Android libcutils库中整数溢出导致的堆破坏漏洞的发现与利用
作者:龚广(@oldfresher)
阅读本文之前,您最好理解Android中的Binder机制、用于图形系统的BufferQueue原理、堆管理器je_malloc的基本原理。
此文介绍了如何利用libcutils库中的堆破坏漏洞获得system_server权限,此漏洞是研究Android图形子系统时发现的,对应的CVE号为CVE-2015-1474和CVE-2015-1528。
1.漏洞代码的位置
本文次涉及的漏洞位于创建native handle的函数,如下代码片段所示[1],每一个GraphicBuffer对象都包含一个native handle 的指针,通过native handle,GraphicBuffer可以跨进程共享图像系统所需的内存。
native_handle_t* native_handle_create(int numFds, int numInts) { native_handle_t* h = malloc( sizeof(native_handle_t) + sizeof(int)*(numFds+numInts));//---------->整数溢出位置 h->version = sizeof(native_handle_t); h->numFds = numFds; h->numInts = numInts; return h; } 当传入精心构造的numFds和numInts(如numFds=0xffffffff,numInts=2)到native_handle_create 时,可以导致表达式”sizeof( native_handle_t ) + sizeof(int)*( numFds + numInts )”整数溢出,接下来写分配的缓冲区h则会导致堆破坏。有两个函数会调用native_handle_create并写分配的堆内存导致堆破坏。其中有一个影响Android的所有版本,另一个只影响Android Lollipop以上的版本。
影响所有Android版本的函数如下[2]
status_t GraphicBuffer::unflatten( void const*& buffer, size_t& size, int const*& fds, size_t& count) { … native_handle* h = native_handle_create(numFds, numInts); memcpy(h->data, fds, numFds*sizeof(int)); // ------------>这里会导致堆破坏 memcpy(h->data + numFds, &buf[10], numInts*sizeof(int)); … } 当传入的numFds和numInts被恶意构造后,h分配的缓冲区小于预期的大小,后续的memcpy会导致堆破坏。只影响Lollipop以上版本的函数如下,这个函数在所有的Android版本中都存在,不过只在Android 5.0以上才会被调用,其它版本不能触发。
native_handle* Parcel::readNativeHandle() const { ... native_handle* h = native_handle_create(numFds, numInts); for (int i=0 ; err==NO_ERROR && i<numFds ; i++) { h->data[i] = dup(readFileDescriptor()); if (h->data[i] < 0) err = BAD_VALUE; } err = read(h->data + numFds, sizeof(int)*numInts); ----------------->堆破坏位置 ... return h; } read 函数类似与memcpy,后从Parcel中读取 sizeof ( int )* numInts 到h-> data + numFds ,因为分配给h的堆内存小于预期,所以read会导致堆破坏. 因为unflatten堆破坏时破坏的大小不好控制,我将使用这个函数来介绍此漏洞的利用。这个漏洞能被利用来提权的关键是numFds,numInts以及拷贝到native handle中的内容都可以被跨进程控制,从而使得低权限的进程可以注入代码到高权限进程而达到提权。
2.利用方法
如果A进程可以获得B进程的带IGraphicProducer接口的binder代理对象,那么A进程可以通过跨进程的binder调用利用此漏洞可获得B进程的权限。成功利用的关键函数是IGraphicProducer的setSidebandStream[4]函数。
case SET_SIDEBAND_STREAM: { CHECK_INTERFACE(IGraphicBufferProducer, data, reply); sp<NativeHandle> stream; if (data.readInt32()) { stream = NativeHandle::create(data.readNativeHandle(), true); } status_t result = setSidebandStream(stream); reply->writeInt32(result); return NO_ERROR; } break; 上述代码描述了 BnGraphicBufferProducer 如何处理其它进程发来的 SET_SIDEBAND_STREAM 事件,从代码中可以看到,从其他进程传来的parcel中的数据没有做任何检查,直接传给了 readNativeHandle ,从而导致numFds,numInts和其它被拷贝到所分配的堆内存的数据可以被发起binder调用的进程任意构造,使得利用成为可能。
下图是攻击场景图,低权限进程通过binder调用,利用此漏洞可获得高权限进程的权限:

Figure1. 攻击场景
3.如何获得system_server的权限
要获得system_server的权限需要分三步走,顺序不能乱:
第一步,从普通应用注入mediaserver。
第二步,从mediaserver注入surfaceflinger。
第三步,从surfaceflinger注入system_server.
