Swift中的集合类数据结构
原文链接: Collection Data Structures In Swift
原文日期:2015-04-21 Xcode 6.3 Swift 1.2
译者: Yake
校对: shanks
定稿: numbbbbb
假设你有一个需要处理许多数据的应用。你会把收据放在哪儿?你怎么样高效地组织并处理数据呢?
如果你的项目只处理一个数字,你把它存在一个变量中。如果有两个数字你就用两个变量。如果有1000个数字,10,000个字符串或者终极模因库呢(能马上找到一个完美的模因不是很好吗)?在那种情况下,你将会需要一种基本的集合类数据结构。幸运的是,这篇教程就是关于那个主题的。
下面是这篇教程的构成:
- 你将会复习什么是数据结构并学习大O符号。这是用来描述不同的数据结构性能的标准工具。
- 下一步:通过衡量arrays,disctionaries 以及 sets 这些 Cocoa 开发中最基本的数据结构的性能进行练习。同时这篇文章也会介绍一些基础的性能测试的方法。
- 继续学习,你将会比较成熟的 Cocoa 数据结构与对应的纯 Swift 结构的性能。
- 最后,你会简要地复习一下 Cocoa 中提供的一些相关类型。下面关于这些数据结构的内容可能让你很惊讶,但其实都是你常用的那些。

开始
在你深入探索iOS中使用的数据结构之前,你应该先复习一下他们是什么,以及怎么测量他们的性能这些基本的概念。
有许多集合类数据结构的类型,每一个都代表了一个特定的方法去组织并获取一个数据的集合。集合类型可能会使一些操作变得十分高效,例如添加新的数据,查找最小的数据以及保证不会重复添加数据。
没有集合数据类型,你将会陷入试图一个一个地管理数据的困境中。集合能够让你实现:
- 将所有的数据作为一个实体来处理
- 给他们设置一些结构
- 高效地插入、删除、并检索数据
什么是大O标记
大O,说的是字母O,而不是数字0,符号是一种描述某种数据结构上的某种操作的效率的方法。有很多种衡量效率的方法:你可以衡量这种数据结构消耗了多少内存,在最坏的情况下消耗的时间,它花费的平均时间是多少等等。
在这篇教程中,你将会衡量一种操作消耗的平均时长。
通常,大量的数据不会使得操作更快。大多数情况下是相反的,但有时候差别很小甚至没有差别。大O标记是一种描述这种情况的精确的方法。你能够写出一个具体的函数式来大概表示基于结构中数据的数量运行时间的变化情况。
当你看到大O标记被写作O(与n相关的函数),括号中的n就表示数据结构中数据的数量,而”与n相关的函数”则大约表示操作将要消耗的时间。
“大约”,确实有点讽刺,但是它有特定的含义:当n非常大时函数的渐进值。假设n是很大很大的数,当你将参数从n修改为n+1时,考虑一些操作的性能会怎样变化。
注意:这些都是算法复杂度分析中的一部分,如果你想深入探索的话,就多读些计算机科学类的书籍。你将不再束手无策,你会发现一些分析复杂度的数学方法,不同效率之间的微小差异,关于未知机器模型的更精细化的公式化的假设,以及更多其他你能想到或者想象不到的有趣的东西。
常见的大O性能测量如下:排列顺序是由最好的性能到到最差的性能
- O(1)(稳定的时间):无论数据结构中有多少数据,这个函数都调用同样数量的操作。这是理想的性能。
- O(log n)(对数级):这个函数调用的操作数量随着数据结构中的数据量对数级增长。这是很好的性能了,因为相比较数据结构中的数据的数量它的增长速度要慢得多。
