弹性MapReduce 4.0.0版本发布,更新应用已可用
Amazon EMR 是一个托管的集群平台,它简化了大数据框架(如 Apache Hadoop 和 Apache Spark )在AWS上的运行,可以处理和分析大量的数据。通过使用这些框架和相关的开源软件,如 Apache Hive 和 Apache Pig ,你可以处理数据,实现分析的目的和处理商业智能负荷。最先是在2009年投放市场(详见博客帖 Announcing Amazon Elastic MapReduce ),从那时起我们已经增添了综合的控制台支持和很多很多的特性。一些最新的特性包括:
- 支持 S3加密 (服务器侧和客户端侧)
- 对 EMRFS (EMR文件系统)的持续关注
- 通过 Hive/DynamoDB Connector (Hive/DynamoDB连接器)进行的数据导入,导出和查询
- 增强的 CloudWatch 测量指标
今天我们要发布Amazon EMR 4.0.0版本。该版本对平台做了很多改进。它包含了Hadoop生态系统应用和Spark的很多更新版本,这些更新后的版本可以安装在集群中,改善应用配置体验。作为该版本的一部分,我们也调整了一些端口和路径以便更好地与一些Hadoop和Spark标准和约定对齐。与其他未出现在离散版本中,需要在后台频繁地更新的AWS业务不同,EMR拥有版本化的更新以便你可以利用特定EMR版本发布的特性或应用来写程序和脚本。
如果你正在使用AMI 2.x或3.x版本,请阅读 EMR Release Guide (EMR版本指南),了解如何迁移到4.0.0版本。
应用更新
EMR用户从Hadoop生态系统访问很多应用。EMR 4.0.0版本在以下方面做了更新:
- Hadoop 2.6.0–Hadoop 的这一版本包含了很多常规功能和易用性优化。
- Hive 1.0–Hive 的这一版本包含了性能增强,额外的SQL支持和一些新的安全特性。
- Pig 0.14–Pig 的这一版本特点是一个全新的ORCStorage等级,谓词下推以便改进性能,漏洞修复等等。
- Spark 1.4.1–Spark 的这一版本包含SparkR和全新的Dataframe API的绑定,以及很多小特性和漏洞修复。
控制台快速集群创建
你现在可以从控制台使用Quick cluster configuration页面创建EMR集群了:

改进的应用配置编辑
在Amazon EMR AMI 2.x和3.x版本中,引导动作主要用来在集群中配置应用。随着Amazon EMR 4.0.0版本的发布,我们已经改善了配置体验,在创建集群时提供直接的方法编辑应用的默认配置。我们已经能够将包含待编辑配置文件的清单和待修改文件中的配置信息进行传递。你可以创建一个配置对象,从 CLI , EMR API 或控制台引用该对象。你可以在本地存储配置信息或将信息存储在S3中并提供对该信息的引用(如果你正在使用控制台,创建集群时,点击 Go to advanced options 设置配置值或使用配置文件):
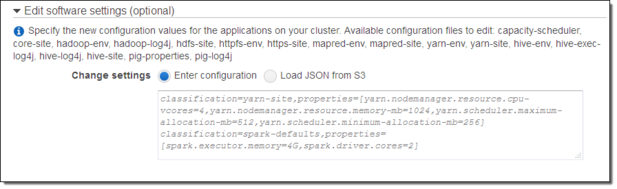
想要了解更多信息,请参阅 Configuring Applications (配置应用)。
新的打包体系/标准端口和路径
我们现在的版本打包系统是基于 Apache Bigtop 的。你可以增添新应用并更快地将新应用添加到EMR中。
我们也在EMR 4.0.0版本中对大部分端口和路径使用了开源标准。想要了解这些变化的更多信息,请参阅 Differences Introduced in 4.x (4.x版本中引进的新变化)。
EMR团队让我分享一些技术技巧:
Spark on YARN 能够动态地伸缩Spark应用所使用的执行器的数量。你仍然需要在spark-defaults配置文件中设置执行器可用的内存(通过spark.executor.memory参数设置)和核数(通过spark.executor.cores参数设置),但是YARN将会自动地向Spark应用分配所需数量的执行器。想要启动执行器的动态分配功能,将spark-defaults配置文件中spark.dynamicAllocation.enabled的值设为true。此外,Spark shuffle业务在Amazon EMR中默认开启,所以你不需要再开启这项业务。
在创建集群时,你可以将maximizeResourceAllocation选项设置为true,从而配置执行器尽可能利用每个节点上最多的资源。你也可以在创建集群时在配置对象中将这一属性添加到“spark”分类中从而实现这一选项设置。该选项计算核心节点组每一个节点上的每一个执行器的最大计算能力和可用的内存资源最大量,并使用该信息设置spark-defaults文件中的相应配置。它也设置执行器的数量,通过将spark.executor.instances设置为集群创建时设定的最初核心节点来实现。但是,请注意,你不能使用该设置,你同时也必须启动执行器的动态分配。
想要了解这些选项的更多信息,请参阅 Configure Spark (配置Spark) .
现在可用以上所列的所有特性现在都可用了,你今天就可以开始使用它们了。如果你是大规模数据处理和EMR的新手,请阅读 Getting Started with Amazon EMR (Amazon EMR入门)页。你将会发现一个新的教学视频和关于训练和专业服务的信息,所有这些都旨在帮助你了解EMR 4.0.0并快速有效地运行它。
原文链接: https://aws.amazon.com/cn/blogs/aws/elastic-mapreduce-release-4-0-0-with-updated-applications-now-available/?sc_campaign=launch&sc_category=emr&sc_channel=SM&sc_content=400&sc_detail=std&sc_medium=aws&sc_publisher=tw_go
活动推荐:08月27日 AWS 云计算环境中的Microservices 架构
活动推荐: AWS架构师全面解读运维与架构 - 微服务&无缝迁移
( 翻译/吕冬梅 责编/王鑫贺 )
 订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
AWS中文技术社区为广大开发者提供了一个Amazon Web Service技术交流平台 ,推送AWS最新资讯、技术视频、技术文档、精彩技术博文等相关精彩内容,更有AWS社区专家与您直接沟通交流!快加入AWS中文技术社区,更快更好的了解AWS云计算技术。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

