读懂Swift 2.0中字符串设计思路的改变

本文由CocoaChina译者 yake_099 翻译自苹果开发者中心Swift博客
原文: Strings in Swift 2
Swift提供了一种高性能的,兼容Unicode编码的String实现作为标准库的一部分。在Swift2中,String类型不再遵守CollectionType协议。在以前,String类型是字符的一个集合,类似于数组。现在,String类型通过一个characters属性来提供一个字符的集合。
为什么会有这样的变化呢?虽然模拟一个字符串作为字符的集合看起来非常自然,但是String类型与真正的集合类如Array、Set以及Dictionnary等类型表现得完全不同。这是一直都存在的,但是由于Swift2中增加了协议扩展,这些不同就使得很有必要做些基本改变。
不同于部分的总和
当你在集合中添加一个元素时,你希望集合中包含那个元素。也就是说,当你给一个数组增加一个值,这个数组就包含了那个值。这同样适用于Dictionary和Set。无论如何,当你给字符串拼接一个组合标记字符(combing mark character)时,字符串本身的内容就改变了。
比如字符串cafe,它包含了四个字符:c,a,f ,e:
var letters: [Character] = ["c", "a", "f", "e"] var string: String = String(letters) print(letters.count) // 4 print(string) // cafe print(string.characters.count) // 4
如果你在字符串后面拼接了组合重音符号U+0301 ? ,字符串仍然有四个字符,但是最后的字符现在是é:
let acuteAccent: Character = "/u{0301}" // ′ COMBINING ACUTE ACCENT' (U+0301) string.append(acuteAccent) print(string.characters.count) // 4 print(string.characters.last!) // é 字符串的characters属性不包含原始的小写字母 e,它也不包含刚刚拼接的重音符号?,字符串现在是一个带着重音符号的小写字母é:
string.characters.contains("e") // false string.characters.contains("?") // false string.characters.contains("é") // true 如果你想要将字符串像其他集合类型那样看待,这种结果很令人惊讶,就像你在一个集合中添加了UIColor.redColor()和UIColor.greenColor(),但是集合会报告它自己包含了一个UIColor.yellowColor()
通过字符内容判断
字符串与集合之间另一个不同是它们处理“相等”的方式。
-
只有在两个数组的元素个数相同,并且在每一个对应索引位置的元素也相等时两个数组才是相等的。
-
只有在两个集合的元素个数相同,并且第一个集合中包含的元素,第二个集合也包括时两个集合才相等。
-
两个字典只有在有相同的键值对时才相等。
然而,String类型的相等建立在标准相等的基础上。如果两个字符串有相同的语义和外观,即使它们实际上是用不同的Unicode码构成的,它们也是标准相等的。
考虑韩国的书写系统,包含了24个字母,或者叫Jamo,包含了单个的辅音和元音。当写出时这些字母就组成每个音节对应的字符。例如,字符 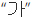
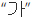 ([ga])是由字母
([ga])是由字母 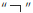 ([g])和
([g])和 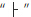

([ga])是由字母 ([g])和 [a]构成的。在Swift中,无论字符串是由分解的还是组合的字符构成的,都被认为是相等的。
这种行为再一次与Swift中的集合类型区别开来。这很令人惊讶就像是数组中的值 ![]() 和
和 ![]() 被认为和
被认为和 ![]() 相等。
相等。
取决于你的视角
字符串不是集合。但是它们确实也提供了许多遵守CollectionType协议的views:
characters是Character类型值的集合,或者扩展字形群集( extended grapheme clusters )
unicodeScalars是Unicode量值的集合( Unicode scalar values )
utf8是UTF-8编码单元的集合( UTF-8 )
utf16是UTF-16编码单元的集合( UTF-16 )
让我们来看之前单词 “café”的例子,由几个单独的字符[ c, a, f, e ] 和 [ ? ]构成,下面是多种字符串的Views中所包含的内容:
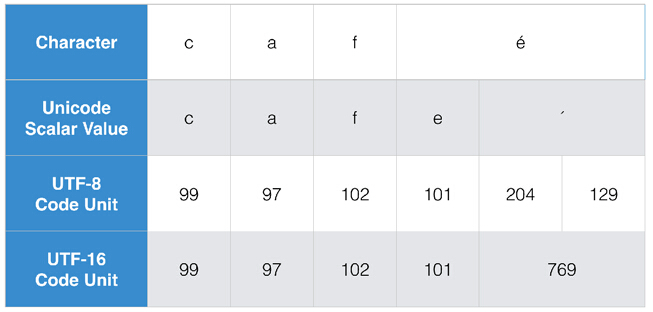
characters属性将文字分段为扩展字形群集,差不多接近用户看到的字符(在这个例子中指c, a, f, 和 é)。由于字符串必须对整个字符串中的每一个位置(称为码位(code point))进行迭代以确定字符的边界,因此取得这个属性的时间复杂度是线性的 O(n)。当处理包含了人类可读文本的字符串,以及上层的本地敏感的Unicode计算程序时,例如用到的localizedStandardCompare(_:)方法和localizedLowercaseString 属性,都需要将字符逐字进行处理。
unicodeScalars属性提供了存储在字符串中的量值,如果原始的字符串是通过字符é而不是e + ?创建的,这就会通过unicodeScalar属性表示出来。当你对数据进行底层操作的时候使用这个API。
utf8和utf16属性对应地提供了它们所代表的代码点(code points),这些值与字符串被转化时写入一个文件中的实际字节数是相一致的,并且来自一种特定的编码方式。
UTF-8 编码单元(code units)被许多 POSIX 的字符串处理 API 所使用,而 UTF-16 编码单元(code units)则始终被用于表示 Cocoa 和 Cocoa Touch中的字符串长度和偏移量。
如果想了解更多 Swift 中关于字符和字符串的信息,请看 The Swift Programming Language 和 The Swift Standard Library Reference .
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