- O(n)(线性):函数调用的操作数随着数据结构的数据量线性增长。这是较为合适的性能,但是如果是较大的数据集合就不合适了。
- O(n (log n)):这个函数调用操作的数量是由数据结构中的数据量的对数乘以数据结构中的数据量。可以预见的是,这是现实中对性能的最低容忍度。较大的数据结构会执行更多的操作,对于数据量较小的数据结构来说增长是较为合理的。
- O(n²)(平方):这个函数调用操作的数量是数据结构大小的平方 - 是差性能中最好的。即使你是在处理一些很小的数据结构它也会很快就变得特别慢。
- O(2^n)(指数):函数调用的操作数与数据结构是2的n次方的关系。这会导致很差的性能并很快就变得特别慢。
- O(n!) (阶乘):函数调用的操作数与数据结构之间是阶乘的关系。实际上,这是性能最差的情况。例如,在一个有100个数据的结构中,操作的数量的乘积是个158位的数。
下面是一个更直观的性能图。当集合中的数据量从1变化至25时,性能会怎么降低:
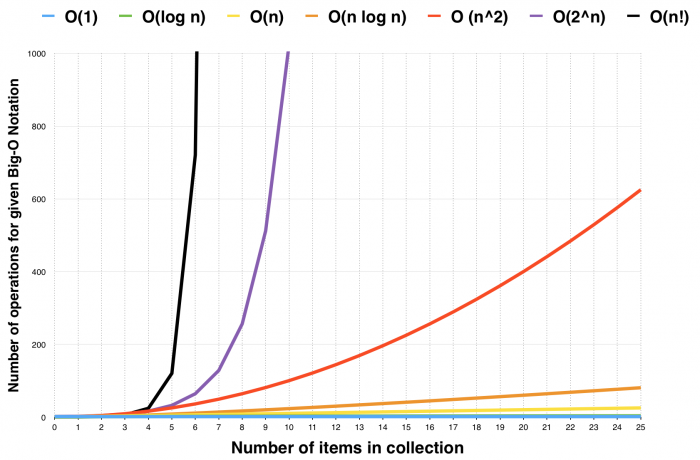
你有没有发现你几乎看不到绿色的O(log n)线?因为在这个范围内它几乎与理想中的O(1) 重合。那太好了!另一方面, O(n!)和O(2^n)标记的操作性能下降得特别快,当集合中有超过10个数据时操作的数量在图表中飙升了起来。是的!正如图表中清楚展示的,你处理的数据越多,选择正确的数据结构就越重要。
现在你已经知道怎么比较基于某种数据结构的数据操作的性能了。下面我们来复习一下iOS中最常用的三种数据类型以及他们在理论和实践中是如何发挥作用的。
常见iOS数据结构
iOS中三种最常用的数据结构是arrays,dictionaries 和 sets。首先你要考虑他们与作为基本抽象的完美类型的区别,然后你需要检查iOS提供的代表这些抽象的具体类的性能。(First you’ll consider how they differ in ideal terms as fundamental abstractions, and then you’ll examine the performance of the actual concrete classes which iOS offers for representing those abstractions.)首先你得从字面上去理解他们作为基本的抽象类型的区别,然后你需要检查在 iOS 中这些具体类表现的性能,从而知道 iOS 为啥提供这些抽象命名给它们。
对于这三种主要结构的类型来说,iOS 提供了多种具体的类来支持抽象的结构。除了在 Swift 和Objective-C 中旧的 Foundation 框架中的数据结构,现在又有了新的仅支持 Swift 版本的数据结构与语言紧密结合在一起。
Arrays
数组就是以一定顺序排列的一组数据,你可以通过索引来获取每一个数据元素,索引代表数据在排列中的位置。当你在数组变量名称后面的括号中写上索引时,这就叫做下标。
在 Swift 中,如果你用 let 将数组作为常量来定义,他们就是不可变的,如果用 var 定义为变量他们就是可变的。
作为对比,Foundation 框架中的 NSArray 默认是不可变类型,如果你想在数组创建之后添加、删除或者修改数据,你必须使用可变类 NSMuatbleArray 。
NSArray 是异质的,那也就意味着他可以包含不同类型的 Cocoa 对象。 Swift 数组是同质的,意味着每一个 Swift 数组都只包含一种类型的对象。
