Docker Registry V1 与 V2 的区别解析以及灵雀云的实时同步迁移实践
今年四月份,随着 Docker registry 2.0 把版本的发布,之前 Python 版本实现的 registry 正式被标记为 ‘deprecated’。V2 版本用 go 实现,在安全性和性能上做了诸多优化,并重新设计了镜像的存储的格式,带来了翻天覆地的变化。本文详细解读了 V2 和 V1 的区别并介绍灵雀云在生产环境同时支持 V1 和 V2 的镜像同步迁移实践以及利用该同步系统对 docker hub 镜像实现实时同步的方法。
背景
Registry 作为 Docker 的核心组件之一负责镜像内容的存储与分发,客户端的 docker pull 以及 push 命令都将直接与 registry 进行交互。最初版本的 registry 由 Python实现。由于设计初期在安全性,性能以及 API 的设计上有着诸多的缺陷,该版本在 0.9 之后停止了开发,新的项目 distribution 来重新设计并开发下一代 registry。新的项目由 go 语言开发,所有的 API,底层存储方式,系统架构都进行了全面的重新设计已解决上一代 registry 中存在的问题。四月份 rgistry 2.0 正式发布,docker 1.6 版本开始支持 registry 2.0, 八月份随着 docker 1.8 发布,docker hub 正式启用 2.1 版本 registry 全面替代之前版本 registry。
新版 registry 对镜像存储格式进行了重新设计并和旧版不兼容,docker 1.5 和之前的版本无法读取 2.0 的镜像。同时旧版本的 registry 中已有大量的镜像需要迁移到新版本 registry 中。在 灵雀云平台 的客户可能会使用各个版本的 docker,也可能升级或者降级使用的版本。为了让 registry 的版本对用户透明,灵雀云在同一域名提供两套服务的基础上在后台对镜像实现了新版和旧版的双向实时同步,以保证用户在切换客户端版本时不会出现 pull 镜像失败的情况。在此基础上,灵雀云实现了对 docker hub 中官方 library 镜像到灵雀云平台的实时同步,通过灵雀云的国内 镜像社区 来为国内用户提供快速的镜像下载服务。
Registry V2 的变化
镜像 id 改进
Docker build 镜像时会为每个 layer 生成一串 layer id,这个 layer id 是一个客户端随机生成的字符串,和镜像内容无关。我们可以通过一个简单的例子来查看。
这里选择官方的 nginx dockerfile 来 build 镜像
docker build -t nginx:dockerfile . 
接下来重新 build 该镜像,加上 --no-cache 强制重新 build
docker build --no-cache=true -t nginx:dockerfile . 
可以看到除了基础镜像 debian 的两层 layer id 一致,其余 layer 的 id 都发生了变化。这种随机 layer id 以及 layer id 与内容无关的设计会带来很多的问题。
首先, registry v1 通过 id 来判断镜像是否存在,客户需不需要重新 push,而由于镜像内容和 id 无关,再重新 build 后 layer 在内容不变的情况下很可能 id 发生变化,造成无法利用 registry 中已有 layer 反复 push 相同内容。服务器端也会有重复存储造成空间浪费。
其次,尽管 id 由 32 字节组成但是依然存在 id 碰撞的可能,在存在相同 id 的情况下,后一个 layer 由于 id 和仓库中已有 layer 相同无法被 push 到 registry 中,导致数据的丢失。用户也可以通过这个方法来探测某个 id 是否存在。
最后,同样是由于这个原因如果程序恶意伪造大量 layer push 到 registry 中占位会导致新的 layer 无法被 push 到 registry 中。
Docker 官方重新设计新版 registry 的一个主要原因也就是为了解决该问题。
