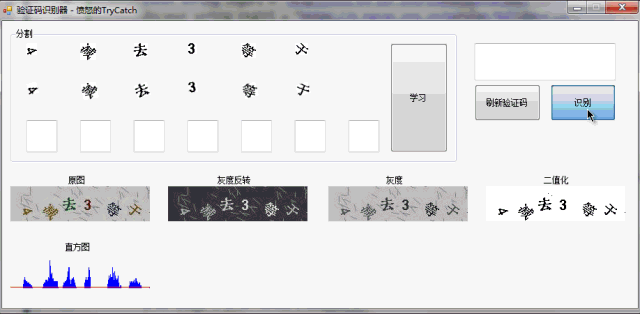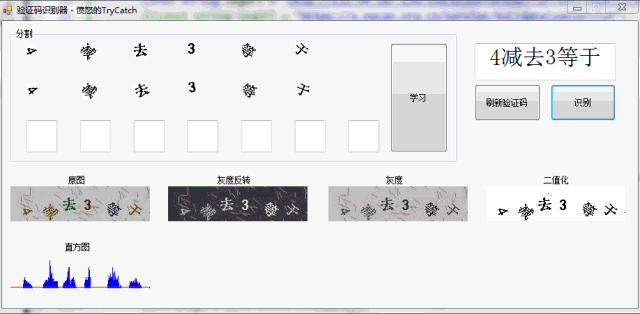
从上面的效果图,各位看官应该能看出,我的方法还是比较简单和传统的,那就是做特征库,通过分割出来的字符去匹配特征库的相似度来判断图片中的文字到底是什么。这里没有使用 第三方的光学识别(OCR ),因为识别汉字感觉识别率还是比较差,而且验证码中的汉字其实并不多,就是几个特定的字符,加减乘除等。所以通过特征库来识别也是绰绰有余了。
关于验证码,我来说说我的一些问题,对于灰度计算和二值化,园子里面有很多算法,但是对于降噪,也就是去干扰线,需要自己根据目标来写特定的算法。我这里是通过削皮的方式来去掉的,每次给所有阴影剥掉一层1px的范围,填充为白色。当然了,我这方法不具备通用性。不同的验证码需要根据观察来用不同的方式来去除。
分割呢,也就是直方图了,其实我的验证码也是可以根据色彩来做单色的直方图,这样来一步完成分割字符和降噪(有这想法,但是没有实际去实现。不过看有些大牛的博客说这样的方法是可行的)。我所了解到的分割方法还有滴水分割,不过我拿了论文资料,可惜看得不是很懂。下面贴了一段简单绘制直方图的方法:

1 //绘制直方图 2 var zftbit = new Bitmap(bit4.Width, bit4.Height); 3 using (Graphics g = Graphics.FromImage(zftbit)) 4 { 5 Pen pen = new Pen(Color.Blue); 6 for (int i = 0; i < bit4.Width; i++) 7 { 8 g.DrawLine(pen, i, bit4.Height - YZhiFang[i] * 2, i, bit4.Height); 9 } 10 //阀值 11 g.DrawLine(new Pen(Color.Red), 0, bit4.Height - 2, bit4.Width, bit4.Height - 2); 12 } 13 p_zft.Image = zftbit;绘制直方图
关于随机旋转的字符问题,我的做法是,将验证码中的字符分割成独立单位后,进行正负30度旋转,每旋转一次,计算一次投影宽度,由于我们的字体基本上都是‘方块字’,所以呢,在旋转的时候,最小宽度肯定是‘摆正’了的,不过,这里有个小问题,那就是若源字符旋转超过45°,我们将字横着放置的时候,其宽度也是最小的。不过我们让机器多学习几次,将四个方向摆放的图形都学习了,就可以了。这就是卡壳法了。