不过,你仍然可以通过将一个类型定义为 AnyObject 类型,使定义的 Swift 数组能够存储可变的 Cocoa 对象类型。
期望性能以及什么时候使用数组
使用数组来存储变量的一个首要原因是顺序能发挥重要作用。例如,你会通过名或者姓来排列联系人,按日期写一个计划列表,或者任何很需要通过某种顺序来查找或者展示数据的情形。
苹果的文档在 CFArray header 一篇中阐明了三种关键的预期:
- 在数组中通过一个特定的索引获取值的时间复杂度最坏是O(log n),但通常应该是O(1)。
- 搜索一个未知索引的对象的时间复杂度最坏是O(n (log n)),但一般应该是O(n)。
- 插入或者删除一个对象最坏的时间复杂度是O(n (log n)),但经常是O(1)。
这些保证了数组会基本如你在计算机科学的教材或者是C语言中那样,总是一段连续内存中的数据序列,是一种“理想型”数组。
将它作为一个有效的提醒去查看文档。
实际上,当你考虑下面这些的时候这些预期很有意义:
- 当你已经知道一个数据在哪儿并且需要查找时,那应该是很快的。
- 如果你不知道某个数据在哪儿,你可能需要将数组从头到尾遍历一遍,查找的过程可能会比较慢。
- 如果你知道要把某个数据添加到哪里或者从哪儿删除,那不是很困难,虽然后来你可能需要调整数组的剩余部分,那得花费些时间。
这些预期与现实是一致的吗?继续往下看:
示例App测试结果
从这篇教程中下载 示例项目 并在 Xcode 中打开。里面有些方法可以创建或者/并且测试数组,并且展示给你执行每个任务消耗的时间。
需要注意的是:在应用中,测试配置会自动将优化选项设置成和发布配置一样的选项。这样当你测试app的时候,你就能获得和真实环境一样的优化选项。
你需要至少1000个数据才可以用示例app进行测试。当你编译运行的时候,滑块会被设置到1000.点击 Create Array and Test 按钮,你将马上进入测试:

将滑块向右拖动直到数据达到10,000,000,再次按下 Create Array and Test 按钮,看看这个明显增大的数组的创建时间与刚才有什么不同:

这些测试是在 Xcode6.3(内含Swift1.2),iOS 8.3系统,iPhone6 模拟器上运行的。在数据增加了10,000倍的情况下,创建数组花费的时间只消耗了714倍。
O(n)函数意味着增加10,000倍的数据将会消耗10,000倍的时间,O(log n)函数意味着增加10,000倍的数据将会消耗4倍的时间。这个例子中的性能处于O(log n)和O(n)之间,这是相当稳定的。
这个过去一直都消耗了较长的时间。很久之前写的这篇教程的最初版本,是运行在Xcode6.0 Gold Master版(Swift6.0),iOS8 Gold Master版,iPhone5 上,测试消耗了相当长的时间:

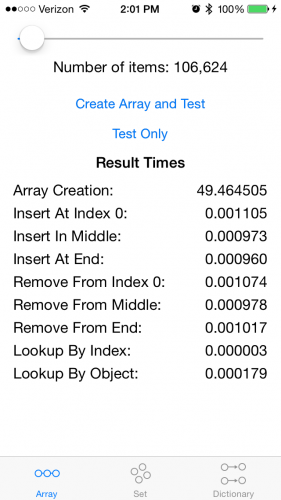
在这个例子中,大约106.5倍的数据,消耗了大约1,417倍的时间去创建数组。
如果要实现O(n)的性能,106.5倍的数据预期消耗时间应该是3.7秒。而以O(n log n)增长,预期消耗时间是33.5秒。以O(n²)增长,预期消耗时间395秒。
所以在这个例子中,Swift 中的 Array 的创建时间大约在O(n log n)和O(n²)之间。如你所见,当你的数据增加数十倍的时候时间消耗就过大了。
这个时间就不容乐观了。不过,更新至 Swift1.2 之后,你创建多大的数组都没有问题!
