集成学习基础通俗入门
【编者按】 集成建模是一种提高模型性能的强大方式。本文作为通俗入门教程,首先 通过一个例子快速引入集成学习的基础知识,介绍 如何真正得到不同的学习模块, 并着重 讨论了 几种在行业内广泛使用的集成技术,包括Bagging、Boosting、Stacking等。
导论
集成建模是一种提高模型性能的强大方式。在你可能构建的各种模型上使用集成学习通常卓有成效。一次又一次,人们在
Kaggle这样的比赛中使用集成模型,并且从中受益。
集成学习是一个广泛的话题,广到超出你的想象力。对于本文,我将涵盖集成建模的基本概念和思想。这应该足以让你在自己的机器上开始建立集成模型。像往常一样,我们试图让事情尽可能的简单。

让我们通过一个例子来快速了解集成学习的基础知识。这个例子将会带出我们每天是如何在毫无察觉的情况下使用集成学习的。
案例 :我想投资一家公司 XYZ。我还不知道它的业绩。所以我想有人给我些意见,看看这家公司的股票价格是否会每年增加6%以上。我打算与具有不同领域经验的专家交流。
1、 XYZ公司职员 :此人知道公司内部运作方式,并且知道该公司的内部消息。但是他并不了解竞争对手的创新情况,技术将如何发展,并且这种发展会对 XYZ公司产品有何影响。 在过去,他有70%的时候判断是正确的 。
2、 XYZ公司的财务顾问 :此人非常了解在激烈竞争环境下公司的战略将会得到怎样的效果。但是,他对公司内部政策会有何结果并不了解。 在过去,他有 75%的时候判断是正确的。
3、 股市操盘手 :此人过去三年一直在关注该公司的股票。他知道周期性趋势,以及整体股市的表现。他还形成了关于股票可能会如何随时间推移而变化的强烈直觉。 在过去,他有 70%的时候判断是正确的 。
4、 竞争对手的职员 :此人知道该竞争公司的内部运作方式,并且意识到已经发生的变化。他对公司缺乏焦点认识,并且对于竞争对手相关的外部因素认识不佳。 在过去,他有 60%的时候判断是正确的。
5、 同一领域的市场研究团队 :这个团队会分析 XYZ公司产品与其他公司产品的用户体验差异,并且这一情况随着时间如何改变。因为他们与客户打交道,并且基于他们自己的目标,他们不知道XYZ公司将会发生什么样的变化。 在过去,他们有 75%的时候判断是正确的。
6、 社交媒体专家 :此人可以帮助我们了解 XYZ公司对它们产品市场定位如何。并且了解随着时间推移客户对此公司看法如何。除了数字营销领域,其它领域的细节他不太关注。 在过去,他有 65%的时候判断是正确的。
通过各方面的了解,我们可以结合所有的信息,并作出明智的决定。
如果所有的6位专家/团队都认为这是个很好的决定(假设所有预测都是相互独立的),我们将得到组合准确率:
1 - 30%*25%*30%*40%*25%*35%
= 1 - 0.07875 = 99.92125%
假设:这里使用的所有预测是完全独立的假设略微极端,因为它们预期相关。但是,我们可以看出将不同预测结合起来我们会对问题有多大把握。
现在来改变下场景。这一次,我们有6个专家,它们都是 XYZ公司的员工,并且都在同一个部门工作。每个人都有差不多70%正确率。
如果我们将这些建议结合起来,还会得到99%以上的准确率吗?
很明显不会,因为这次的预测都是在相似的信息集上做出的。他们都会受到相似信息集的影响,并且他们建议中唯一的不同是每个人对公司有不同的看法。
停下来思考:你从这个案例中得到什么结论?是不是很深奥?在评论栏中写下你的看法。
什么是集成学习?
集成是结合不同的学习模块(单个模型)来加强模型的稳定性和预测能力。在上面的例子中,我们将所有预测结合在一起的方式被称为集成学习。
在这篇文章中,我们将讨论几种在行业内广泛使用的集成技术。在我们讲述技术之前,让我们先来了解如何真正得到不同的学习模块。模型会因为各种原因而彼此不同,从训练模型的样本数据集到模型的构造方法都会导致差异。
下面是导致模型不同的4个主要因素。这些因素的组合也可能会造成模型不同:
1、不同种类

