构建需求响应式亿级商品详情页
该文章是根据velocity 2015技术大会的演讲《 京东网站单品页618实战 》细化而来,希望对大家有用。
商品详情页是什么
商品详情页是展示商品详细信息的一个页面,承载在网站的大部分流量和订单的入口。京东商城目前有通用版、全球购、闪购、易车、惠买车、服装、拼购、今日抄底等许多套模板。各套模板的元数据是一样的,只是展示方式不一样。目前商品详情页个性化需求非常多,数据来源也是非常多的,而且许多基础服务做不了的都放我们这,因此我们需要一种架构能快速响应和优雅的解决这些需求问题。 因此我们重新设计了商品详情页的架构,主要包括三部分:商品详情页系统、商品详情页统一服务系统和商品详情页动态服务系统;商品详情页系统负责静的部分,而统一服务负责动的部分,而动态服务负责给内网其他系统提供一些数据服务。


商品详情页前端结构
前端展示可以分为这么几个维度:商品维度 ( 标题、图片、属性等 ) 、主商品维度(商品介绍、规格参数)、分类维度、商家维度、店铺维度等;另外还有一些实时性要求比较高的如实时价格、实时促销、广告词、配送至、预售等是通过异步加载。
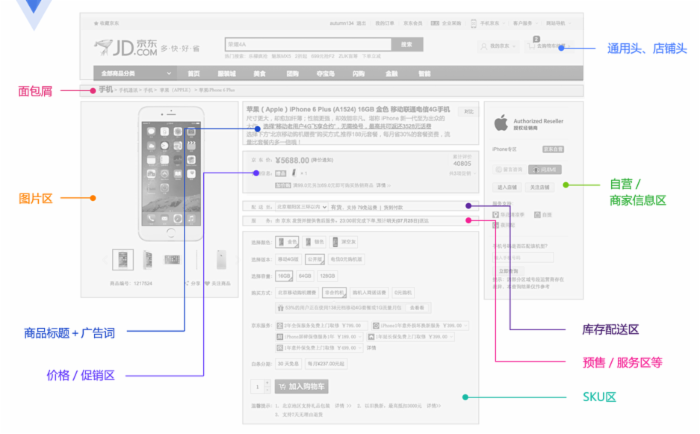

京东商城还有一些特殊维度数据:比如套装、手机合约机等,这些数据是主商品数据外挂的。
我们的性能数据
618 当天 PV 数亿, 618 当天服务器端响应时间 <38ms 。此处我们用的是第 1000 次中第 99 次排名的时间。
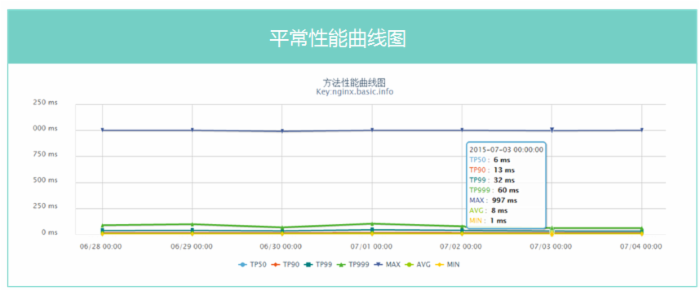
单品页流量特点
离散数据,热点少,各种爬虫、比价软件抓取。
单品页技术架构发展
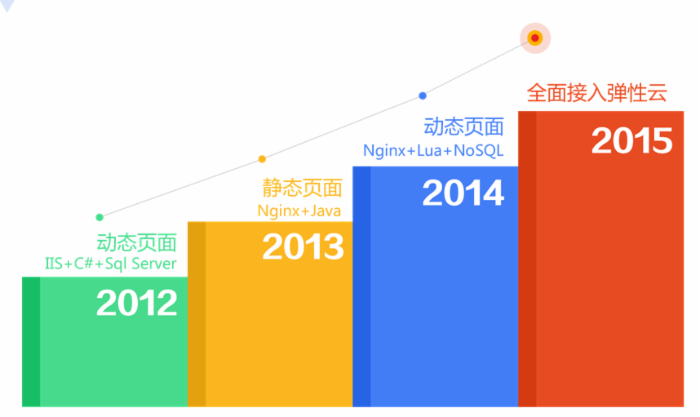
架构1.0
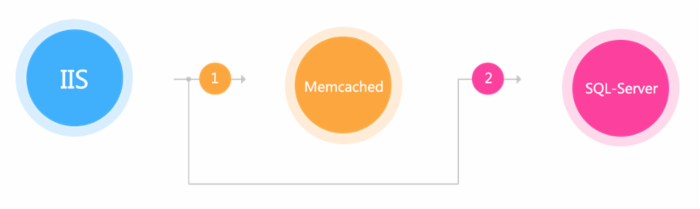 IIS+C#+Sql Server ,最原始的架构,直接调用商品库获取相应的数据,扛不住时加了一层 memcached 来缓存数据。这种方式经常受到依赖的服务不稳定而导致的性能抖动。
IIS+C#+Sql Server ,最原始的架构,直接调用商品库获取相应的数据,扛不住时加了一层 memcached 来缓存数据。这种方式经常受到依赖的服务不稳定而导致的性能抖动。
架构2.0
 该方案使用了静态化技术,按照商品维度生成静态化 HTML 。主要思路:
该方案使用了静态化技术,按照商品维度生成静态化 HTML 。主要思路:
1 、通过 MQ 得到变更通知;
2 、通过 Java Worker 调用多个依赖系统生成详情页 HTML ;
3 、通过 rsync 同步到其他机器;
4 、通过 Nginx 直接输出静态页;
5 、接入层负责负载均衡。
该方案的主要缺点:
1 、假设只有分类、面包屑变更了,那么所有相关的商品都要重刷;
2 、随着商品数量的增加, rsync 会成为瓶颈;
3 、无法迅速响应一些页面需求变更,大部分都是通过 JavaScript 动态改页面元素。