必须按顺序注入是因为只有前一步成功了才能获得注入后续进程的权限,例如,只有拿下了mediaserver才能有权限访问surfaceflinger中的一些特殊接口,才有机会注入surfaceflinger

Figure2. SELinux domains
如上图所示,虽然surfaceflinger也是已系统用户运行的,但是因为SElinux的存在surfaceflinger是运行在u:r:surfaceflinger:s0域中,而此域除了访问图形设备外,其它的权限很少,这是为什么已经获得system用户权限后还要继续注入system_server的原因。system_server可以看在是Android的“内核“,可以访问的资源很多,如果把root权限比作神的,能注入system_server应该算是“半神“。下图描述了我们通过调用哪些接口,一步步的获得system_server的权限。
Figure 3. 三步走获得system_server权限
如上图所示,一个普通应用程序通过调用IMediaRecord的querySurfaceMediaSource函数能够获得mediaserver进程导出的IGraphicProducer,从而普通应用程序可以注入代码到mediaserver(详情见后续章节),因为mediaserver有ACCESS_SURFACE_FLINGER的权限,所以注入到mediaserver中的代码可以通过调用ISurfaceComposer的createSurface函数获得surfaceflinger导出的IGraphicProducer接口,然后同过setSidebandStream可以拿下surfaceflinger。surfaceflinger 通过调用IWindowsManager的screenShotApplication 触发system_server 调用 ISurfaceComposer captureScreen , 这个binder调用会将system_server 导出的一个 IGraphicProducer作为参数传给surfaceflinger,从而surfaceflinger可以获得system_server的IGraphicProducer接口,从而拿下system_server.
4.mediaserver注入详解
我们需要经过三步才能获得system_server的权限,但是由于NX,ASLR,SELinux,je_malloc和多个binder 服务线程相结合带来的障碍,每一步都很复杂,本节将以mediaserver为例详细介绍如何通过libutils的漏洞注入mediaserver. 简单来说,需要经过5步才能成功。
1)控制binder服务线程
当使用je_malloc时,每一个线程都与一个特定的arena关联,不同的线程从堆上分配内存时将使用不同的arena,每个arena又关联一个或多个chunk,故分配给不同的线程的小块堆内存将使用不同的chunk, Android中每个chunk的大小是1MB。图4展示了je_malloc堆的离散性。
Figure 4.je_malloc 中堆的分布
binder 服务线程处理binder代理发起的binder调用,服务线程的调用随着并行的binder调用的增加而增多,一般都有一个最大值。就mediaserver而言,进程刚启动时binder服务线程的数目是4,最多可以增加到17个,图5显示了mediaserver中binder服务线程最多时的状况.
Figure 5.mediaserver 的服务线程
当一个binder调用到达mediaserver时,系统会随机的选择一个服务线程来处理这个调用,而我们知道,不同的线程分配的堆内存位于不同的chunk中,所以,如果所有的线程都处于active状态时,通过binder调用分配的内存可能位于不同的chunk中,从而使得通过binder调用进行堆风水基本不可能。解决方法是只让一个binder服务线程处于active状态,挂起其余的所有binder服务线程,从而多次binder调用所分配的堆内存可以位于同一个chunk中。
IGraphicProducer接口可以通过attachBuffer函数将一个GraphicBuffer加入到bufferqueue.而每一个bufferqueue只能存储特定数量的GraphicBuffer, Lollipop中是64个,当bufferqueue中的GraphicBuffer已经达到64个后,如果还调用attachBuffer,处理attachBuffer的binder服务线程将会挂起,一直等到有bufferqueue中GraphicBuffer小于64为止,通过这种方法,可以挂起mediaserver中的16个binder线程,剩下的那个将服务我们发起的攻击性binder调用。
2) 泄漏堆的内容
因为ASLR的存在,要想利用次漏洞,我们需要从mediaserver中泄漏地址信息,在je_malloc中,同一个线程中分配的相同大小的小块内存将占据相邻的region(je_malloc中有对region的定义),与dl_malloc不用的是,相邻region之间没有任何元数据。我们可以通过attachBuffer在mediaserver的堆上生成很多的native handle, native handle的结构如下,native handle 的大小由numFds和numInts决定,正常的native handle中numFds=2,numInts=12,分配的堆的大小是80。
(gdb) pt native_handle_t
type = struct native_handle {
int version;
int numFds;
int numInts;
int data[4294967296];
}
我们先通过attachBuffer分配多个正常的native handle,然后通过setSidebandStream构造一个畸形的native handle(numFds=-35 ,numInt=64),readNativeHandle会将相邻的一个正常的native handle的numInts修改为较大的值, 当通过requestBuffer请求返回被修改的native handle 时,堆内容将会被泄漏。 
Figure 6. 从mediaserver中泄漏堆内容
3)泄漏栈的基地址
因为NX的存在,我们需要使用ROP来绕过NX,而ROP需要能控制栈内容,所有我们需要知道栈的位置。知道了栈的位置,我们可以通过此漏洞重写栈,从而可以将堆破坏漏洞转化为栈重写从而执行ROP。
我们已经知道如何泄漏堆的内容,所以我们可以在堆上搜索特定的数据结构来泄漏栈的基址。被搜索的关键数据结构为pthread_internal_t.