那么 NSMutableArray 呢?你仍然可以在 Swift 中调用 Foundation 的类而不需要使用 Objective-C ,你会发现还有一个Swift类叫做 NSArrayManipulator 遵守同样的协议 ArrayManipulator 。
正因如此,你可以轻松将 NSMutableArray 替换成 Swift 中的数组。项目代码很简单,你可以尝试修改一行来对比 NSMuatbleArray 的性能。
打开 ArrayViewController.swift 文件并将第27行由:
let arrayManipulator: ArrayManipulator = SwiftArrayManipulator()
修改为:
let arrayManipulator: ArrayManipulator = NSArrayManipulator()
再次编译运行,点击 Create Array and Test 测试有1000个数据的 NSMutableArray 数组的创建:

然后再次修改数据为10,000,000:
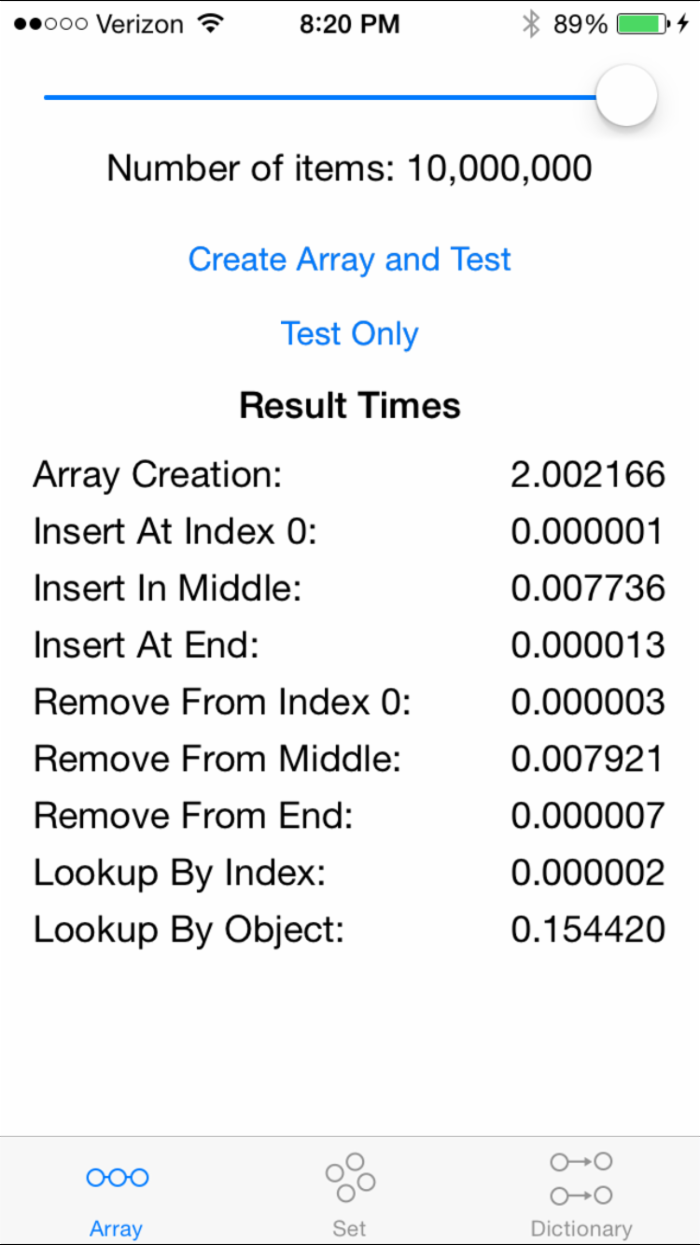
创建操作原始的性能不如 Swift1.2 中的好 - 虽然一部分可能是因为需要在那些可以存储在 NSArray 中和他们对应的Swift的类型中的对象之间来回操作。
不管怎样,你创建一个数组只需要一次 - 但是需要经常执行的是其他一些操作例如查找,添加,或者是移除对象。
在更深入的测试中,例如当你使用 Xcode6 中的一些性能测试方法分别调用每一个方法50次,一种模式就开始呈现了:
- 创建一个 Swift 数组和 NSArray 数组消耗相同的时间 - 介于O(log n)和O(n)之间。而至于拥有5,000到25,000个数据的数组,Swift 比 Foundation 花费大约三倍的时间 - 但是都低于0.02秒。
- 在 Swift 中向一个数组结构的对象的开始或者是中间添加数据,相对于 Foundation 中(大约在O(1)左右)是慢很多的。向 Swift 数组的结尾添加数据(时间少于O(1))实际上比向 NSArray 的结尾添加数据(多于O(1))要快。
- 在 Foundation 和 Swift 数组结构中移除对象操作的性能表现是很相似的:从开头,之间,或者结尾移除一个对象时间大约在O(log n)和O(n)之间。从数组的开头移除数据这一操作在Swift中性能略差,但是时间差异是毫秒级的。
- 通过索引查找所消耗的时间在Swift数组以及
NSArray中以相同的速率增长。当你通过索引查找数据,数组很大时,Swift 数组消耗的时间相比使用 NSMutableArray 类型的对象快将近10倍。
注意:你可以在 iPhone6性能测试 电子表格程序中获得将每个方法运行50次的结果(环境:Xcode 6.3 已发布版本,Swift 1.2,iOS 8.3系统,iPhone6)。你也可以尝试运行应用中包含的测试看看每运行10次的平均结果,以及他们在你手机上是如何运行的。
字典
字典是一种不需要特定的顺序且数据都与唯一的键相联系的储值方式。你可以使用键来存储或者是查询一个值。
字典也使用下标语法。当你写 dictionary["hello"] ,你就会得到与键 hello 对应的值。
像数组一样,在 Swift 中你如果用 let 来声明字典它就是个常量,如果用 var
来声明它就是可变的。在 Foundation 框架方面也是类似的,有 NSDictionary 和 NSMutableDictionary 两种类型供你使用。
与 Swift 数组相似的另外一个特征就是字典也是强类型的(即对于程序里的每一个变量,在使用前必须声明类型,赋值的时候也必须与变量的类型相同),你必须有已知类型的键值对。 NSDictionary 类型的对象可以以任何 NSObject 的子类对象作为 key ,可以存储任意类型的对象为值。
当你调用某个使用或者返回一个字典类型的 Cocoa 的 API 时,你就会看到它在实际中的样子。在 Swift 中,这个类型以 [NSObject: AnyObject] 这种形式来描述。也就是说这个类型必须以 NSObject 的子类作为键,而值可以是任何兼容 Swift 的对象。
什么时候使用字典
