细细品味大数据--初识hadoop
初识hadoop
前言
之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心放在C++上面了(虽然C++也没怎么学),计划在大四下有空余时间再来慢慢学习。现在实习了,需要这方面的知识,这对于我来说,除去校招时候投递C++职位有少许影响之外,无疑是有很多的好处。
所以,接下来的很长日子,我学习C++之外的很多时间都必须要花在大数据上面了。
那么首先呢,先来认识一下这处理大数据的hadoop工具了。
简述大数据
大数据( big data ) ,是指无法在可承受的时间范围内用常规 软件工具进行捕捉、管理和处理的数据集合。
大数据的 4V 特点: Volume (大量) 、 Velocity (高速) 、 Variety (多样) 、 Value (价值) 。
大数据的价值体现在以下几个方面: 1) 对大量消费者提供产品或服务的企业可以利用大数据进行精准营销 ;2) 做小而美模式的中长尾企业可以利用大数据做服务转型 ;3) 面临互联网压力之下必须转型的传统企业需要与时俱进充分利用大数据的价值。
什么是 Hadoop ?

Hadoop是一个由 Apache 基金会所开发的 分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop 的框架最核心的设计就是: HDFS 和 MapReduce 。 HDFS 为海量的数据提供了存储,则 MapReduce 为海量的数据提供了 处理和计算。
Hadoop 的核心架构
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System ( HDFS ),它存储 Hadoop 集群中所有存储节点上的文件。 HDFS 的上一层是 MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对 Hadoop 分布式计算平台最核心的分布式文件系统 HDFS 、 MapReduce 处理过程,以及数据仓库工具 Hive 和分布式数据库 Hbase 的介绍,基本涵盖了 Hadoop 分布式平台的所有技术核心。
HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。它的主要目的是支持以流的形式访问写入的大型文件(PB 级别 )。可以创建、删除、移动或重命名文件,等等。存储在 HDFS 中的文件被分成块,块的大小(通常为 64MB )和复制的块数量在创建文件时由客户机决定。 但是 HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。 这些节点包括NameNode (仅一个) 和DataNode。
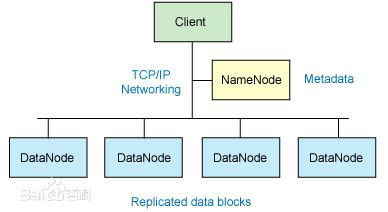
NameNode在 HDFS 内部提供元数据服务 ,它负责管理文件系统名称空间和控制外部客户机的访问。 NameNode 决定是否将文件映射到 DataNode 上的复制块上。 NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统 名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是 EditLog )将存储在 NameNode 的本地文件系统上。 FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失。
DataNode 为 HDFS 提供存储块 , 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。 NameNode 依赖来自每个 DataNode 的定期心跳( heartbeat )消息。每条消息都包含一个块报告, NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息, NameNode 将采取修复措施,重新复制在该节点上丢失的块。
MapReduce
最简单的 MapReduce 应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。 main 函数将 作业控制和文件输入 / 输出结合起来。在这点上, Hadoop 提供了大量的接口和 抽象类,从而为 Hadoop 应用程序开发人员提供许多工具,可用于调试和性能度量等。

MapReduce 本身就是用于 并行处理大数据集的软件框架。 MapReduce 的根源是函数 型编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce )的操作组成。 Map 函数接受一组数据并将其转换为一个键 / 值对 (key-value)列表,输入域中的每个元素对应一个键 / 值对。 Reduce 函数接受 Map 函数生成的列表,然后根据它们的键缩小键 / 值对列表 (即键相同的键/ 值对合并在一起形成一个列表形式 )。
一个代表客户机在单个主系统上启动的 MapReduce 应用程序称为 JobTracker 。类似于 NameNode ,它是 Hadoop 集群中惟一负责控制 MapReduce 应用程序的系统。在应用程序提交之后,将提供包含在 HDFS 中的输入和输出目录。 JobTracker 使用文件块信息(物理量和位置)确定如何创建其他 TaskTracker 从属任务。 MapReduce 应用程序被复制到每个出现输入文件块的节点。将为特定节点上的每个文件块创建一个惟一的从属任务。每个 TaskTracker 将状态和完成信息报告给 JobTracker 。
Hadoop 有什么优势?
Hadoop 是一个能够对大量数据进行 分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新 分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过 并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
总结如下:
高可靠性。 Hadoop 按位存储和处理数据的能力值得人们信赖。
高扩展性。 Hadoop 是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。 Hadoop 能够在节点之间动态地移动数据,并保证各个节点的 动态平衡,因此处理速度非常快。
高容错性。 Hadoop 能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及 QlikView 、 Yonghong Z-Suite 等数据集市相比, hadoop 是开源的,项目的软件成本因此会大大降低。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

