scrapy入门教程2:建立一个简单的爬取南邮新闻标题的爬虫demo
0. 基本环境说明
-
本文截图及运行环境均在MAC OS X 10.9.5上实现,但基本步骤与win 7环境上相同(其实我是先在win7折腾了一把,然后为了写这篇教程,又在OS X 上面重新搞了一遍)
-
scrapy版本为1.0
-
参考文献以及下载链接:
-
本爬虫参考代码打包下载
-
1. 建立步骤
通过上一篇内容我们已经将scrapy环境配置完毕,下面我们来实现一个demo来爬取南京邮电大学新闻页面的内容。
1. 创建一个新工程
scrapy startproject njupt #其中njupt是项目名称,可以按照个人喜好来定义 输入以上命令之后,就会看见命令行运行的目录下多了一个名为 ` njupt ` 的目录,目录的结构如下:
|---- njupt | |---- njupt | |---- __init__.py | |---- items.py #用来存储爬下来的数据结构(字典形式) | |---- pipelines.py #用来对爬出来的item进行后续处理,如存入数据库等 | |---- settings.py #爬虫配置文件 | |---- spiders #此目录用来存放创建的新爬虫文件(爬虫主体) | |---- __init__.py | |---- scrapy.cfg #项目配置文件 至此,工程创建完毕。
2. 设置 items
本文以抓取南邮新闻为例,需要存储三种信息:
-
南邮新闻标题
-
南邮新闻时间
-
南邮新闻的详细链接
items内部代码如下:
# -*- coding: utf-8 -*- import scrapy class NjuptItem(scrapy.Item): #NjuptItem 为自动生成的类名 news_title = scrapy.Field() #南邮新闻标题 news_date = scrapy.Field() #南邮新闻时间 news_url = scrapy.Field() #南邮新闻的详细链接 至于为什么每一句都用 scrapy.Field() ,这个等请关注我的后续教程,现在只要记住按照以上的格式来添加新的要提取的属性就可以了~。
3. 编写 spider
spider是爬虫的主体,负责处理requset response 以及url等内容,处理完之后交给pipelines进行进一步处理。
设置完items之后,就在spiders目录下新建一个 njuptSpider.py 文件,内容如下:
# -*- coding: utf-8 -*- import scrapy from njupt.items import NjuptItem import logging class njuptSpider(scrapy.Spider): name = "njupt" allowed_domains = ["njupt.edu.cn"] start_urls = [ "http://news.njupt.edu.cn/s/222/t/1100/p/1/c/6866/i/1/list.htm", ] def parse(self, response): news_page_num = 14 page_num = 386 if response.status == 200: for i in range(2,page_num+1): for j in range(1,news_page_num+1): item = NjuptItem() item['news_url'],item['news_title'],item['news_date'] = response.xpath( "//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/font/text()" "|//div[@id='newslist']/table[1]/tr["+str(j)+"]//td[@class='postTime']/text()" "|//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/@href").extract() yield item next_page_url = "http://news.njupt.edu.cn/s/222/t/1100/p/1/c/6866/i/"+str(i)+"/list.htm" yield scrapy.Request(next_page_url,callback=self.parse_news) def parse_news(self, response): news_page_num = 14 if response.status == 200: for j in range(1,news_page_num+1): item = NjuptItem() item['news_url'],item['news_title'],item['news_date'] = response.xpath( "//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/font/text()" "|//div[@id='newslist']/table[1]/tr["+str(j)+"]//td[@class='postTime']/text()" "|//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/@href").extract() yield item 其中
-
name为爬虫名称,在后面启动爬虫的命令当中会用到。 -
allowed_domains为允许爬虫爬取的域名范围(如果连接到范围以外的就不爬取) -
start_urls表明爬虫首次启动之后访问的第一个Url,其结果会被自动返回给parse函数。4. -
parse函数为scrapy框架中定义的置函数,用来处理请求start_urls之后返回的response,由我们实现 -
news_page_num = 14和page_num = 386别表示每页的新闻数目,和一共有多少页,本来也可以通过xpath爬取下来的,但是我实在是对我们学校的网站制作无语了,html各种混合,于是我就偷懒手动输入了。 -
之后通过
`item = NjuptItem()`来使用我们之前定义的item,用来存储新闻的url、标题、日期。(这里面有一个小技巧就是通过|来接连xpath可以一次返回多个想要抓取的xpath) -
通过
yield item来将存储下来的item交由后续的pipelines处理 -
之后通过生成
next_page_url来通过scrapy.Request抓取下一页的新闻信息 -
scrapy.Request的两个参数,一个是请求的URL另外一个是回调函数用于处理这个request的response,这里我们的回调函数是parse_news -
parse_news里面的步骤和parse差不多,当然你也可以改造一下parse然后直接将其当做回调函数,这样的话一个函数就ok了
4. 编写 pipelines
初次编写可以直接编辑 njupt 目录下的 pipelines.py 文件。pipelines主要用于数据的进一步处理,比如类型转换、存储入数据库、写到本地等。
本爬虫pipelines如下:
import json class NjuptPipeline(object): def __init__(self): self.file = open('njupt.txt',mode='wb') def process_item(self, item, spider): self.file.write(item['news_title'].encode("GBK")) self.file.write("/n") self.file.write(item['news_date'].encode("GBK")) self.file.write("/n") self.file.write(item['news_url'].encode("GBK")) self.file.write("/n") return item 其实 pipelines 是在每次 spider 中 yield item 之后调用,用于处理每一个单独的 item 。上面代码就是实现了在本地新建一个 njupt.txt 文件用于存储爬取下来的内容。
5. 编写 settings.py
settings.py 文件用于存储爬虫的配置,有很多种配置,由于是入门教程,不需要配置很多,我们这里就添加一下刚才编写的pipelines就行了。文件内容如下。
BOT_NAME = 'njupt' SPIDER_MODULES = ['njupt.spiders'] NEWSPIDER_MODULE = 'njupt.spiders' ITEM_PIPELINES = { 'njupt.pipelines.NjuptPipeline':1, }6. 启动爬虫与查看结果
以上步骤全部完成之后,我们就启动命令行,然后切换运行目录到 njupt 的 spider 目录下,通过以下命令启动爬虫
scrapy crawl njupt经过一段时间的风狂爬取,爬虫结束。会报一些统计信息

最后让我们来查看一下爬取成果
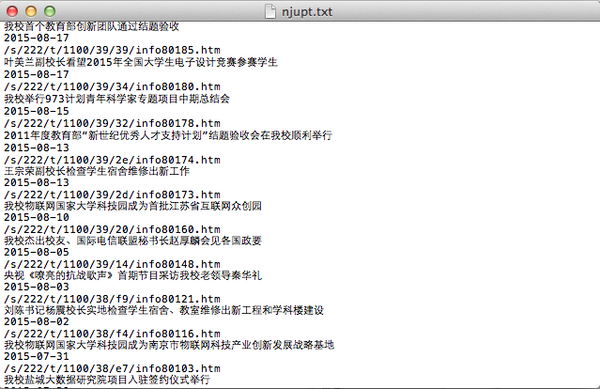
至此,大功告成~
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

