Flume MemoryChannel源码分析
Flume作为Hadoop生态系统中的一员,可以说是功能最大的数据收集系统,Flume的模型也比较简单,通过agent不断级连,来打通数据源端与最钟的目的地(一般为HDFS)。下图结构说明了Flume中的数据流。

我今天要说的是Channel部分,具体来说是MemoryChannel的分析,其他概念像source、sink大家可以去 官方文档 查看。
注意:
本文章中的Flume源码为1.6.0版本。 Event
Event是Flume中对数据的抽象,分为两部分:header与body,和http中的header与body很类似。
Flume中是按Event为单位操作数据,不同的source、sink在必要时会自动在原始数据与Event之间做转化。
Channel
Channel充当了Source与Sink之间的缓冲区。Channel的引入,使得source与sink之间的藕合度降低,source只管像Channel发数据,sink只需从Channel取数据。此外,有了Channel,不难得出下面结论:
-
source与sink可以为N对N的关系
-
source发数据的速度可以大于sink取数据的速度(在Channel不满的情况下)
Transaction
Channel采用了 Transaction (事务)机制来保证数据的完整性,这里的事务和数据库中的事务概念类似,但并不是完全一致,其语义可以参考下面这个图:

source端通过commit操作像Channel放置数据,sink端通过commit操作从Channel取数据。 那么事务是如何保证数据的完整性的呢?看下面有两个agent的情况:
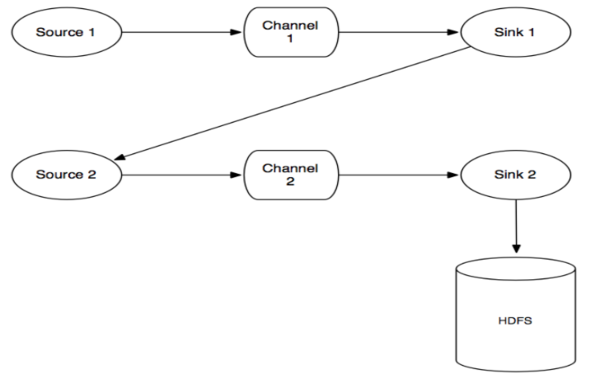
数据流程:
-
source 1产生Event,通过“put”、“commit”操作将Event放到Channel 1中 -
sink 1通过“take”操作从Channel 1中取出Event,并把它发送到Source 2中 -
source 2通过“put”、“commit”操作将Event放到Channel 2中 -
source 2向sink 1发送成功信号,sink 1“commit”步骤2中的“take”操作(其实就是删除Channel 1中的Event)
说明:
在任何时刻,Event至少在一个Channel中是完整有效的 Memory Channe
Flume中提供的Channel实现主要有三个:
-
Memory Channel ,event保存在Java Heap中。如果允许数据小量丢失,推荐使用
-
File Channel ,event保存在本地文件中,可靠性高,但吞吐量低于Memory Channel
-
JDBC Channel ,event保存在关系数据中
不同的Channel主要在于Event存放的位置不同,今天我着重讲一下比较简单的Memory Channel的源码。
首先看一下MemoryChannel中比较重要的成员变量:
// lock to guard queue, mainly needed to keep it locked down during resizes // it should never be held through a blocking operation private Object queueLock = new Object(); //queue为Memory Channel中存放Event的地方,这里用了LinkedBlockingDeque来实现 @GuardedBy(value = "queueLock") private LinkedBlockingDeque<Event> queue; //下面的两个信号量用来做同步操作,queueRemaining表示queue中的剩余空间,queueStored表示queue中的使用空间 // invariant that tracks the amount of space remaining in the queue(with all uncommitted takeLists deducted) // we maintain the remaining permits = queue.remaining - takeList.size() // this allows local threads waiting for space in the queue to commit without denying access to the // shared lock to threads that would make more space on the queue private Semaphore queueRemaining; // used to make "reservations" to grab data from the queue. // by using this we can block for a while to get data without locking all other threads out // like we would if we tried to use a blocking call on queue private Semaphore queueStored; //下面几个变量为配置文件中Memory Channel的配置项 // 一个事务中Event的最大数目 private volatile Integer transCapacity; // 向queue中添加、移除Event的等待时间 private volatile int keepAlive; // queue中,所有Event所能占用的最大空间 private volatile int byteCapacity; private volatile int lastByteCapacity; // queue中,所有Event的header所能占用的最大空间占byteCapacity的比例 private volatile int byteCapacityBufferPercentage; // 用于标示byteCapacity中剩余空间的信号量 private Semaphore bytesRemaining; // 用于记录Memory Channel的一些指标,后面可以通过配置监控来观察Flume的运行情况 private ChannelCounter channelCounter;正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