随着商品数量的增加这种架构的存储容量到达了瓶颈,而且按照商品维度生成整个页面会存在如分类维度变更就要全部刷一遍这个分类下所有信息的问题,因此我们又改造了一版按照尾号路由到多台机器。
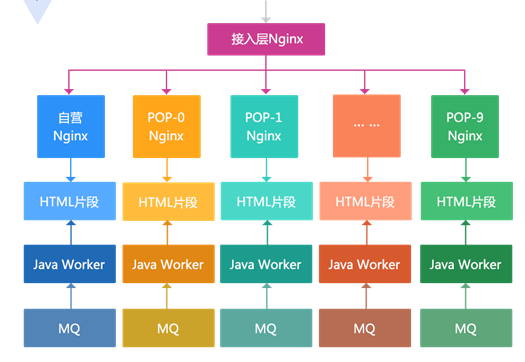 主要思路:
主要思路:
1 、容量问题通过按照商品尾号做路由分散到多台机器,按照自营商品单独一台,第三方商品按照尾号分散到 11 台;
2 、按维度生成 HTML 片段(框架、商品介绍、规格参数、面包屑、相关分类、店铺信息),而不是一个大 HTML ;
3 、通过 Nginx SSI 合并片段输出;
4 、接入层负责负载均衡;
5 、多机房部署也无法通过 rsync 同步,而是使用部署多套相同的架构来实现。
该方案主要缺点:
1 、碎片文件太多,导致如无法 rsync ;
2 、机械盘做 SSI 合并时,高并发时性能差,此时我们还没有尝试使用 SSD ;
3 、模板如果要变更,数亿商品需要数天才能刷完;
4 、到达容量瓶颈时,我们会删除一部分静态化商品,然后通过动态渲染输出,动态渲染系统在高峰时会导致依赖系统压力大,抗不住;
5 、还是无法迅速响应一些业务需求。
我们的痛点
1 、之前架构的问题存在容量问题,很快就会出现无法全量静态化,还是需要动态渲染;不过对于全量静态化可以通过分布式文件系统解决该问题,这种方案没有尝试;
2 、最主要的问题是随着业务的发展,无法满足迅速变化、还有一些变态的需求。
架构3.0
我们要解决的问题:
1 、能迅速响瞬变的需求,和各种变态需求;
2 、支持各种垂直化页面改版;
3 、页面模块化;
4 、 AB 测试;
5 、高性能、水平扩容;
6 、多机房多活、异地多活。

主要思路:
1 、数据变更还是通过 MQ 通知;
2 、数据异构 Worker 得到通知,然后按照一些维度进行数据存储,存储到数据异构 JIMDB 集群( JIMDB : Redis+ 持久化引擎),存储的数据都是未加工的原子化数据,如商品基本信息、商品扩展属性、商品其他一些相关信息、商品规格参数、分类、商家信息等;
3 、数据异构 Worker 存储成功后,会发送一个 MQ 给数据同步 Worker ,数据同步 Worker 也可以叫做数据聚合 Worker ,按照相应的维度聚合数据存储到相应的 JIMDB 集群;三个维度:基本信息(基本信息 + 扩展属性等的一个聚合)、商品介绍( PC 版、移动版)、其他信息(分类、商家等维度,数据量小,直接 Redis 存储);
4 、前端展示分为两个:商品详情页和商品介绍,使用 Nginx+Lua 技术获取数据并渲染模板输出。
另外我们目前架构的目标不仅仅是为商品详情页提供数据,只要是 Key-Value 获取的而非关系的我们都可以提供服务,我们叫做动态服务系统。

该动态服务分为前端和后端,即公网还是内网,如目前该动态服务为列表页、商品对比、微信单品页、总代等提供相应的数据来满足和支持其业务。
详情页架构设计原则
1 、数据闭环
2 、数据维度化
3 、拆分系统
4 、 Worker 无状态化 + 任务化