当你要存储的数据没有特定的顺序,而又有某种意义上的关联的时候,字典是最好的选择。
为了帮你检验字典以及这篇教程中其他的数据结构是如何工作的,通过 File…/New/Playground 创建一个 Playground ,并把它命名为 DataStructures。
例如,你需要存储一个数据结构,他们包含了你所有的朋友以及他们的猫的名字,这样你就可以通过你朋友的名字查找他们的猫的名字。这样一来,你就不需要记住猫的名字以获得朋友的亲睐。
首先,你需要存储朋友和猫的字典:
let cats = [ "Ellen" : "Chaplin", "Lilia" : "George Michael", "Rose" : "Friend", "Bettina" : "Pai Mei"]
由于 Swift 的类型推断,上述类型被定义为 [String: String] - 键值均为字符串类型的字典。
现在尝试在里面获取数据:
cats["Ellen"] //returns Chaplin as an optional
cats["Steve"] //Returns nil
注意字典中的下标语法返回一个可选类型。如果字典中不包含某个特定键的值,可选类型为 nil ;如果包含那个键对应的值,你就可以将其解包获取值。
这样一来,使用 if let 可选类型解包语法从字典中获取值就是个很不错的办法:
if let ellensCat = cats["Ellen"] {
println("Ellen's cat is named /(ellensCat).")
} else {
println("Ellen's cat's name not found!")
}
由于确实存在 ‘Ellen’ 对应的值,你的 playground 中就会打印 ‘Ellen’s cat is named Chaplin’ 。
预期的性能
苹果再一次在 Cocoa 的 CFDictionary.h 头文件中概括了字典的期望性能:
1.从字典中获取值的时间复杂度最坏是 O(n) ,但一般应该是 O(1) 。
2.插入和删除数据的时间复杂度最坏是 O(n²) ,但由于顶层的优化通常更接近 O(1) 。
这些没有数组中的性能表现那样明显。由于存储键值对相较于一个有序的数组有更复杂的本质,所以性能不那么好预测。
示例程序测试结果
DictionaryManipulator 是跟 ArrayManipulator 类似的一个协议,它可以测试字典。你可以用它测试Swift Dictionary 和 NSMutableDictionary 在执行相同的操作时的性能。
为了比较 Swift 和 Cocoa 字典,你可以使用与上述数组的测试程序相似的步骤。编译运行app,选择底部的 Dictionary 标签。
运行几个测试程序 - 你会发现创建一个字典比创建数组消耗的时间要长得多。如果你把数据滑块滑到10,000,000的位置,你可能会收到内存警告甚至内存溢出崩溃!
回到 Xcode 中,打开 DictionaryViewController.swift 文件并找到 dictionaryManipulator 属性:
let dictionaryManipulator: DictionaryManipulator = SwiftDictionaryManipulator()
用下面的代码替换它:
let dictionaryManipulator: DictionaryManipulator = NSDictionaryManipulator()
现在应用底层将会使用 NSDictionary 。再次编译运行app,多进行几次测试。如果你是在 Swift1.2 上运行的,你的发现可能与一些扩展测试中的发现相一致:
- 在时间消耗上来看,创建 Swift 字典比创建
NSMutableDictionaries要慢得多 - 但性能都以O(n)的速率降低。 - 向 Swift 字典中添加数据的时间比向
NSMutableDictionaries类型的对象中添加数据大约快3倍,并且性能如苹果的文档中保证的那样,最好能达到O(1)的速率。 - Swift 和 Foundation 的字典都能以大约
O(1)的速率进行查找。不像 Swift 数组,字典并不比 Foundation 中的字典性能要好,但是他们非常得接近。
现在,进入 iOS 中最后一个主要的数据结构:集合!