2、IP限制问题
这里我用了最无赖也是最无解的方法来解决的。我直接通过切换访问的代理来突破,这里没有丝毫技术性含量。挂上代理后,去访问目标网站,根据返回的结果判断代理是否还有效。若是无效了,将当前查询目标回滚一次,并切换代理就行了。
3、爬虫
主角爬虫来了,我最早设计的爬虫是不控制时间的连续访问的,这导致代理消耗的特别快。所以不得不想办法解决这个问题。另外由于没有专门的爬虫服务器,我只能通过办公室的电脑来完成这项任务。由此,我设计了一个总线式爬虫。
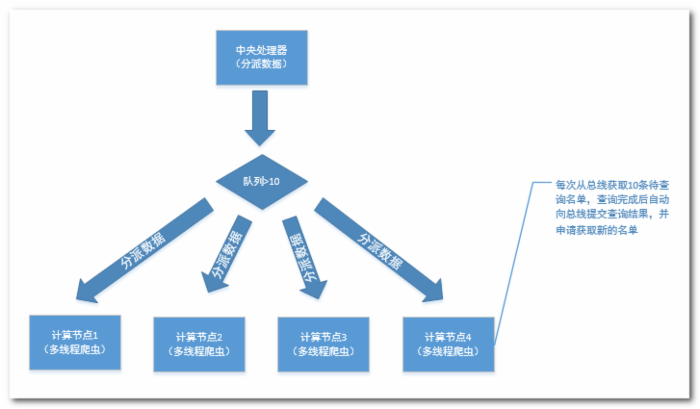
我写了一个爬虫服务端和一个爬虫客户端,服务端当做中央处理器,来分配计算量,客户端爬虫用来抓取数据。这样的情况下,各个客户端执行的速度其实是不一样的,请求响应又快又慢,验证代理是否有效也需要时间,所有,客户端爬虫完成任务的时间肯定不一样,所以我安排了这样一台电脑做作为中央处理器,分批次,小剂量的去分发任务列表。并接收客户端回传的结果,等完成所有任务之后统一导出或者进行写入数据库等其他操作。
爬虫节点
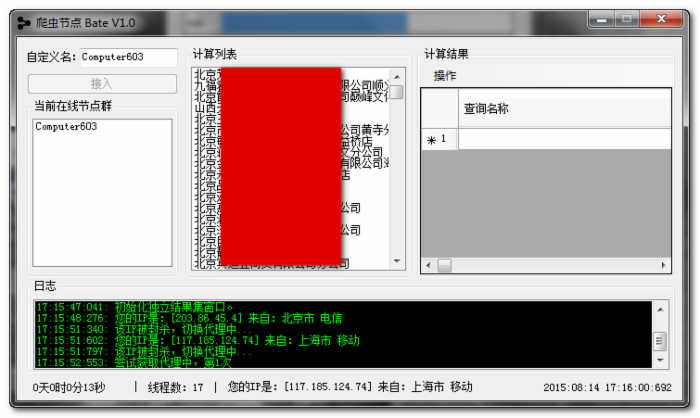
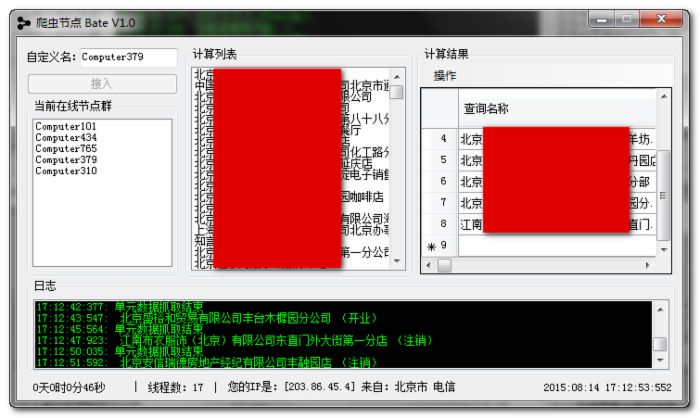
每个节点上的爬虫,给17个线程去跑,10个做代理IP的验证,7个爬数据。若是给10台办公室的笔记本安装软件,一起去爬数据,那么,就相当于 70人/秒 的速度在访问这个网站。至此,效率问题也解决了。
总线
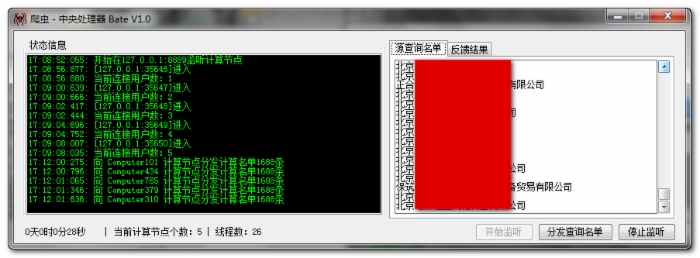
总线方面,将任务列表根据下面的节点数进行分配(上图是之前截的图,之前是均分出去,后来发现均分的客户端并不是同时完成,有的快有的慢,结果快的弄完了,就空闲了,慢的还在慢吞吞的跑,所以,之后进行了小剂量分配,变相的达到动态的安排任务量)。
后记
文章到此就基本上结束了,代码不多,我主要数我的制作思路,因为我的的这个并不具备通用性,验证码家家基本都不一样(一些极度简单的规规矩矩的纯数字或字母验证码不算,这类验证码跟没有一样)。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