0xb652ec8c: 0xb424a080 0xb3b7c080 0x00000b58 0x00000a53
0xb652ec9c: 0xae8dcdb0 0x00000001 0xae7df000 0x000fe000
0xb652ecac: 0x00001000 0x00000000 0x00000000 0x00000000
0xb652ecbc: 0xb6e4700d 0xb3d48960 0x00000000 0xae7dd000
0xb652eccc: 0x00000001 0x00000000 0x00000000 0x00000000
0xb652ecdc: 0x00000000 0x00000000 0x00000000 0x00000000
上述地址范围是一个pthread_internal_t的内容,从彩色高亮的区域我们可以得知这个结构描述的线程的一些属性,tid 是 0xb58, pid 是 0xa53, 线程的栈的基址在0xae7df000. 因为这个结构中包含了线程的栈的基址,我们可以在泄漏的堆内存中搜索这样的结构来得到栈的基址。搜索的特征为栈大小(0x000fe000) 和guard_size(0x00001000)。每一个通过pthread_create创建出来的binder服务线程都会分配一个pthread_internal_t的对象,一般来说,新创建出来的线程会被分配一个较大的tid. 因为mediaserver中除了binder服务线程外还有别的线程,别的线程的状态不好控制,我们需要找到一个binder server线程对应的pthread_internal_t, 我们应该还记得binder server线程可以被动态触发创建的,这样就使得binder线程可以有一个较大的tid,我们可以搜索多个pthread_internal_t的对象,然后选择其中tid最大的一个,则有很大的概率这个线程是处于挂起状态的binder服务线程,处于挂起状态的binder服务线程的调用栈是固定的,如图7所示,我们可以通过重写它的返回地址来触发ROP的执行.
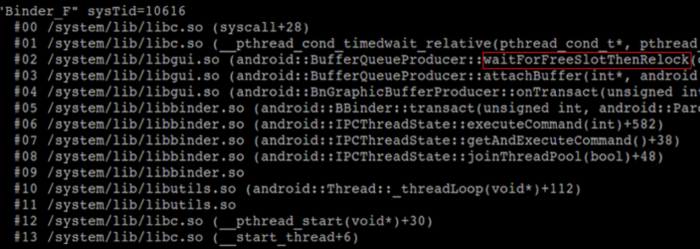
Figure 7. 处于阻塞状态的binder服务线程
4)泄漏共享库(so)基址
我们需要模块的基值来来构造ROP。为了有更多模块来搜索ROP,我们可能需要泄漏多个模块基址。泄漏libui.so的基址很容易。唯一需要做的是通过在泄漏的堆内存中搜索GraphicBuffer对象,GraphicBuffer对象包含一个 android_native_base_的子结构。这个结构中的incRef和decRef是指向libui.so中相应函数的函数指针。找到这个结构就能计算出libui.so的基址。GraphicBuffer具有特定特征,很容易搜索到。
(gdb) pt/m android_native_base_t
type = struct android_native_base_t {
int magic;
int version;
void *reserved[4];
void (*incRef)(android_native_base_t *);
void (*decRef)(android_native_base_t *);
}
为了比较方便的写shellcode,最好是能找到libc.so的基址,这样我们可以在shellcode中调用libc的函数,libui.so的GOT中有memcpy的地址,memcpy为libc.so中的函数,如果能泄漏libui.so的GOT表我们就能获得libc.so的基地址。由于这个漏洞的局限性,要泄漏libui.so的GOT并不容易。从前面章节得知,我们可以通过修改numFds和numInts来泄漏堆内存,但这中方法只能泄漏连续的内存,因为泄漏内存的的逻辑是memcpy,如果泄漏的地址空间中有没有被映射的内存,则memcpy直接会发生段错误。令一个限制是binder调用只能返回小于1MB的内存。堆内存和libui.so直接一般情况都存在没有映射的页面,而且两者直接的距离也超过了1MB,所以不能通过简单的修改numFds和numInts来泄漏libui.so的GOT。因为GraphicBuffer包含了native handle的指针,我们可以修改这个指针,使其指向一个伪造的native handle对象,则可以泄漏地址空间中紧跟这个native handle对象后的内存内容。泄漏的大小由伪造的numFds和numInts决定。通过这样的方法,我们同样可以泄漏libc.so的GOT,从而得到dlopen和dlsym的地址,有了这两个函数,我们可以直接用高级语言写shellcode.