5 、异步化 + 并发化
6 、多级缓存化
7 、动态化
8 、弹性化
9 、降级开关
10 、多机房多活
11 、多种压测方案
数据闭环
 数据闭环即数据的自我管理,或者说是数据都在自己系统里维护,不依赖于任何其他系统,去依赖化;这样得到的好处就是别人抖动跟我没关系。
数据闭环即数据的自我管理,或者说是数据都在自己系统里维护,不依赖于任何其他系统,去依赖化;这样得到的好处就是别人抖动跟我没关系。
数据异构,是数据闭环的第一步,将各个依赖系统的数据拿过来,按照自己的要求存储起来;
数据原子化,数据异构的数据是原子化数据,这样未来我们可以对这些数据再加工再处理而响应变化的需求;
数据聚合,将多个原子数据聚合为一个大 JSON 数据,这样前端展示只需要一次 get ,当然要考虑系统架构,比如我们使用的 Redis 改造, Redis 又是单线程系统,我们需要部署更多的 Redis 来支持更高的并发,另外存储的值要尽可能的小;
数据存储,我们使用 JIMDB , Redis 加持久化存储引擎,可以存储超过内存 N 倍的数据量,我们目前一些系统是 Redis+LMDB 引擎的存储,目前是配合 SSD 进行存储;另外我们使用 Hash Tag 机制把相关的数据哈希到同一个分片,这样 mget 时不需要跨分片合并。
我们目前的异构数据时键值结构的,用于按照商品维度查询,还有一套异构时关系结构的用于关系查询使用。
详情页架构设计原则 / 数据维度化
对于数据应该按照维度和作用进行维度化,这样可以分离存储,进行更有效的存储和使用。我们数据的维度比较简单:
1 、商品基本信息,标题、扩展属性、特殊属性、图片、颜色尺码、规格参数等;
2 、商品介绍信息,商品维度商家模板、商品介绍等;
3 、非商品维度其他信息,分类信息、商家信息、店铺信息、店铺头、品牌信息等;
4 、商品维度其他信息(异步加载),价格、促销、配送至、广告词、推荐配件、最佳组合等。
拆分系统
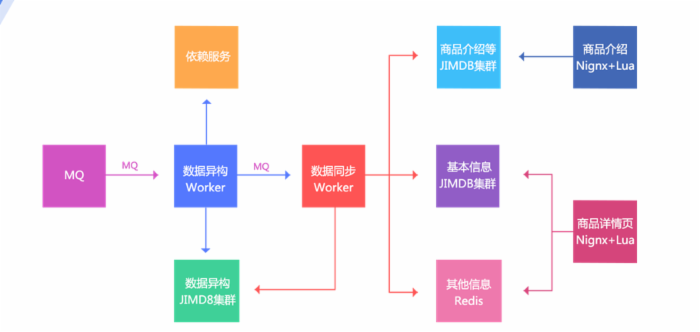 将系统拆分为多个子系统虽然增加了复杂性,但是可以得到更多的好处,比如数据异构系统存储的数据是原子化数据,这样可以按照一些维度对外提供服务;而数据同步系统存储的是聚合数据,可以为前端展示提供高性能的读取。而前端展示系统分离为商品详情页和商品介绍,可以减少相互影响;目前商品介绍系统还提供其他的一些服务,比如全站异步页脚服务。
将系统拆分为多个子系统虽然增加了复杂性,但是可以得到更多的好处,比如数据异构系统存储的数据是原子化数据,这样可以按照一些维度对外提供服务;而数据同步系统存储的是聚合数据,可以为前端展示提供高性能的读取。而前端展示系统分离为商品详情页和商品介绍,可以减少相互影响;目前商品介绍系统还提供其他的一些服务,比如全站异步页脚服务。
Worker无状态化+任务化
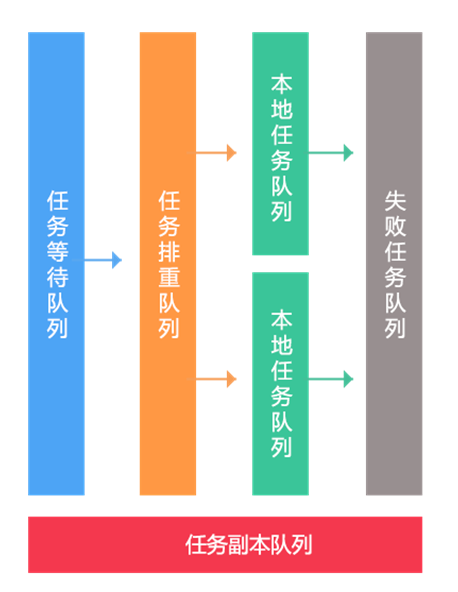
1 、数据异构和数据同步 Worker 无状态化设计,这样可以水平扩展;
2 、应用虽然是无状态化的,但是配置文件还是有状态的,每个机房一套配置,这样每个机房只读取当前机房数据;