集合
集合是一种存储无序的,值唯一的数据结构。当你向一个集合中添加同样的数据时,数据不会被添加。这里的“同样地”即满足方法 isEqual() 。
Swift 在1.2版本中添加了对原生 Set 类型的支持 - 早期的Swift版本,你只能获取 Foundation 框架下的 NSSet 类型。Swift 集合中的元素,也必须拥有相同的类型。
注意,就像数组和字典那样,对于一个原生的 Swift 集合来说,如果你用 let 关键字进行声明它就是常量,如果用 var 声明就是可变的。在 Foundation 方面,也都有 NSSet 和 NSMutableSet 供你使用。
什么时候使用集合
当数据的唯一性很重要而顺序无所谓时可以使用集合。例如,如果你想从八个名字的数组中随机选出四个名字并且没有重复时,你会选择什么呢?
在你的 Playground 中输入下面的代码:
let names = ["John", "Paul", "George", "Ringo", "Mick", "Keith", "Charlie", "Ronnie"]
var stringSet = Set<String>() // 1
var loopsCount = 0
while stringSet.count < 4 {
let randomNumber = arc4random_uniform(UInt32(count(names))) //2
let randomName = names[Int(randomNumber)] //3
println(randomName) //4
stringSet.insert(randomName) //5
++loopsCount //6
}
//7
println("Loops: " + loopsCount.description + ", Set contents: " + stringSet.description)
在这一小段代码中,你在做下面的事情:
1.初始化集合,这样你就可以在里面添加数据。
2.在0和名字的个数中间选一个随机值。
3.获取所选数字为索引对应的名字。
4.打印出选择的名字。
5.将选择的名字添加至可变的集合。记住,如果名字已经在集合里面了,集合就不会变化,因为集合不会存储重复的数据。
6.loop计数器一直在增加,这样你就可以看到循环执行了多少次。
7.一旦循环结束,打印loop计数器的值和可变集合中的内容。
在这个例子中我们使用了一个随机数字生成器,你每次都能获取到一个不同的结果。下面的示例是写这篇教程时的其中一次运行结果:
John
Ringo
John
Ronnie
Ronnie
George
Loops: 6, Set contents: ["Ronnie", "John", "Ringo", "George"]
在这儿,为了得到唯一的名字循环执行了6次。它分别选择了 Ronnie 和 John 两次,但是只在集合中添加了一次。
当你在 playground 中写下这个循环时,你会注意到它一遍一遍地执行,每次循环你都会得到一个不同的数字。每次运行都至少有四次循环,因此集合中必须有四个数据才能跳出循环。
现在你已经看到了一个较小的集合是怎样工作的,下面我们来看看存储较大数据量的集合的性能。
示例应用测试结果
不像数组和字典,苹果没有概括集合性能的大概的预期(Swift集合文档中对几个方法的性能有预期描述,但是没有 NSMutableSet 对应的预期),所以在这里你只需要观察实际情况中的性能。
Swift1.2 版本的示例项目在 SetViewController 类中有 NSSetManipulator 和 SwiftSetManipulator 对象,这与 Array 和 Dictionary 的视图控制器中的配置类似,并且也可以以同样地方式进行替换。
在这两种情况下,如果你追求纯粹的速度,使用 Set 可能不能令你满意。 Set 和 NSSet 相较于 Array 和 NSMutableArray ,你会发现集合的时间要慢得多 - 这就是你为了检查每一个数据在数据结构中是否是唯一所付出的代价。
进一步的测试显示由于 Swift 的集合相对于数组和字典来说,处理数据花费的时间要多一些,他的性能以及执行大多数操作所消耗的时间都与 NSSet 非常的相似:创建,移除,以及查找操作对于 Foundation 和 Swift 来说消耗的时间几乎是相同的。
在 Swift 和 Foundation 中创建一个集合类型的对象消耗时间大约都以 O(n) 增长 - 这与预期相符,因为集合中的每一个数据被添加进来之前都要检查是否与已有数据相等。
在 Swift 和 Foundation 中删除和查找操作的性能大约是 O(1) 。这种情况是很稳定的,因为集合结构使用哈希值来检查是否相等,而哈希值可以以某个顺序进行计算和存储。这就使得查找操作明显比数组中的查找要快。
NSMutableSet 和 Swift 原生的 Set 性能上主要的差异在于添加对象的操作。
