爬虫: 零编程将网页转换为JSON
爬虫: 零编程将网页转换为JSON
2015年 九月
1) 你肯定写过爬虫
我也写过。我的第一个爬虫是 Java 写的自动签到机,在公司上班的时候帮了我不少忙,每天都可以睡到自然醒而不用被扣工资。
直到有一天老板来到了我们办公室,而那时候我还在家里的床上。
2) 你肯定写过不止一个爬虫
好巧,我也是。第二个爬虫是用来追踪姑娘在虾米上的听歌历史,一旦发现有新的条目,立马就把歌曲播放给我(后来发现虾米好像出的有一个什么「跟听」)。
这个 是用 Python 写的,一直用的很好,直到有一天我受够了它播放给我的曲子。
3) 你肯定不只写过两个爬虫
我也是。我写的第三个爬虫花费了不到 10 个小时的时间,还带着一个地图界面。 它 把 V2EX 上的 招聘帖子 抽取过来分析一下然后转化成 JSON,再分地域展示到高德地图上。
感觉很叼的样子,然而并没有什么卵人用,每天的访问量小于 2,还要减去我的那个访问。
4) 有没有觉得有些不对劲
我感觉到了(广告要来了)。
写个爬虫并不是很难,但也会花费你不少时间,最后可能还没个卵用。
你还要选个语言 ,然后选个包(抽取网页啦、DOM解析啦),然后开始写。
然后调试、测试然后天就黑了,是时候改变一下啦。
5) 好了,下面是解决方案
我创建了一个项目 cl-spider 。现在它提供两个方法,主要是以 URI 、 CSS SELECTORS 以及 HTML ATTRIBUTES 为参数,然后返回给你想要的数据,比如:
(cl-spider:get-data "https://news.ycombinator.com/" :selector "a" :attrs '("href" "text"))
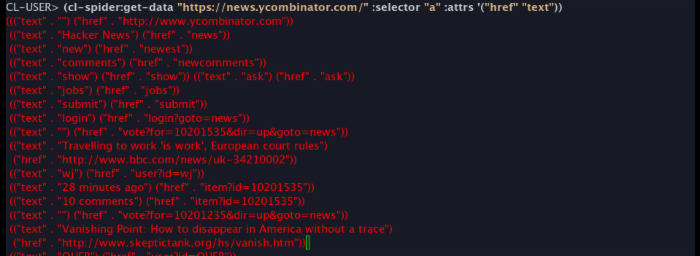
"然而这有个卵用,我不用 Lisp。"
- 杰克·派森王
"太废物了,JSON 呢?"
- 洛斯·爪哇娜
6) 额,真正的解决方案
由于现在用 Lisp 的人不多,我就又创建了一个项目叫 such-cute ,它是 cl-spider 的一个网络接口。
用 such-cute ,你就可以不用触碰 Lisp 代码了,直接用 http 调用就可以返回 JSON 数据:
http://localhost:5000/get?uri=https://news.ycombinator.com/&selector=a&attrs=["href","text"]
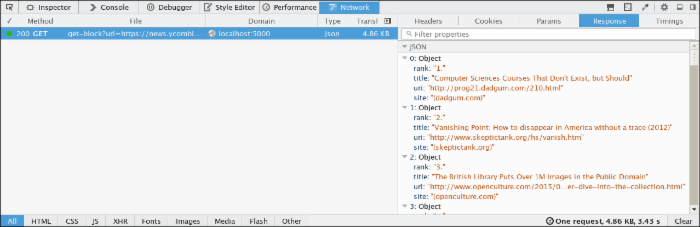
你只需要按照 指示 搭建一个 such-cute 服务。
"不 不 不 不 不,别想让我碰 Lisp。"
- 雷曼·菲普尔
"这太愚蠢了!我还得弄个 Common Lisp 运行环境?"
- 格斯塔夫·鲍斯尔
"算了,我要点叉了。"
- 西蒙·麦内格
7) 算了,就当我什么也没说
点击下面链接:
http://sc.vitovan.com/get?uri=http://v2ex.com/&selector=a&attrs=["href","text"]
然后看这个: http://vitovan.github.io/such-cute/
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