3 、任务多队列化,等待队列、排重队列、本地执行队列、失败队列;
4 、队列优先级化,分为:普通队列、刷数据队列、高优先级队列;例如一些秒杀商品会走高优先级队列保证快速执行;
5 、副本队列,当上线后业务出现问题时,修正逻辑可以回放,从而修复数据;可以按照比如固定大小队列或者小时队列设计;
6 、在设计消息时,按照维度更新,比如商品信息变更和商品上下架分离,减少每次变更接口的调用量,通过聚合 Worker 去做聚合。
多级缓存化
浏览器缓存,当页面之间来回跳转时走 local cache ,或者打开页面时拿着 Last-Modified 去 CDN 验证是否过期,减少来回传输的数据量;
CDN 缓存,用户去离自己最近的 CDN 节点拿数据,而不是都回源到北京机房获取数据,提升访问性能;
服务端应用本地缓存,我们使用 Nginx+Lua 架构,使用 HttpLuaModule 模块的 shared dict 做本地缓存( reload 不丢失)或内存级 Proxy Cache ,从而减少带宽;
另外我们还使用使用一致性哈希(如商品编号 / 分类)做负载均衡内部对 URL 重写提升命中率;
我们对 mget 做了优化,如去商品其他维度数据,分类、面包屑、商家等差不多 8 个维度数据,如果每次 mget 获取性能差而且数据量很大, 30KB 以上;而这些数据缓存半小时也是没有问题的,因此我们设计为先读 local cache ,然后把不命中的再回源到 remote cache 获取,这个优化减少了一半以上的 remote cache 流量;
服务端分布式缓存,我们使用内存 +SSD+JIMDB 持久化存储。
详情页架构设计原则 / 动态化
数据获取动态化,商品详情页:按维度获取数据,商品基本数据、其他数据(分类、商家信息等);而且可以根据数据属性,按需做逻辑,比如虚拟商品需要自己定制的详情页,那么我们就可以跳转走,比如全球购的需要走 jd.hk 域名,那么也是没有问题的;
模板渲染实时化,支持随时变更模板需求;
重启应用秒级化,使用 Nginx+Lua 架构,重启速度快,重启不丢共享字典缓存数据;
需求上线速度化,因为我们使用了 Nginx+Lua 架构,可以快速上线和重启应用,不会产生抖动;另外 Lua 本身是一种脚本语言,我们也在尝试把代码如何版本化存储,直接内部驱动 Lua 代码更新上线而不需要重启 Nginx 。
弹性化
我们所有应用业务都接入了 Docker 容器,存储还是物理机;我们会制作一些基础镜像,把需要的软件打成镜像,这样不用每次去运维那安装部署软件了;未来可以支持自动扩容,比如按照 CPU 或带宽自动扩容机器,目前京东一些业务支持一分钟自动扩容。
降级开关
推送服务器推送降级开关,开关集中化维护,然后通过推送机制推送到各个服务器;
可降级的多级读服务,前端数据集群 ---> 数据异构集群 ---> 动态服务 ( 调用依赖系统 ) ;这样可以保证服务质量,假设前端数据集群坏了一个 磁盘,还可以回源到数据异构集群获取数据;