总之,向一个 NSSet 中添加对象时间复杂度约为 O(1) ,而在 Swift 的 Set 结构下可能就高于 O(n) 了。
Swift 在它短暂的公众生涯中,已经在集合类数据结构的性能方面有了很大的提升,并且随着 Swift 的进化还有可能继续看到他们的变化。
鲜为人知的 Foundation 数据结构
数组,字典和集合肩负着数据处理的重任。然而,Cocoa 提供了许多了解的人很少甚至不被欣赏的集合类型。如果字典,数组,集合都不能胜任某个功能,那么你可以试试这些是否管用。
NSCache
使用 NSCache 与使用 NSMutableDictionary 是类似的 - 就是通过键来添加和获取值。区别在于 NSCache 是用来暂时存储一些你总是可以重新计算和生成的东西。如果可用内存降低, NSCache 可能会移除一些对象。他们是线程安全的,但是苹果的文档提示:
如果缓存被要求释放内存,它就会自动执行异步的更新操作。
从根本上说, NSCache 和 NSMutableDictionary 很像,除了 NSCache 可以在你的代码没有做任何事情的时候从另一个线程中移除一些对象。这对于管理缓存所使用的内存来说是很好的,但是如果你试图使用一个突然消失的对象,那么就会出问题了。
NSCache 对键采取弱引用而不是强引用。
NSCountedSet
NSCountedSet 可以检测到你向某个集合中添加某个对象操作执行的次数。它继承自 NSMutableSet ,所以如果你再次向集合中添加同样的对象,集合中也只会有一个那样的对象。
不管怎样,在一个 NSCountedSet 类型的对象中,集合记录下对象被添加了多少次。你可以通过 countForObject() 查看某个对象被添加的次数。
注意当你调用 NSMutableSet 的 count 属性时,它只返回唯一对象的数量,而不是所有被添加到集合中的元素的数量。
例如,在你的 Playground 中,使用你之前做 NSMutableSet 的测试时,创建的数组的名字,将每个名字都向 NSCountedSet 对象中添加两次。
let countedMutable = NSCountedSet()
for name in names {
countedMutable.addObject(name)
countedMutable.addObject(name)
}
然后,打印集合,看看“Ringo”被添加了多少次:
let ringos = countedMutable.countForObject("Ringo")
println("Counted Mutable set: /(countedMutable)) with count for Ringo: /(ringos)")
你的打印结果应该是:
Counted Mutable set: {(
George,
John,
Ronnie,
Mick,
Keith,
Charlie,
Paul,
Ringo
)}) with count for Ringo: 2
注意集合中元素的顺序可能不同,但是你应该看到“Ringo”在名字列表中出现了一次,即使你看到它是被添加了两次的。
NSOrderedSet
NSOrderedSet 以及它对应的可变类型 NSMutableOrderedSet ,是一种允许你以特定顺序存储一组不重复的对象的数据结构。
“特定顺序” - 天哪,这听起来很像数组对不对?苹果简单总结了你为什么会使用 NSOrderedSet 而不是数组:
当元素顺序以及测试某个元素是否存在于集合中的性能需要被考虑在内时,你可以使用有序的集合作为数组的备选项。
因此,当你需要存储一组有序的数据而数据又不能重复时使用 NSOrderedSet 是最好的。
注意:由于 NSCountedSet 继承自 NSMutableSet ,因此 NSOrderedSet 也继承自 NSObject 。这个例子很好地表明了苹果命名一个类是基于他们的功能,而不一定是基于他们在底层是如何工作的。
NSHashTable and NSMapTable
NSHashTable 是另外一种与集合类似的数据结构,但是与 NSMutableSet 有几处关键的不同之处。
你可以使用任意指针类型而不仅仅是对象来搭建一个 NSHashTable 类型对象,所以你可以向 NSHashTable 中添加结构体和非对象类型的数据。你也可以使用 NSHashTableOptions 枚举值来设置内存管理和相等的条件等。
NSMapTable 是一种类字典的数据结构,但是在内存管理方面与 NSHashTable 有着相似的行为。
像 NSCache 那样, NSMapTable 对键是弱引用。然而,不管什么时候键被释放它都能够自动删除与那个键对应的数据。这些选项都可以在 NSMapTableOptions 枚举值中进行设置。
NSIndexSet
NSIndexSet 是一个不可变的集合,用来存储唯一的无符号整数,来表示数组的索引值。