新版的 registry 吸取了旧版的教训,在服务器端会对镜像内容进行哈希,通过内容的哈希值来判断 layer 在 registry 中是否存在,是否需要重新传输。这个新版本中的哈希值被称为 digest 是一个和镜像内容相关的字符串,相同的内容会生成相同的 digest。
由于 digest 和内容相关,因此只要重新 build 的内容相同理论上讲无需重新 push,但是由于安全性的考量在特定情况下 layer 依然要重新传输。由于 layer 是按 digest 进行存储,相对 v1 按照随机 id 存储可以大幅减小磁盘空间占用。registry 服务端会对冲突 digest 进一步进行处理,同时由于 digest 是由 registry 服务端生成,用户无法伪造 digest 也很大程度上保证了 registry 内容的安全性。
安全性改进
除了对 image 内容进行唯一性哈希外,新版 registry 还在鉴权方式以及 layer 权限上上进行了大幅度调整。
鉴权方式
旧版本的服务鉴权模型如下图所示:
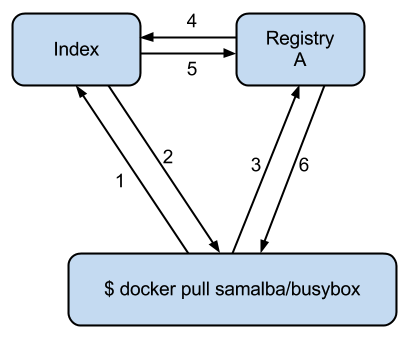
该模型每次 client 端和 registry 的交互都要多次和 index 打交道,新版本的鉴权模型去除了上图中的第四第五步,如下图所示:
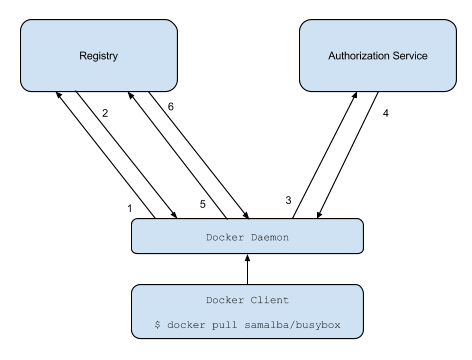
新版本的鉴权模型需要 registry 和 authorization service 在部署时分别配置好彼此的信息,并将对方信息作为生成 token 的字符串,已减少后续的交互操作。新模型客户端只需要和 authorization service 进行一次交互获得对应 token 即可和 registry 进行交互,减少了复杂的流程。同时 registry 和 authorization service 一一对应的方式也降低了被攻击的可能。
权限控制
旧版的 registry 中对 layer 没有任何权限控制,所有的权限相关内容都由 index 完成。在新版 registry 中加入了对 layer 的权限控制,每个 layer 都有一个 manifest 来标识该 layer 由哪些 repository 共享,将权限做到 repository 级别。
Pull 性能改进
旧版 registry 中镜像的每个 layer 都包含一个 ancestry 的 json 文件包含了父亲 layer 的信息,因此当我们 pull 镜像时需要串行下载,下载完一个 layer 后才知道下一个 layer 的 id 是多少再去下载。如下图所示:
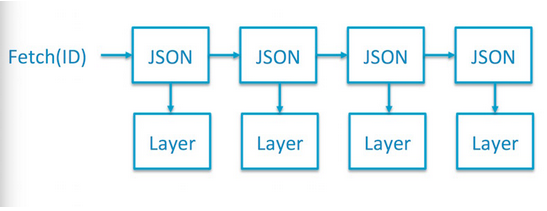
新版 registry 在 image 的 manifest 中包含了所有 layer 的信息,客户端可以并行下载所有的 layer 如下图所示:

其他改进
- 全新的 API
- push 和 pull 支持断点
- 后端存储的插件化
- notification 机制
灵雀云的双向实时同步实践
灵雀云 上有大量用户 push 到 v1 版本的镜像,迁移到 v2 需要对存量进行迁移。同时每天通过用户 push 和自动构建还会产生大量新的镜像,为了能够让用户对后端 registry 无感知可以任意选择 docker client 的版本,我们实现了镜像在 V1 和 V2 两个 registry 的实时同步。
官方方案及其缺陷
docker 官方最近开源了一个新项目 migirator ,提供了一种从 V1 向 V2 迁移的方案。该方案的依赖基础是 docker 1.6 版本可以同时支持 V1 和 V2 的协议,通过 V1 中的 list api 获取 registry 中已有的镜像从 V1 pull 镜像 push 到 V2。该项目提供了一个 shell 脚本用户通过配置不同版本 registry 的 endpoint 来自动进行同步。
灵雀云在该项目公布前已经完成了迁移和同步相关的操作,简要说一下该方案的缺陷:
- 该方案只适合离线同步,如果平台一直对外提供服务不断有新的镜像 push,该方案最终无法收敛。
- 该方案是个单机模型,当 registry 中存量镜像很多时该方法耗时不可接受。