开关前置化,如 Nginx-- à Tomcat ,在 Nginx 上做开关,请求就到不了后端,减少后端压力;
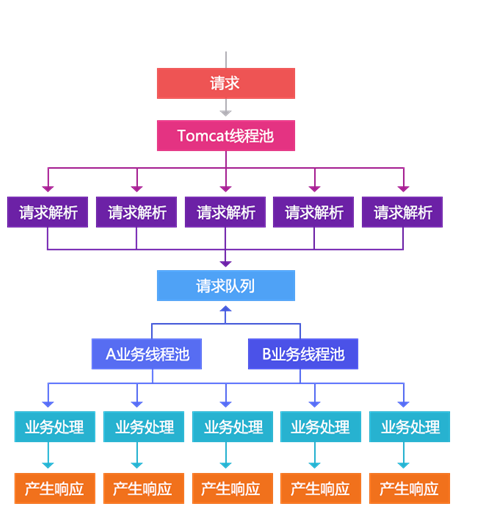
可降级的业务线程池隔离,从 Servlet3 开始支持异步模型, Tomcat7/Jetty8 开始支持,相同的概念是 Jetty6 的 Continuations 。我们可以把处理过程分解为一个个的事件。通过这种将请求划分为事件方式我们可以进行更多的控制。如,我们可以为不同的业务再建立不同的线程池进行控制:即我们只依赖 tomcat 线程池进行请求的解析,对于请求的处理我们交给我们自己的线程池去完成;这样 tomcat 线程池就不是我们的瓶颈,造成现在无法优化的状况。通过使用这种异步化事件模型,我们可以提高整体的吞吐量,不让慢速的 A 业务处理影响到其他业务处理。慢的还是慢,但是不影响其他的业务。我们通过这种机制还可以把 tomcat 线程池的监控拿出来,出问题时可以直接清空业务线程池,另外还可以自定义任务队列来支持一些特殊的业务。
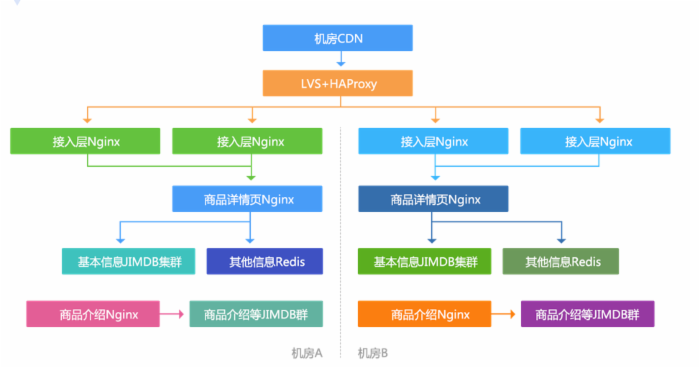
多机房多活
应用无状态,通过在配置文件中配置各自机房的数据集群来完成数据读取。
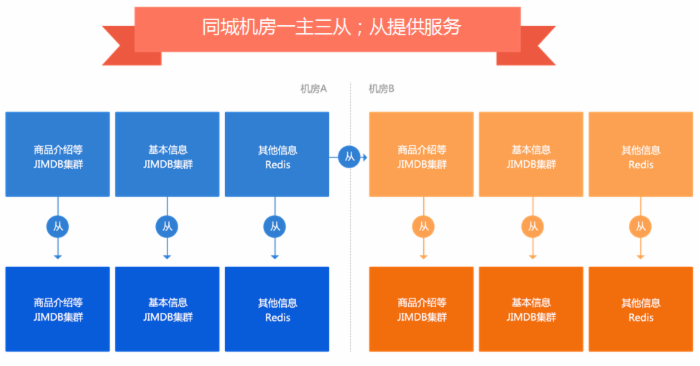
数据集群采用一主三从结构,防止当一个机房挂了,另一个机房压力大产生抖动。
多种压测方案
线下压测, Apache ab , Apache Jmeter ,这种方式是固定 url 压测,一般通过访问日志收集一些 url 进行压测,可以简单压测单机峰值吞吐量,但是不能作为最终的压测结果,因为这种压测会存在热点问题;
线上压测,可以使用 Tcpcopy 直接把线上流量导入到压测服务器,这种方式可以压测出机器的性能,而且可以把流量放大,也可以使用 Nginx+Lua 协程机制把流量分发到多台压测服务器,或者直接在页面埋点,让用户压测,此种压测方式可以不给用户返回内容。
遇到的一些坑和问题
SSD性能差
使用 SSD 做 KV 存储时发现磁盘 IO 非常低。配置成 RAID10 的性能只有 3~6MB/s ;配置成 RAID0 的性能有 ~130MB/s ,系统中没有发现 CPU , MEM ,中断等瓶颈。一台服务器从 RAID1 改成 RAID0 后,性能只有 ~60MB/s 。这说明我们用的 SSD 盘性能不稳定。
根据以上现象,初步怀疑以下几点: SSD 盘,线上系统用的三星 840Pro 是消费级硬盘。 RAID 卡设置, Write back 和 Write through 策略。后来测试验证,有影响,但不是关键。 RAID 卡类型,线上系统用的是 LSI 2008 ,比较陈旧。
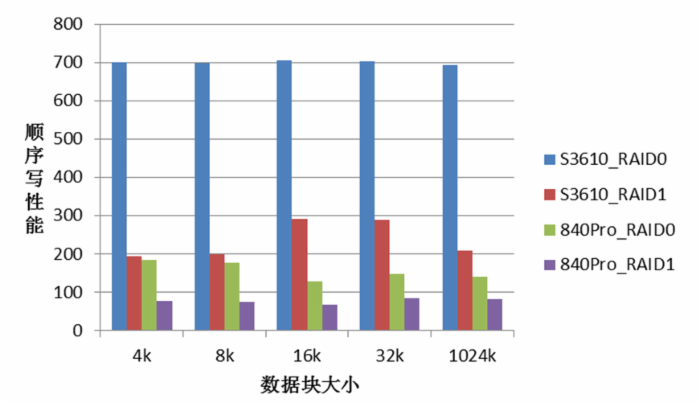
本实验使用 dd 顺序写操作简单测试,严格测试需要用 FIO 等工具。
键值存储选型压测
我们对于存储选型时尝试过 LevelDB 、 RocksDB 、 BeansDB 、 LMDB 、 Riak 等,最终根据我们的需求选择了 LMDB 。