如果你有一个拥有十个数据的数组,而你通常需要使用其中某几个固定位置的数据,你就可以将索引存储在 NSIndexSet 对象中,并使用 NSArray 的 objectsAtIndexes 来直接获取那些对象:
let items : NSArray = ["one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"]
let indexSet = NSMutableIndexSet()
indexSet.addIndex(3)
indexSet.addIndex(8)
indexSet.addIndex(9)
items.objectsAtIndexes(indexSet) // returns ["four", "nine", "ten"]
你所指定的某个“数据”现在是一个数组了,Swift 数组没有对应的方法可以通过 NSIndexSet 或者别的什么类来获取多个数据。
NSIndexSet 保留了 NSSet 中只允许某个值出现一次的特性。因此,你不能用它来存储任意一组数据,除非这组数据没有重复值。
有了 NSIndexSet ,你就可以将索引按一定的顺序存储,这比仅仅存储一个整数数组效率更高。
小测试
已经学到了这里,下面这个小测试是关于你想用哪种数据结构来存储某种类型的数据的,你可以通过小测试来检测你的记忆。
为了做下面的测试,假设你有一个可以在图书馆展示数据的应用程序。
Q:你会用什么来创建图书馆中所有作者的列表?
答案:集合!它会自动移除重复的数据,也就是说你可以任意输入作者的名字,多少次都可以,但是你只会有一次录入 - 除非你输错了作者的名字!
Q:你怎么按字母排序的方式存储一个多产作者的所有作品的标题?
答案:用数组!这种情况下你有许多相似的数据对象(所有的标题都是字符串类型的),并且他们有顺序(标题必须按照字母顺序排列),这绝对是使用数组的最佳场景。
Q:你怎样存储每个作者最受欢迎的作品?
答案:字典!如果你使用作者的名字作为键,使用作者最受欢迎的作品为值,你可以以下面的方式获取这个作者最受欢迎的作品:
mostPopularBooks["Gillian Flynn"] //Returns "Gone Girl"
扩展阅读
我想特别感谢我的一个同事 Chris Wagner ,在我们接触到 Swift 之前他写了这篇教程的 OC 版本,为了可以使用他的笔记和示例项目,把那篇教程也放在这里。
我也要感谢苹果公司的 Swift 团队 - 尽管在原生的数据结构方面还有很大的提升空间,我已经很享受用 Swift 编码和测试了。一段时间内我可能还会使用 Foundation 下的数据结构,但也可能开发一些 Swift 小插件。
不管怎样,如果你想学习更多 iOS 的数据结构,这儿有一些很棒的资源:
- NSHipster 是一个很棒的资源,可以让你去探索Cocoa的包括数据结构在内的一些鲜为人知的API。
- PSPDFKit 公司的Peter Steinberger的最著名的关于Foundation 数据结构的 excellent article in ObjC.io issue 7 。
- 前任UIKit工程师Andy Matuschak的一篇关于 Swift 中基于结构的数据结构的文章 article in ObjC.io issue 16 。
- AirspeedVelocity ,一个研究Swift本质特征的博客 - 由于在标题中引用了Monty Python的台词而获得了加分(Monty Python 1975年有一个电影 叫 Monty Python and the Holy Grail,里面有一个角色叫bridgekeeper ,他有一句台词:What… is the air-speed velocity of an unladen swallow? )。
- 一篇很棒的文章 deep dive into the internals of NSMutableArray 深入研究了
NSMutableArray,以及修改NSMutableArray中的数据对内存的影响。 - 一篇关于 NSArray and CFArray performance changes with extremely large data sets 很棒的研究。这篇文章进一步证明了苹果对类的命名并不是基于类在后台的行为,而是他们于开发者的行为。
- 如果你想学习更多的算法复杂度分析 Introduction to Algorithms 会教你比你在实际应用中可能了解到的还要多的内容,但能使你顺利通过工作面试。
如果你想仔细分析呈现在这篇文章中的数据,你可以自己下载 the numbers spreadsheet used to track all the testing runs with Swift 1.2 分析数据。
更多问题或者想进一步分析数据的话,在下面尽情地留言吧!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