2、不同假设

3、不同建模技术

4、初始化参数不同

集成建模中的误差(方差 vs偏置)
任何模型中出现的误差都可以在数学上分解成三个分量。如下:
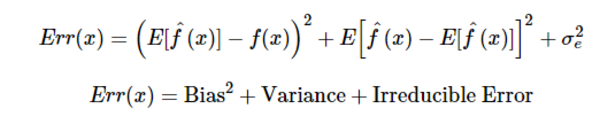
在目前的情况下这为什么很重要?为了了解集成模型背后发生的情况,我们首先要了解模型中是什么造成了误差。我们会简要介绍这些误差,然后对每一个集成学习模块进行分析。
偏置误差 是用来度量预测值与实际值差异的平均值,高偏置误差意味着我们的模型表现欠佳,不断丢失重要的趋势。
方差 则是度量基于同一观测值,预测值之间的差异。高方差模型在你的训练集上会过拟合,并且在训练之外的任何观察表现都不佳。下图会让你更明白(假设红点是真实值,蓝点是预测值):
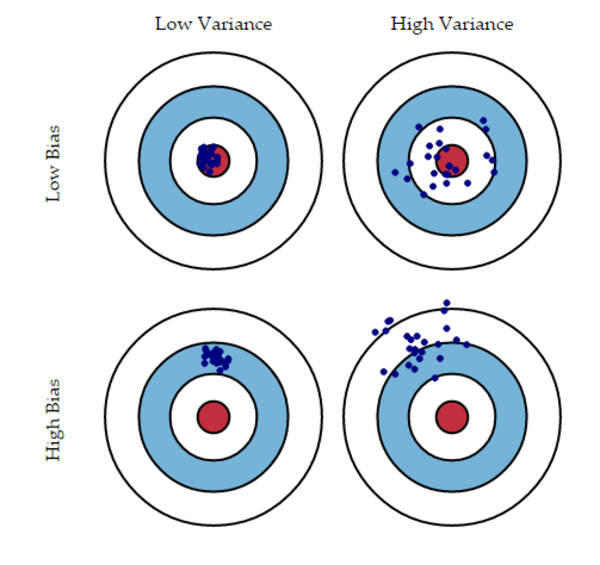
图自: Scott Fortman
通常情况下,当你增加模型的复杂性时,由于模型的低偏置,你会发现错误减少。但是,这只在某个特定点才发生。当你继续增加模型复杂性时,模型最终会过拟合,因此模型开始出现高方差。
一个优良的模型应该在这两种误差之间保持平衡。这被称为偏置方差的折衷管理。集成学习就是执行折衷权衡的一种方法。
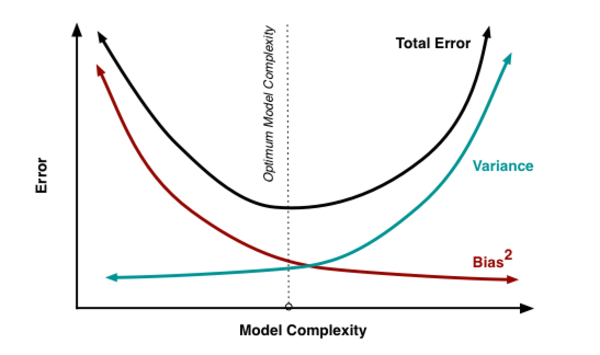
图自: Scott Fortman
一些常用的集成学习技术
1、 Bagging :Bagging试图在小样本集上实现相似的学习模块,然后对预测值求平均值。对于Bagging一般来说,你可以在不同数据集上使用不同学习模块。正如你所期望的那样,这样可以帮助我们减少方差。

2、 Boosting :Boosting是一项迭代技术,它在上一次分类的基础上调整观测值的权重。如果观测值被错误分类,它就会增加这个观测值的权重,反之亦然。Boosting一般会减少偏置误差然后构建强大的预测模型。但是,有些时候它们也会在训练数据上过拟合。

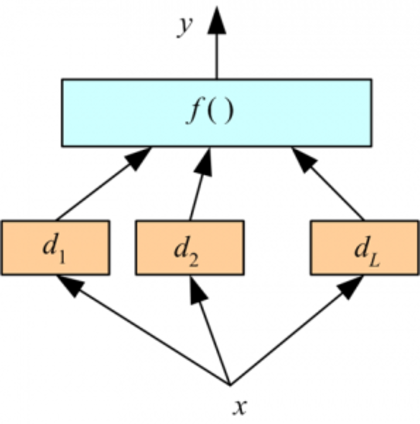
3、 Stacking :用它来结合模型是种有趣的方式。下面我们用一个学习模块与来自不同学习模块的输出结合起来。取决于我们使用的学习模块。这样做可以减少偏置误差和方差。
结束语
集成技术正被用于每一个 Kaggle 问题 之中。选择合适的集成模块与其说是纯粹的科研问题不如说是一种艺术。随着经验的积累,你可以根据不同的场景和基础学习模块使用不同的集成学习模块。
原文链接: Basics of Ensemble Learning Explained in Simple English (译者/刘翔宇 审校/赵屹华、朱正贵、李子健 责编/仲浩)
延伸阅读 : 集成学习:机器学习兵器谱的“屠龙刀”
1. 加入CSDN人工智能用户微信群,交流人工智能相关技术,请加微信号“jianding_zhou”或扫下方二维码,由工作人员加入。 请注明个人信息 并在入群后按此格式改群名片:机构名-技术方向-姓名/昵称 。
2. 加入CSDN 人工智能技术交流QQ群,请搜索群号加入:465538150。
3. CSDN高端专家微信群,采取受邀加入方式,不惧高门槛的请加微信号“jianding_zhou”或扫描下方二维码, PS:请务必带上你的BIO 。

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