机器: 2 台
配置: 32 核 CPU 、 32GB 内存、 SSD ( (512GB) 三星 840Pro--> (600GB)Intel 3500 /Intel S3610 )
数据: 1.7 亿数据( 800 多 G 数据)、大小 5~30KB 左右
KV 存储引擎: LevelDB 、 RocksDB 、 LMDB ,每台启动 2 个实例
压测工具: tcpcopy 直接线上导流
压测用例:随机写 + 随机读
LevelDB 压测时,随机读 + 随机写会产生抖动(我们的数据出自自己的监控平台,分钟级采样)。

RocksDB 是改造自 LevelDB ,对 SSD 做了优化,我们压测时单独写或读,性能非常好,但是读写混合时就会因为归并产生抖动。
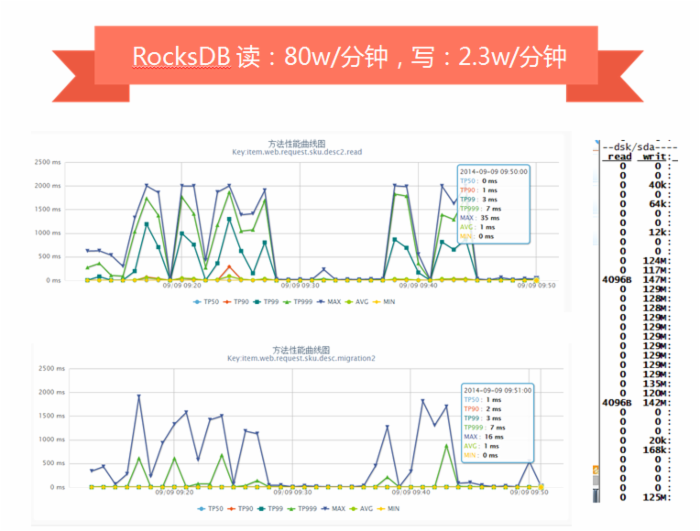
LMDB 引擎没有大的抖动,基本满足我们的需求。
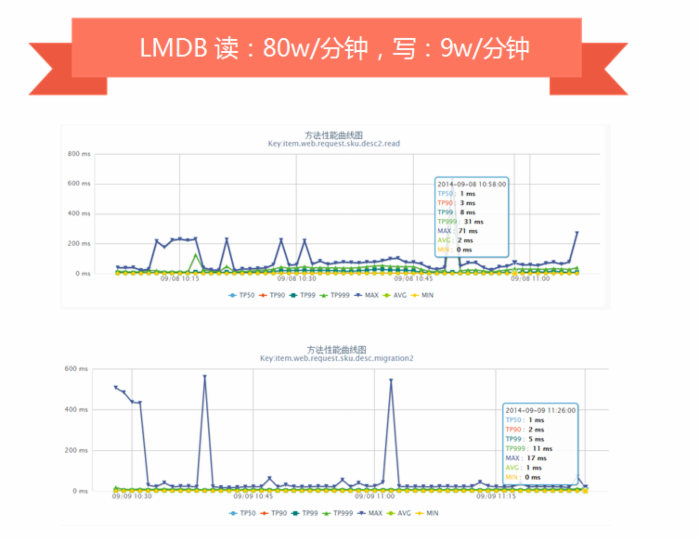
我们目前一些线上服务器使用的是 LMDB ,其他一些正在尝试公司自主研发的 CycleDB 引擎。
数据量大时JIMDB同步不动
Jimdb 数据同步时要 dump 数据, SSD 盘容量用了 50% 以上, dump 到同一块磁盘容量不足。解决方案:
1 、一台物理机挂 2 块 SSD(512GB) ,单挂 raid0 ;启动 8 个 jimdb 实例;这样每实例差不多 125GB 左右;目前是挂 4 块, raid0 ;新机房计划 8 块 raid10 ;
2 、目前是千兆网卡同步,同步峰值在 100MB/s 左右;
3 、 dump 和 sync 数据时是顺序读写,因此挂一块 SAS 盘专门来同步数据;
4 、使用文件锁保证一台物理机多个实例同时只有一个 dump ;
5 、后续计划改造为直接内存转发而不做 dump 。
切换主从
之前存储架构是一主二从(主机房一主一从,备机房一从)切换到备机房时,只有一个主服务,读写压力大时有抖动,因此我们改造为之前架构图中的一主三从。
分片配置
之前的架构是分片逻辑分散到多个子系统的配置文件中,切换时需要操作很多系统;解决方案:
1 、引入 Twemproxy 中间件,我们使用本地部署的 Twemproxy 来维护分片逻辑;
2 、使用自动部署系统推送配置和重启应用,重启之前暂停 mq 消费保证数据一致性;
3 、用 unix domain socket 减少连接数和端口占用不释放启动不了服务的问题。
模板元数据存储HTML
起初不确定 Lua 做逻辑和渲染模板性能如何,就尽量减少 for 、 if/else 之类的逻辑;通过 java worker 组装 html 片段存储到 jimdb , html 片段会存储诸多问题,假设未来变了也是需要全量刷出的,因此存储的内容最好就是元数据。因此通过线上不断压测,最终 jimdb 只存储元数据, lua 做逻辑和渲染;逻辑代码在 3000 行以上;模板代码 1500 行以上,其中大量 for 、 if/else ,目前渲染性能可以接受。
