使用Ajax long polling实现简单的聊天程序
关于web实时通信,通常使用长轮询或这长连接方式进行实现。
为了能够实际体会长轮询,通过Ajax长轮询实现了一个简单的聊天程序,在此作为笔记。
长轮询
传统的轮询方式是,客户端定时(一般使用setInterval)向服务器发送Ajax请求,服务器接到请求后马上返回响应信息。使用这种方式,无论客户端还是服务端都比较好实现,但是会有很多无用的请求(服务器没有有效数据的时候,也需要返回通知客户端)。
而长轮询是, 客户端向服务器发送Ajax请求,服务器接到请求后保持住连接,直到有新消息才返回响应信息,客户端处理完响应信息后再向服务器发送新的请求 。这样的好处就是,在没有数据的时候,客户端和服务器之间不会有无用的请求。
对于使用长轮询的实现,客户端和服务器都有一定的要求:
- 客户端发起请求,当接收到服务器响应(正常或异常的响应)后,需要向服务求发送新的请求,从而达到轮询的效果
- 服务器端要能够一直保持住客户端的请求,直到有响应消息;同时服务器对请求的处理要支持非阻塞模式
实现
例子很简单,客户端使用Ajax进行轮询请求,服务器端使用Python的gevent库来实现了非阻塞式的响应。
客户端
客户端实现了一个longPolling的函数,当文档加载完成后,就会调用这个longPolling函数。
注意Ajax请求的complete属性设置,每次当longPolling函数中的Ajax请求结束后,又会重新通过longPolling函数向服务器发出轮询请求。
function longPolling() { $.ajax({ url: "update", data: {"cursor": cursor}, type: "POST", error: function (XMLHttpRequest, textStatus, errorThrown) { $("#state").append("[state: " + textStatus + ", error: " + errorThrown + " ]<br/>"); }, success: function (result, textStatus) { msg_data = eval("(" + result + ")"); $("#inbox").append(msg_data.html); cursor = msg_data.latest_cursor; console.log(msg_data) $("#message").val(""); $("#state").append("[state: " + textStatus + " ]<br/>"); }, complete: longPolling }); }
服务端
服务器端通过MessageBuffer类来维护了一个cache(用list实现),用来存放所有来自客户端的消息。当消息的数量超过cache_size的时候,服务器会清理掉早期的消息。
class MessageBuffer(object): def __init__(self, cache_size = 200): self.cache = [] self.cache_size = cache_size self.message_event = Event()
由于Python自带的WSGI服务器是阻塞模式的,所以这里使用了gevent库中提供的非阻塞模式的WSGI服务器。
服务器的工作流程可以简单描述如下:
-
当服务器接收到客户端的数据请求时(/update)
- 如果存放消息cache为空,或者客户端已经得到了最新的消息(根据cursor这个GUID来判断),服务器阻塞(保持)该请求
- 服务器将所有有效的消息返回给客户端
- 当服务器接收到新的消息时(/new请求),服务器将新消息添加到cache中,并通过message_event事件来唤醒被阻塞的update请求
def application(env, start_response): # visit the main page if env['PATH_INFO'] == '/': return generate_response_data('200 OK', chat_html, start_response) # client to send a new message elif env['PATH_INFO'] == '/new': msg = escape(get_request_data("msg", env)) msg_item = {} msg_item["id"] = str(uuid.uuid4()) msg_item["msg"] = msg print "Got new message from client %s" %str(msg_item) messageBuffer.cache.append(msg_item) if len(messageBuffer.cache) > messageBuffer.cache_size: messageBuffer.cache = messageBuffer.cache[-messageBuffer.cache_size:] messageBuffer.message_event.set() messageBuffer.message_event.clear() return generate_response_data('200 OK', "", start_response) # serve to send available messages elif env['PATH_INFO'] == '/update': cursor = escape(get_request_data("cursor", env)) print "cursor: %s" %cursor # if message buffer is empty or no new messages, just wait if len(messageBuffer.cache) == 0 or messageBuffer.cache[-1]["id"] == cursor: messageBuffer.message_event.wait() for index, m in enumerate(messageBuffer.cache): if m['id'] == cursor: return generate_response_data('200 OK', generate_json_data(messageBuffer.cache[index + 1:]), start_response) return generate_response_data('200 OK', generate_json_data(messageBuffer.cache), start_response) else: return generate_response_data('404 Not Found', b'<h1>Not Found</h1>', start_response)
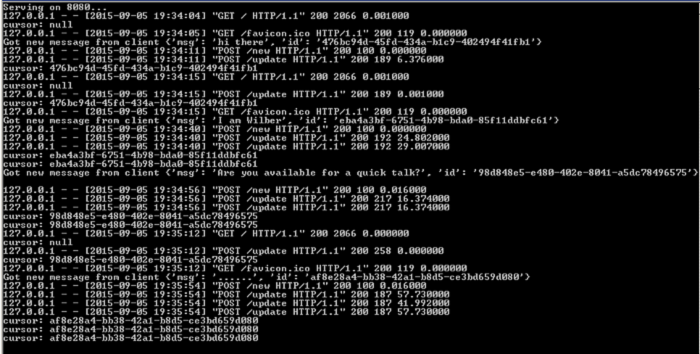
运行效果
通过下面两个图片可以看到运行效果。

长轮询也是长连接?
为了进一步看看长轮询的工作方式,基于上面的例子,通过wireshark抓取了一些数据包。
在服务器启动后,客户端发送了三条消息,并通过三次"/update"请求分别得到了这三条消息。
从截图中可以看到,三次请求并没有创建新的连接,而是重用了TCP连接;这是因为HTTP 1.1中会有一个"keep-alive"模式,服务器响应后并不会直接关闭TCP连接,而是看看客户端会不会有新的请求,从而重用已有的TCP连接。
对于客户端,由于每次收到消息后都会重新发送新的"/update"请求,所以可以一直重用TCP连接。
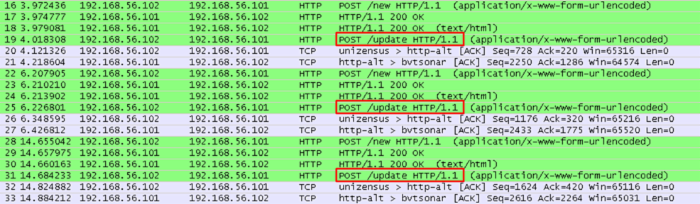
当客户端发出"/update"请求后,如果没有新的消息可以返回,服务器会一直保持这个请求。
为了保持住这条TCP连接,可以看到客户端会定期的发送"TCP Keep-Alive"包来维持TCP连接。

我的理解是,在使用HTTP的"keep-alive"模式中,长轮询中始终使用的是相同的TCP连接,其实这也是一种长连接方式。
总结
本文中,通过简单的例子试用了长轮询的方式来实现web实时通信。
长轮询的方式,使用起来相对容易,同时用能减少客户端和服务器之间的无用请求。
Ps:
通过此处可以下载例子的源码,需要安装Python和gevent才能正常运行。
正文到此结束
热门推荐










相关文章



Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