- 只是一个单向迁移方案,双向同时同步会出现乱序导致新镜像被旧镜像覆盖的情况。
- 只是一个简单的 demo 产品,缺乏错误检测和监控统计相关功能。
灵雀云的镜像双向实时同步
在灵雀云的同步中,我们和 migirator 使用了相同的同步基础,利用 docker 1.6 后版本同时支持两个版本 registry 的特性,进行 pull 和 push 达到同步的目的。
对于实时的镜像 push,我们捕获每一次 push 成功的信息生成同步任务发送到 rabbitmq 队列中。对于存量镜像,我们一次性获得所有当前 V1 仓库中的所有镜像,并以相同的任务格式插入到 rabbitmq 队列之中。
为了应对存量及实时数据过多,单机同步时间过长的问题,我们将同步的任务分散到多台节点。在 rabbitmq 层面我们将每个同步任务按照 namespace/repository/image 进行哈希分散到多个队列之中。后端每个工作节点监听一部分队列,只对队列内的同步任务进行同步。由于每个 image 都会在一个队列中按序执行,这样保证了同步的顺序,不会出现新的镜像被旧镜像覆盖的情况。这样任务被合理的分散到多台机器。
同时我们会将每个同步任务的状态记录到数据库中,方便统计整体的同步状况,每个任务的执行情况。我们对任务的格式进行了适度的抽象使得这套同步机制可以灵活运用于其他类型的同步,下面要介绍的官方镜像同步就利用到了这套同步系统。
官方镜像实时同步
Docker 官方的镜像市场 dockerhub 搭建在 AWS 之上,由于国内网络的原因下载镜像速度很慢且连接不稳定,很容易出现失败的情况。现在国内常用的做法是通过 mirror registry 来进行加速,但是这种方式也存在着一定的缺陷。
首先通过 mirror registry 下载镜像时客户端会去 docker hub 校验当前镜像,这一步依然存在网络不稳定的情况,有一定的失败概率。其次 mirror registry 中只能保存用户已下载过的镜像,一些不常用镜像下载依然很慢,此外 docker hub 的镜像更新很频繁,mirror 很容易失效。为了方便国内用户能够方便的使用已有镜像,我们希望用上面的同步系统将 docker hub 官方 library 中的镜像以及大家较常用的 tutum 镜像实时同步到国内灵雀云的镜像社区,使得国内用户不用忍受网络阻塞带来的痛苦。目前灵雀云镜像社区的 library 和 tutum 仓库实时和官方 docker hub 进行同步,目前在官方镜像更新后数分钟后灵雀云社区的镜像就可以更新。
上述 registry 迁移同步的系统可以直接应用到官方镜像社区和灵雀云镜像社区的同步,但是由于网络原因,直接使用这种方法同步效率极低,且极易失败,如何克服网络障碍成为了问题的关键。由于实时同步肯定是同步最新生成的镜像,所以 mirror 的方式并不实用。vpn 的方式由于本身国际带宽就有限,且 vpn 很容易被动态识别而被干扰在进行大数据传输的过程中表现十分不稳定,无法达到很好的时效性。土豪的话其实一根专线就可以了,但是我们希望能以更经济的形式解决这个问题。
我们采用了曲线救国的方式来完成实时同步,首先在海外下载镜像,在国外的环境可以高速的下载镜像。接下来通过底层存储级别的同步技术将存储内容实时同步到国内的机器上。最后再从国内的机器将镜像 push 到灵雀云的镜像社区中。通过这种曲线救国的方式,我们将同步的延迟控制在分钟级别,可以满足绝大多数用户对最官方新镜像的需求。希望通过我们的努力可以使用户更方便快捷的下载并使用到想用的镜像
Docker-Registry
Docker Distribution Roadmap
Docker Registry v2 authentication via central service
Docker Registry HTTP API V2
Docker migirator
作者简介: 刘梦馨, 灵雀云 软件工程师,从事CaaS平台的研发工作。从事过开发、测试、运维相关职位,专注于云计算和虚拟化技术。个人博客 http://oilbeater.com。 (责编/魏伟)正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