线上真实流量,整体性能从 TP99 53ms 降到 32ms 。
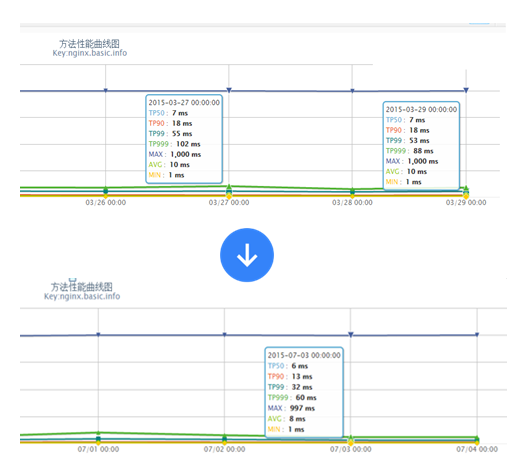
绑定 8 CPU 测试的,渲染模板的性能可以接受。
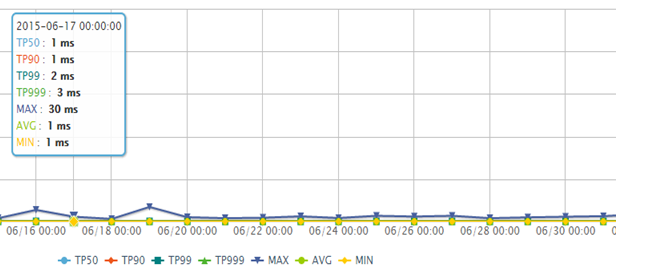
库存接口访问量600w/分钟
商品详情页库存接口 2014 年被恶意刷,每分钟超过 600w 访问量, tomcat 机器只能定时重启;因为是详情页展示的数据,缓存几秒钟是可以接受的,因此开启 nginx proxy cache 来解决该问题,开启后降到正常水平;我们目前正在使用 Nginx+Lua 架构改造服务,数据过滤、 URL 重写等在 Nginx 层完成,通过 URL 重写 + 一致性哈希负载均衡,不怕随机 URL ,一些服务提升了 10%+ 的缓存命中率。
微信接口调用量暴增
通过访问日志发现某 IP 频繁抓取;而且按照商品编号遍历,但是会有一些不存在的编号;解决方案:
1 、读取 KV 存储的部分不限流;
2 、回源到服务接口的进行请求限流,保证服务质量。
开启Nginx Proxy Cache性能不升反降
开启 Nginx Proxy Cache 后,性能下降,而且过一段内存使用率到达 98% ;解决方案:
1 、对于内存占用率高的问题是内核问题,内核使用 LRU 机制,本身不是问题,不过可以通过修改内核参数
sysctl -w vm.extra_free_kbytes=6436787
sysctl -w vm.vfs_cache_pressure=10000
2 、使用 Proxy Cache 在机械盘上性能差可以通过 tmpfs 缓存或 nginx 共享字典缓存元数据,或者使用 SSD ,我们目前使用内存文件系统。
配送至读服务因依赖太多,响应时间偏慢
配送至服务每天有数十亿调用量,响应时间偏慢。解决方案:
1 、串行获取变并发获取,这样一些服务可以并发调用,在我们某个系统中能提升一倍多的性能,从原来 TP99 差不多 1s 降到 500ms 以下;
2 、预取依赖数据回传,这种机制还一个好处,比如我们依赖三个下游服务,而这三个服务都需要商品数据,那么我们可以在当前服务中取数据,然后回传给他们,这样可以减少下游系统的商品服务调用量,如果没有传,那么下游服务再自己查一下。
假设一个读服务是需要如下数据:
1 、数据 A 10ms
2 、数据 B 15ms
3 、数据 C 20ms
4 、数据 D 5ms
5 、数据 E 10ms
那么如果串行获取那么需要: 60ms ;
而如果数据 C 依赖数据 A 和数据 B 、数据 D 谁也不依赖、数据 E 依赖数据 C ;那么我们可以这样子来获取数据:
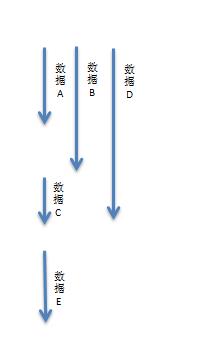
那么如果并发化获取那么需要: 30ms ;能提升一倍的性能。
假设数据 E 还依赖数据 F(5ms) ,而数据 F 是在数据 E 服务中获取的,此时就可以考虑在此服务中在取数据 A/B/D 时预取数据 F ,那么整体性能就变为了: 25ms 。
