Java 8最快的垃圾搜集器是什么?
OpenJDK 8 有多种 GC(Garbage Collector)算法,如 Parallel GC、CMS 和 G1。哪一个才是最快的呢?如果在 Java 9 中将 Java 8 默认的 GC 从 Parallel GC 改为 G1 (目前只是建议)将会怎么样呢?让我们对此进行基准测试。
基准测试方法
运行相同的代码六次,每次使用不同的VM参数(-XX:+UseSerialGC, -XX:+UseParallelGC, -XX:+UseConcMarkSweepGC, -XX:ParallelCMSThreads=2, -XX:ParallelCMSThreads=4, -XX:+UseG1GC)。
每次运行大概花费55分钟。
其它VM参数:-Xmx2048M -server
OpenJDK版本:1.8.0_51(当前最新的版本)
软件:Linux version 4.0.4-301.fc22.x86_64
硬件:Intel? Core? i7-4790 CPU @ 3.60GHz
每次运行13个? OptaPlanner ?规划问题方案。每次运行时间为5分钟。前30秒用于JVM预热,不计算在内。
解决规划问题不涉及 IO (除了启动时需要几毫秒来加载输入信息)。单个 CPU 使用完全饱和。通常会创建许多存活时间很短的对象,GC 之后就会回收这些对象。
衡量标准可以是计算每毫秒的得分,越高越好。计算一个拟议规划解决方案是一个不可小觑的问题:涉及到大量的计算,包括每个实体与其他所有实体的冲突检测。
为了能在本地重复运行这些基准测试,可以从 源码 进行构建,然后运行主类 GeneralOptaPlannerBenchmarkApp。
基准测试结果
执行结果
为了方便查看,我已经对每种 GC 与 Java 8 默认 GC(Parallel GC)进行了比较。
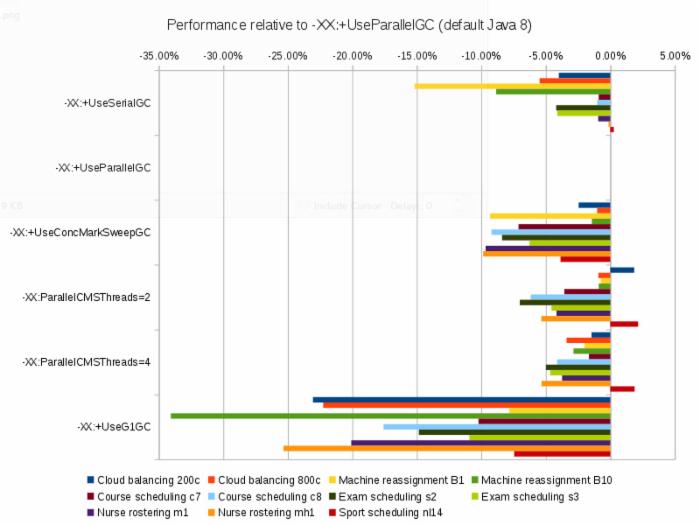
结果非常清楚: 默认(Parallel GC)是最快的 。
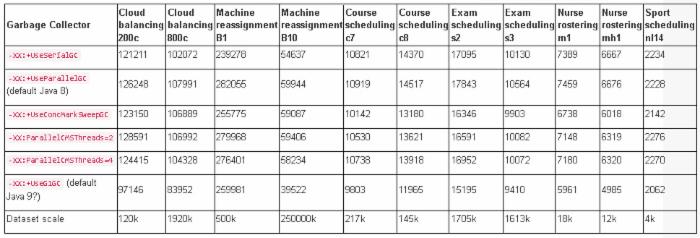
原始基准测试数据
相对基准测试数据
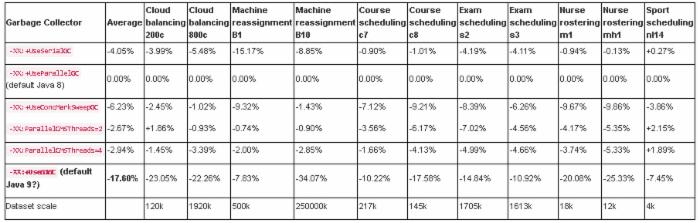
Java 9 默认应该为 G1 吗?
有一种提议是在 OpenJDK9 的服务器端使用 G1 作为默认 GC。我第一反应就是拒绝该提议:
G1 的平均值要慢17.60%
G1 在每个数据集用例下都比较慢。
在最大数据集(Machine Reassignment B10)下,表现比其它数据集都要差,G1 慢了34.07%。
如果在开发机和服务器之间采用不同的默认 GC,则开发者基准测试的可信度就会下降。
另一方面,存在几个需要注意的细节:
G1 关注是 GC 暂停的问题,而不是吞吐量。对于这些用例(计算量比较大),GC 暂停时长基本没影响。
这是一个(基本是)单线程的基准测试。并行解决多个问题或采用多线程解决的基准测试,结果可能不同。
G1 推荐的堆内存至少是 6GB。而这次基准测试的堆内存是 2GB,即使在最大数据集(Machine Reassignment B10)也只需要这么多内存。
海量计算只是 OpenJDK 的诸多功能中的一个:这是在社区广泛争论的一个问题。如果有其他方面(如网站服务)的证明,可能值得改变默认GC。但是,请首先向我展示你实际项目的基准测试。
结论
在 Java 8 中,对 OptaPlanner 用例来说,默认 GC(Parallel GC)通常情况是最好的选择。
原文链接: javacodegeeks 翻译:ImportNew.com -paddx
译文链接:[]正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