5)控制je_malloc下次分配内存的位置
通过构造特殊的numFds和numInts,我们只能写紧临native handle的连续内存,因为je_malloc中栈和堆的地址空间通常不是相邻的。所有我们需要找到一个重写栈的方法,也就是将这个漏洞转换为一个任意地址写的漏洞。我们可以通过修改je_malloc中的tcache的指针表来实现. 当使用je_malloc并激活了tcache机制时,每一个线程都会为分配的小对象维护一个cache,这个cache存储在一个叫tcache_t的结构中。对每一种特定大小区间的对象,tcache_t都为其维护了一个指针表。在Android的je_malloc实现中,共有31大小区间。见下示gdb输出
(gdb) p je_small_bin2size_tab
$24 = {8, 16, 24, 32, 40, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320, 384, 448, 512, 640, 768, 896, 1024, 1280, 1536, 1792, 2048, 2560, 3072, 3584}
tcache的指针表存储在堆上,与其它通过malloc分配的堆内存混合在一起,所以通过构造numInts 和 numFds可以重写这些指针。下面所示的gdb输出为,分配大于112,小于等于128的内存时所使用的tcache指针表。当通过je_malloc分配一个位于此区间的对象时,从avail开始索引为ncached-1的指针将是je_malloc返回的指针,通过将这个值修改为栈地址,那么,下一次分配特定大小对象,栈地址将被返回,写被分配的对象内存是,栈将被重写。通过这种方法,我们可以控制栈内容来执行ROP。
(gdb) p je_arenas[0].tcache_ql.qlh_first.tbins[11]
$9 = {tstats = {nrequests = 17}, low_water = 62, lg_fill_div = 1, ncached = 63, avail = 0xb6003f60}
(gdb) x/63xw je_arenas[0].tcache_ql.qlh_first.tbins[11].avail
0xb6003f60: 0xb6057f80 0xb6057f00 0xb6057e80 0xb6057e00
0xb6003f70: 0xb6057d80 0xb6057d00 0xb6057c80 0xb6057c00
0xb6003f80: 0xb6057b80 0xb6057b00 0xb6057a80 0xb6057a00
0xb6003f90: 0xb6057980 0xb6057900 0xb6057880 0xb6057800
0xb6003fa0: 0xb6057780 0xb6057700 0xb6057680 0xb6057600
5.绕过SELinux加载so
因为SELinux的存在,普通应用创建的文件一般被标记为app_data_file 或 apk_data_file. mediaserver 没有权限执行带这些标签的文件. 所以不能在shellcode里使用system或dlopen执行普通应用提供的执行文件。幸运的是,mediaserver 有execmem 权限。
allow mediaserver self:process execmem; ————>SELinux policy
我们可以通过mprotect修改匿名内存为可执行(这在surfaceflinger中是不行的),从而能执行shellcode. 然后在shellcode里实现从内存中加载so的机制(详见PoC),从而带 app_data_file 或 apk_data_file的文件可以以二进制流的形式通过漏洞传给mediaserver,然后通过load so from memroy模块加载执行。
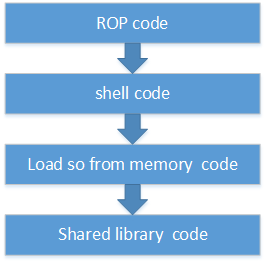
Figure 8. 加载共享库流程
因为mediaserver在Lollipop下没有执行/system/bin/sh的权限,我通过注入busybox到mediaserver来执行shell命令,如果利用成功,可以得到一个从mediaserver反弹的shell(如图9),细节请见PoC.

Figure 9. 带mediaserver权限的shell
6.溢出surfaceflinger和system_server
溢出surfaceflinger 和 system_server与注入mediaserver相似,不够有两点需要注意:
1.surfaceflinger 没有execmem权限,不能使用mprotect修改匿名内存为可执行,所有功能只能用RoP实现.
2.因为system_server和一般应用都是从Zygote fork出来的,模块地址一样,不需要泄漏system_server的模块基地址.
PoC 见https://github.com/secmob/PoCForCVE-2015-1528
[引用]
[1]http://androidxref.com/5.0.0_r2/xref/system/core/libcutils/native_handle.c#29
[2]http://androidxref.com/5.0.0_r2/xref/frameworks/native/libs/ui/GraphicBuffer.cpp#303
[3]http://androidxref.com/5.0.0_r2/xref/frameworks/native/libs/binder/Parcel.cpp#1210
[4]http://androidxref.com/5.0.0_r2/xref/frameworks/native/libs/gui/IGraphicBufferProducer.cpp#403
[5]http://www.phrack.org/issues/68/10.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