通过这种优化我们服务提升了差不多 10ms 性能。
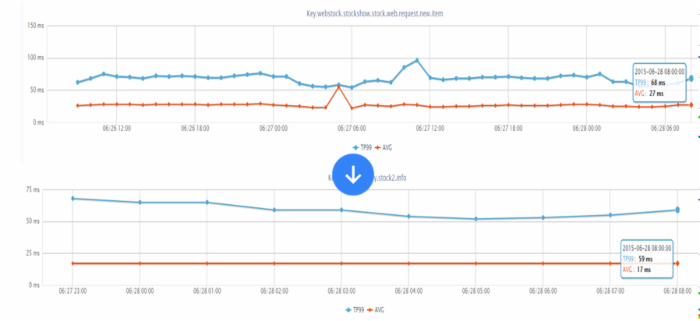
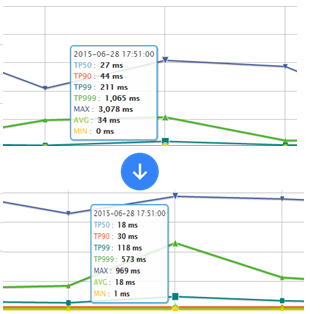
如下服务是在抖动时的性能,老服务 TP99 211ms ,新服务 118ms ,此处我们主要就是并发调用 + 超时时间限制,超时直接降级。
网络抖动时,返回502错误
Twemproxy 配置的 timeout 时间太长,之前设置为 5s ,而且没有分别针对连接、读、写设置超时。后来我们减少超时时间,内网设置在 150ms 以内,当超时时访问动态服务。
机器流量太大
2014 年双 11 期间,服务器网卡流量到了 400Mbps , CPU 30% 左右。原因是我们所有压缩都在接入层完成,因此接入层不再传入相关请求头到应用,随着流量的增大,接入层压力过大,因此我们把压缩下方到各个业务应用,添加了相应的请求头, Nginx GZIP 压缩级别在 2~4 吞吐量最高;应用服务器流量降了差不多 5 倍;目前正常情况 CPU 在 4% 以下。

总结
数据闭环
数据维度化
拆分系统
Worker 无状态化 + 任务化
异步化 + 并发化
多级缓存化
动态化
弹性化
降级开关
多机房多活
多种压测方案
Nginx 接入层线上灰度引流
接入层转发时只保留有用请求头
使用不需要 cookie 的无状态域名(如 c.3.cn ),减少入口带宽
Nginx Proxy Cache 只缓存有效数据,如托底数据不缓存
使用非阻塞锁应对 local cache 失效时突发请求到后端应用 (lua-resty-lock/proxy_cache_lock)
使用 Twemproxy 减少 Redis 连接数
使用 unix domain socket 套接字减少本机 TCP 连接数
设置合理的超时时间(连接、读、写)
使用长连接减少内部服务的连接数
去数据库依赖(协调部门迁移数据库是很痛苦的,目前内部使用机房域名而不是 ip ),服务化
客户端同域连接限制,进行域名分区: c0.3.cn c1.3.cn ,如果未来支持 HTTP/2.0 的话,就不再适用了。
正文到此结束
- 本文标签: 实例 CDN 总结 集群 管理 定制 域名 tomcat value 线程 src zip 配置 时间 remote DOM 负载均衡 锁 标题 redis 服务器 Apache ab servlet key 广告 线下 java 安装 需求 端口 遍历 js 参数 网站 数据 Nginx JMeter jetty Docker 数据库 SQL Server sql 代码 unix 解析 网卡 REST cat UI apache TCP 质量 json 同步 京东 HTTP/2 测试 HTML ip 软件 压力 系统架构 rsync 响应式 db
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

